
Hbase方案设计-最佳做法
我最近从rdbms转到Hbase来处理数百万条记录。但是作为一个新手,我不知道设计Hbase方案的有效方法是什么。实际上,假设我有文本文件,这些文本文件有上百万条记录,我必须读取这些文件并存储到Hbase中。因此,有两组文本文件(RawData文件、Label文件),它们彼此链接,因为它们属于同一个用户,对于这些文件,我创建了两个独立的表(RawData和Label),并将它们的信息存储在那里。因此,RawData文件和RawData表如下所示:
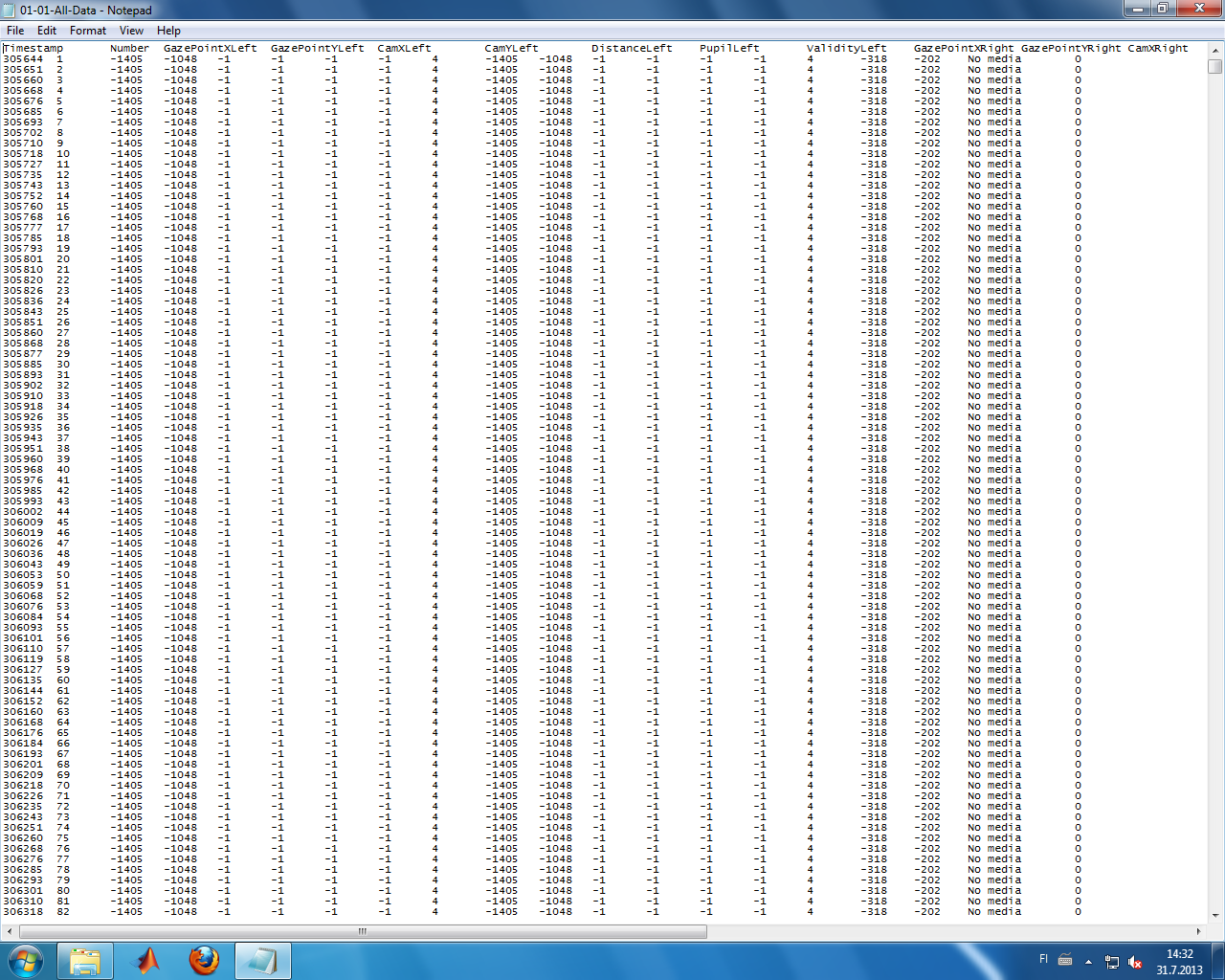
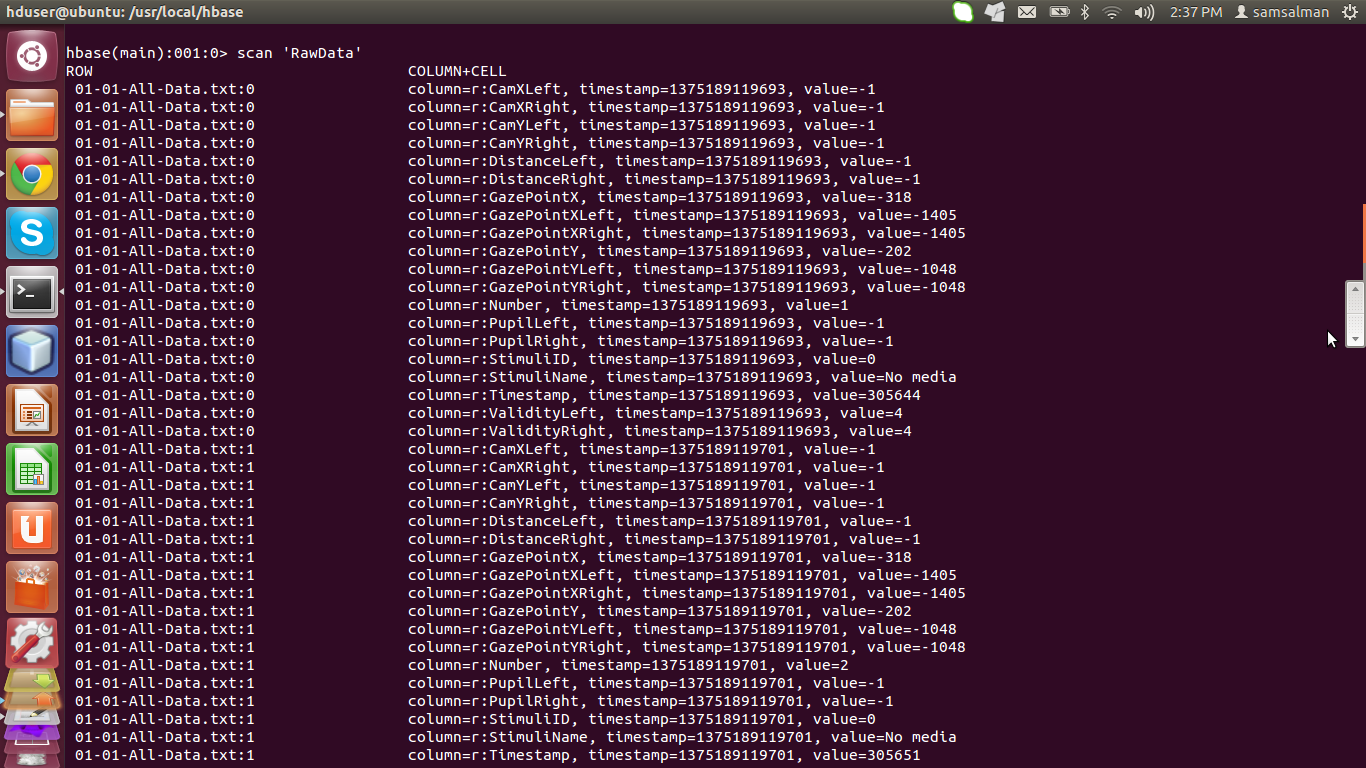
所以您可以在我的RawData表中看到,我有行键,它实际上是文本文件的文件名( 01-01-All-Data.txt),其中包含每一行文本文件的行号。列族只是随机的'r‘,列限定符是文本文件的列,值是列的值。这就是我如何在表中插入记录的方法,在第三个表(MapFile)中,我将文本文件的名称存储为行键,用户的用户id作为列限定符,文本文件的记录总数作为值存储,如下所示:
01-01-All-Data.txt column=m:1, timestamp=1375189274467, value=146209 我将使用Mapfile表逐行读取RawData表。
你对这种Hbase模式有什么建议?这是个合适的方法吗?还是在Hbase的概念里没有意义?
此外,值得一提的是,在Hbase中插入有146207行的21个mbs文件大约需要3分钟。
请指点。
谢谢
回答 1
Stack Overflow用户
发布于 2013-07-31 15:24:05
虽然我没有发现当前模式有什么问题,但只有在分析了用例和频繁访问模式之后,才能确定是否是合适的。正确并不总是合适的,IMHO。由于我对这一切一无所知,我的建议听起来可能不正确。如果是这样的话,请告诉我。我会相应地更新答案。开始吧,
是否有意义(记住数据和访问模式)只有一个表有3列族:
- RD -对于具有此文件所有列的RawData文件
- LF -用于标签文件和该文件的所有列,以及
- MF -用于有一列保存文本文件记录数量的MapFile。
使用userid作为行键。它将是独特的,看起来不会很长。使用此设计,您可以绕过从一个表到另一个表的分流开销,同时获取数据。
很少有更多的建议:
- 如果用户是单调增加的,那么散列您的行键,这样您就不会受到RegionServer Hotspotting的困扰。
- 还可以创建pre-splitted表以获得更好的分发。
- 如果可能,缩短列名。
- 尽量减少版本的数量。
此外,值得一提的是,在hbse.中插入包含146207行的21个mbs文件需要大约3分钟时间。
您如何插入您的数据?MapReduce还是普通的Java+HBAse API?您的集群大小是多少?配置和规范?
您可能会发现这些链接很有用:
- 拉尔斯写的美丽的维德。
- 关于架构设计的正式文档。
- 模式设计演示文稿HBaseCon-2012
HTH
https://stackoverflow.com/questions/17969951
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号