
使用pugixml解释程序的内存消耗
我有一个程序,它解析一个大约50 of的XML文件,并将数据提取到一个内部对象结构中,而没有与原始XML文件的链接。当我试图粗略估计我需要多少内存时,我估计需要40 to。
但是我的程序需要像350 my这样的东西,我试着找出发生了什么。我使用boost::shared_ptr,所以我不处理原始指针,希望没有产生内存泄漏。
我试着写我所做的事情,我希望有人在我的过程中指出问题,错误的假设等等。
首先,我是怎么测量的?我使用htop来发现我的内存是满的,使用我的代码的进程使用的最多。为了总结不同线程的内存并获得更好的输出,我使用了mem.py,这证实了我的观察。
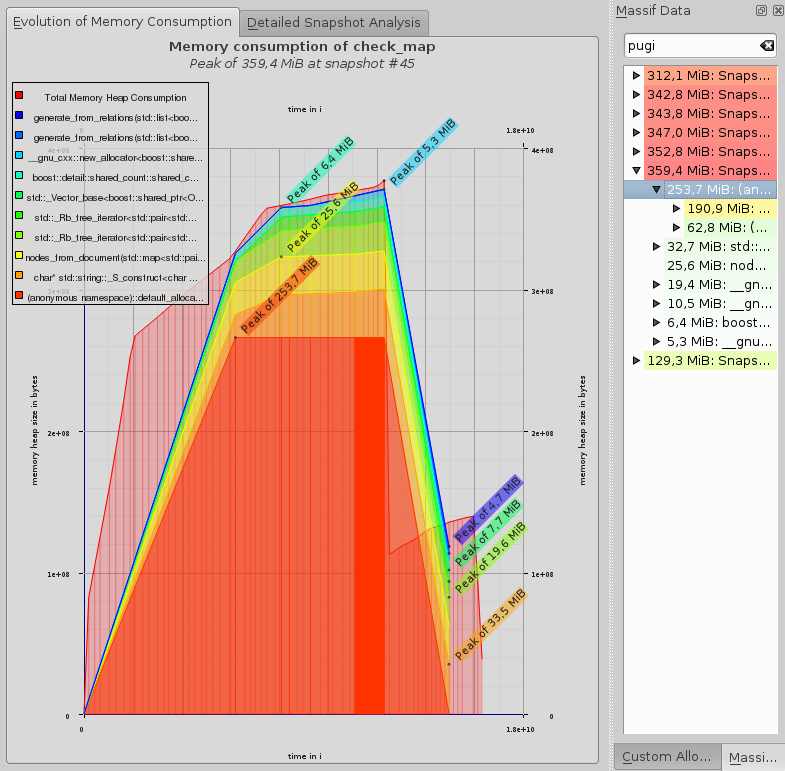
我粗略地估计了理论上的消费,以弄清楚哪些因素在消费和它应该是什么之间。所以我用valgrind --tool=massif来分析内存消耗。它显示,在350 It的峰值,250 It被称为xml_allocator的东西使用,它起源于pugixml库。我转到代码的这个部分,实例化pugi::xml_document,并将一个std::cout放入对象的析构函数中,以确认它在我的程序中很早就被释放了(最后,我睡了20多个小时,有足够的时间来测量内存消耗,即使在析构函数的控制台输出出现之后,内存消耗仍保持350 my )。
现在我不知道该如何解释,希望有人能帮我做错误的假设或诸如此类的事情。
使用pugixml的最外层代码片段类似于:
void parse( std::string filename, my_data_structure& struc )
{
pugi::xml_document doc;
pugi::xml_parse_result result = doc.load_file(filename.c_str());
for (pugi::xml_node node = doc.child("foo").child("bar"); node; node = node.next_sibling("bar"))
{
struc.hams.push_back( node.attribute("ham").value() );
}
}而且,由于在我的代码中,我不将pugixml元素存储在某个地方(只有从其中提取的实际值),所以当函数parse离开时,doc希望释放所有的资源,但是从图上看,我无法知道(在时间轴上)这种情况发生在什么地方。
回答 1
Stack Overflow用户
发布于 2013-07-31 17:06:54
你的假设是错误的。
下面是如何估计pugixml内存消耗的方法:
- 加载文档时,文档的整个文本将加载到内存中。你的档案是50 Mb。这是来自xml_document::load_file -> load_file_impl的1次分配。
- 除此之外,还有一个DOM结构,它包含指向其他节点的链接等等。节点的大小是32字节,属性的大小是20字节;对于32位进程,乘以2是64位进程。这与来自xml_allocator的分配(每个分配大约为32 is )一样多。
根据文档中节点/属性的密度,内存消耗可以从文档大小的110% (即50 Mb -> 55 Mb)到600% (即50 Mb -> 300 Mb)不等。
当您销毁pugixml文档(调用xml_document dtor )时,数据会被释放--但是,取决于OS堆的行为方式,您可能不会立即看到它返回到系统--它可能停留在进程堆中。要验证您是否可以再次执行解析,并在第二次解析之后检查峰值内存是否相同。
https://stackoverflow.com/questions/17963603
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号