
jboss 5.0.1GA一小时后性能下降和奇怪的GC行为
我们将我们的软件从JBoss4.0.5GA升级到5.0.1GA,并注意到在大约一个小时后(或在某些情况下,90分钟)性能急剧下降。
同时,垃圾收集器日志显示少量垃圾收集次数从0.01s跳到~1.5s,每次清除堆的数量从400 of减少到300 of之后。(见GC查看器图1)
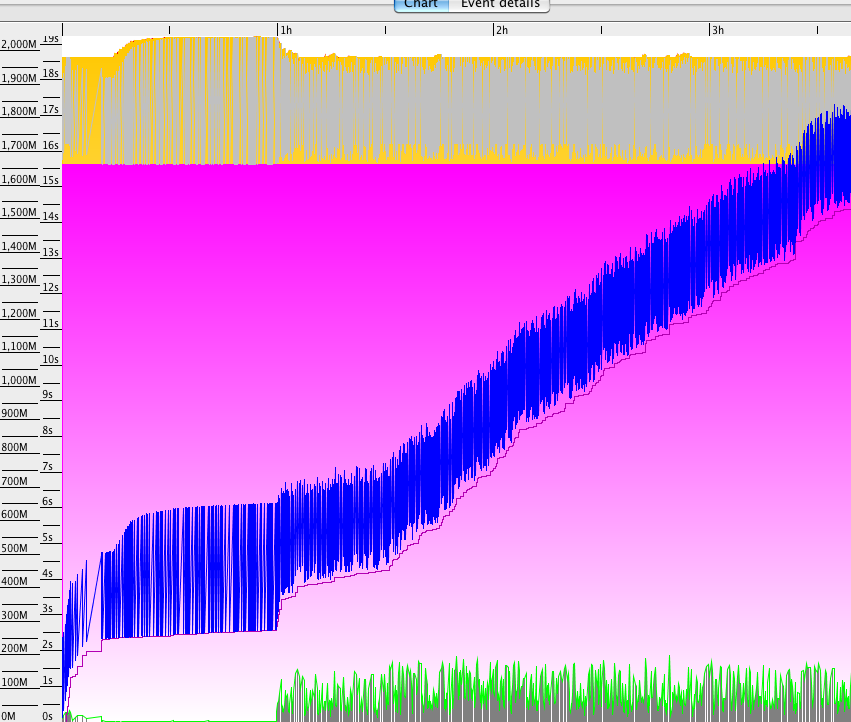
我们认为这两种症状的根本原因是相同的。
jvm设置如下:
-server -Xms2048m -Xmx2048m -XX:NewSize=384m -XX:MaxNewSize=384m
-XX:SurvivorRatio=4 -XX:MinHeapFreeRatio=11 -XX:PermSize=80m -verbose:gc
-XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+DisableExplicitGC
-Djava.awt.headless=TRUE -DUseSunHttpHandler=TRUE
-Dsun.net.client.defaultConnectTimeout=25000
-Dsun.net.client.defaultReadTimeout=50000 -Dfile.encoding=UTF-8
-Dvzzv.log.dir=${ercorebatch.log.dir} -Xloggc:${ercorebatch.log.dir}/gc.log
-Duser.language=it -Duser.region=IT -Duser.country=IT -DVFjavaWL=er.core.it生产环境是T5220或T2000硬件,32位SPARC运行Solaris 10虚拟机。jboss 5.0.1.GA,java 1.6.0_17
我们建立了一个测试环境,由两个相同的机箱组成,运行相同的软件,其中一个使用jboss 4.0.5GA,另一个使用jboss 5.0.1.GA,它们是运行在一个带有4x2.2GHz英特尔Xeon E5-4620和64 HP内存的HP ProLiant DL560 Gen8上的VMs。客户VM为4 vCPU,4096 VMs,CentOS 6.4。
我们发现我们可以很容易地在我们的环境中再现这个问题。运行在4.0.5的盒子运行良好,但在JBoss5.0.1GA上,我们看到了同样奇怪的GC行为。性能在我们的环境中是很难测试的,因为我们的负载和生产负载不一样。
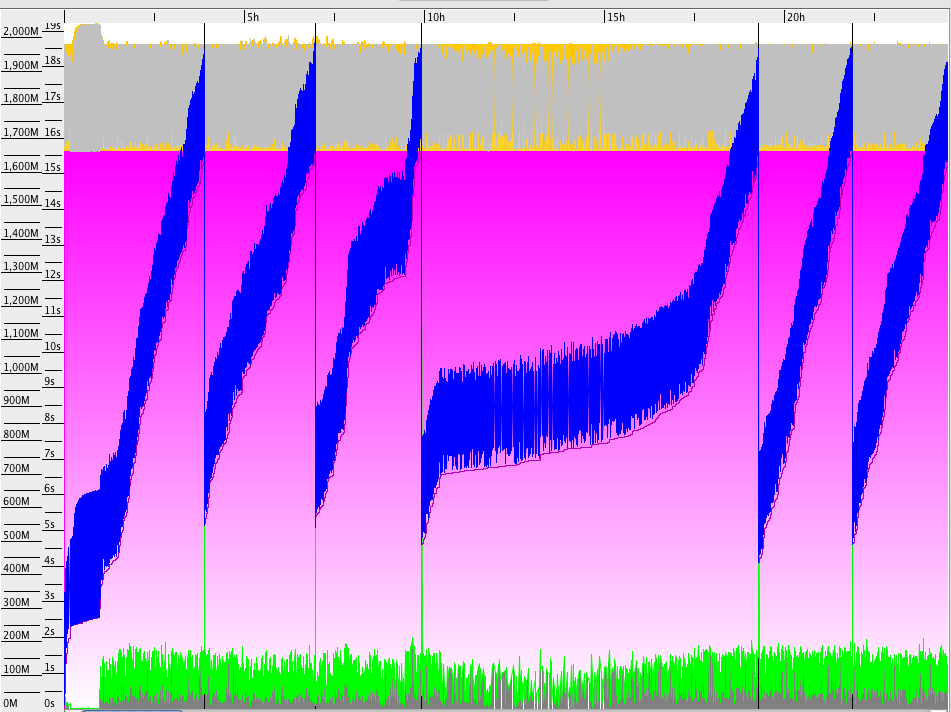
我们不认为这是内存泄漏,因为在每个主要GC之后,使用的堆大小返回到相同大小:
通过分析启示录前后的堆转储,我们发现以下对象的数量是不同的:
org.jboss.virtual.plugins.context.file.FileSystemContext
在第一个小时,大约有8个,在天启之后,我们看到100到800之间。
除此之外,堆转储看起来非常相似,顶部的对象要么是java对象,要么是jboss对象(即没有应用程序类)。
在我们的测试环境中设置-Djboss.vfs.forceVfsJar=true解决了问题(即奇怪的GC行为消失了),但是在生产中应用时,奇怪的GC模式和性能问题仍然存在--尽管GC时间并没有增加太多(达到0.3秒而不是1.5秒)。
在我们的测试环境中,我们在JBoss5.1.0中部署了相同的软件,并发现了与5.0.1相同的行为。
因此,目前的结论是,JBoss5.x在60 / 90分钟的时间内发生了一些事情,这对垃圾收集和性能都有影响。
更新:
我们尝试将web服务堆栈升级到jbossws-本机-3.3.1,这解决了我们测试环境中的问题。然而,当部署到下一个测试环境(更接近生产环境)时,问题仍然存在(尽管减少了)。
更新:
我们已经解决了这一问题,将jboss.vfs.cache.TimedPolicyCaching.lifetime设置为非常大的数量,相当于许多年。
对于jboss中的一个bug来说,这就像是一个解决方案。默认的缓存生存期为30分钟(请参见org.jboss.util.TimedCachePolicy),我们在60或90分钟后都看到了问题。
VFS缓存实现是CombinedVFSCache,我认为它在下面使用一个TimedVFSCache。
似乎更好的解决方法是将缓存实现更改为永久缓存,但是我们已经在这个问题上浪费了足够的时间,我们的解决方案将不得不这样做。
回答 1
Stack Overflow用户
发布于 2013-08-17 07:23:32
仅仅看Gc图就很难确定这个问题的根本原因。那么,当这种情况发生时,堆叠会是什么样子呢?有超活跃线程吗?是否有任何令人讨厌的线程创建了大量的对象,迫使垃圾收集器拼命工作以摆脱它们?我认为必须进行更多的分析,以确定问题的根源。
https://stackoverflow.com/questions/18273375
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号