
使用Server ROW_NUMBER()分页的性能较差
我正试图建立一个分页机制。我使用的ORM创建了如下所示的SQL:
SELECT * FROM
(SELECT t1.colX, t2.colY
ROW_NUMBER() OVER (ORDER BY t1.col3) AS row
FROM Table1 t1
INNER JOIN Table2 t2
ON t1.col1=t2.col2
)a
WHERE row >= n AND row <= mTable1有>500 k行,Table2有>10k记录
我直接在Server 2008 R2 Management中执行查询。子查询需要2-3秒才能执行,但整个查询需要>2分钟。
我知道Server 2012接受OFFSET .. LIMIT ..选项,但我不能升级该软件。
有谁能帮助我提高查询的性能,或者建议其他可以通过ORM软件强加的分页机制。
Update:
测试罗曼·皮卡尔的解决方案(请参阅解决方案的注释)证明,ROW_NUMBER()可能不是导致性能问题的原因。不幸的是,问题仍然存在。
谢谢
回答 3
Stack Overflow用户
发布于 2013-08-08 10:21:34
我从评论中了解你的表格结构。
create table Table2
(
col2 int identity primary key,
colY int
)
create table Table1
(
col3 int identity primary key,
col1 int not null references Table2(col2),
colX int
)这意味着从Table1返回的行永远不会被连接到Table2中过滤,因为Table1.col1是not null。Table2的联接也不能向结果添加行,因为Table2.Col2是主键。
然后,您可以重写查询,在连接到Table1之前在Table2上生成行号。在联接到Table2之前还应用where子句,这意味着您将只在Table2中定位实际上是结果集一部分的行。
select T1.colX,
T2.colY,
T1.row
from
(
select col1,
colX,
row_number() over(order by col3) as row
from Table1
) as T1
inner join Table2 as T2
on T1.col1 = T2.col2
where row >= @n and row <= @m我不知道您是否可以让ORM ()像这样生成分页查询,而不是现在的样子。
此答案的查询计划:
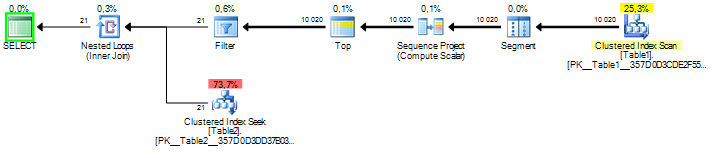
使用问题中的查询的查询计划:
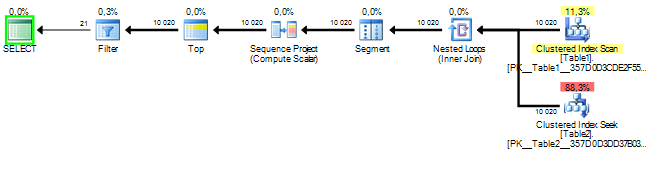
两者在阅读方面有很大的不同。

Stack Overflow用户
发布于 2013-08-05 16:15:54
仅将分页表的主键列插入具有标识列的临时表中,并按有序-按列排序。(您可能必须包括ordered列,以确保排序结果正确。)然后,使用temp表作为您想要的行的键,返回到主表。如果数据是相当静态的,您可以将排序数据保存到一个按会话键的永久表中,而不是临时表,并将其重用一段短时间(因此,随后几分钟内的页面请求几乎是即时的)。
Row_Number()在处理小数据集时往往表现良好,但一旦得到一些严重的行,就会遇到严重的性能障碍,就像500 K一样。
Stack Overflow用户
发布于 2013-08-05 17:48:06
我建议你检查一下表上的索引。我认为,如果您至少在col2上有table2上的索引,这将对您的查询有所帮助。您也可以尝试重写查询,例如
;with cte1 as (
select top (@m) t1.colX, t2.colY, t1.col3
from Table1 as t1
inner join Table2 as t2 on t1.col1=t2.col2
order by t1.col3 asc
),
cte2 as (
select top (@m - @n + 1) *
from cte1
order by col3 desc
)
select *
from cte2 as t1但是如果你没有索引的话,它可能会很慢。
https://stackoverflow.com/questions/18062243
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号