
SQL查询将多行值规范化为一行一列字段
也许问题的标题不是批准者,但以下是解释:
我有以下表格:
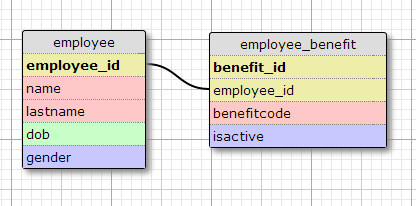
目前只有5项福利守则:
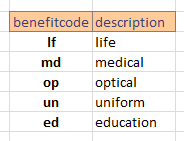
因此,一个员工可以有1到5个福利,但也可以是没有任何福利的员工。
在查询中,我需要返回的是带有相关福利的编码列的员工列表,如下面的示例所示:
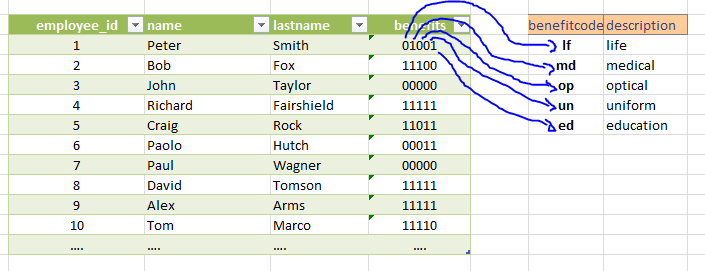
因此,“ employee ”列是员工相关福利中的编码列。
如果Peter与和Education相关联,那么“福利”列的编码值应该如表"01001“所示,其中0表示没有关联,1表示关联。
现在,我正在做愚蠢的登录,而且正在工作,但是处理起来太长了,我相信还有更好的方法和更快的方法:
SELECT emp.employee_id, emp.name, emp.lastname,
CASE WHEN lif.benefitcode IS NULL THEN '0' ELSE '1' END +
CASE WHEN med.benefitcode IS NULL THEN '0' ELSE '1' END +
CASE WHEN opt.benefitcode IS NULL THEN '0' ELSE '1' END +
CASE WHEN uni.benefitcode IS NULL THEN '0' ELSE '1' END +
CASE WHEN edu.benefitcode IS NULL THEN '0' ELSE '1' END as benefits
FROM employee emp
-- life
LEFT JOIN (
SELECT c.benefitcode, c.employee_id
FROM employee_benefit c
WHERE c.isactive = 1
and c.benefitcode = 'lf'
) lif on lif.employee_id = emp.employee_id
-- medical
LEFT JOIN (
SELECT c.benefitcode, c.employee_id
FROM employee_benefit c
WHERE c.isactive = 1
and c.benefitcode = 'md'
) med on med.employee_id = emp.employee_id
-- optical
LEFT JOIN (
SELECT c.benefitcode, c.employee_id
FROM employee_benefit c
WHERE c.isactive = 1
and c.benefitcode = 'op'
) opt on opt.employee_id = emp.employee_id
-- uniform
LEFT JOIN (
SELECT c.benefitcode, c.employee_id
FROM employee_benefit c
WHERE c.isactive = 1
and c.benefitcode = 'un'
) uni on uni.employee_id = emp.employee_id
-- education
LEFT JOIN (
SELECT c.benefitcode, c.employee_id
FROM employee_benefit c
WHERE c.isactive = 1
and c.benefitcode = 'ed'
) edu on edu.employee_id = emp.employee_id关于什么是最佳表现的最佳方式,有什么线索吗?
非常感谢。
回答 3
Stack Overflow用户
发布于 2013-07-08 03:53:53
首先,注意这个操作实际上是http://en.wikipedia.org/wiki/Denormalization模型,如果这是我的决定,我将保留规范化的表设计。我不知道是什么“压力”强制这种情况,但我发现这样的方法使模型更难维护和使用。这种非规范化可能会减慢查询的速度,否则会使用联接表上的索引。
尽管如此,一种方法是使用枢轴,它是Server (2005+)扩展。我设计了一个关于琴的例子。这个示例需要定制一些实际的表模式和效益值--在这种情况下,支点就在链接(employee_benefit)表之上。请注意福利状态上的预筛选器,以避免列(因此是隐式分组)通过枢轴爬行。
查询
select pvt.*
from (
select emp, benefitcode
from benefits
where isactive = 1
) as b
pivot (
-- implicit group by on other columns!
count (benefitcode)
-- the set of all values (to turn into columns)
for benefitcode in ([lf], [md], [op])
) as pvt定义
create table benefits (
emp int,
isactive tinyint,
benefitcode varchar(10)
)
go
insert into benefits (emp, isactive, benefitcode)
values
(1, 0, 'lf'), (1, 1, 'md'), (1, 1, 'op'),
(2, 1, 'lf'),
(3, 1, 'lf'), (3, 1, 'md'), (3, 1, 'md')
go结果
EMP LF MD OP
1 0 1 1 -- excludes inactive LF for emp #1
2 1 0 0
3 1 2 0 -- counts multiple benefits注意,与许多左联接一样,收益数据现在是面向固定值集的列。然后,只需操作结果查询中的数据(例如,在原始代码中这样做,但检查>= 1)就可以构建所需的位阵列值。
它会表现得更好吗?
我没有把握。然而,我的“最初预感”是,如果对employee列进行索引,查询可能执行得更好,但好处却不是;如果这两种方法的逆检查查询计划都知道Server真正在做什么,那么查询的性能可能会更差。
Stack Overflow用户
发布于 2013-07-08 03:10:18
为什么不直接加入一个将福利编码成整数的表(Life -> 10000,Medical -> 1000,.,-> 1;然后
- 福利代码整数之和;
- 将和转换为字符串;
- 在字符串'0000‘前面,接受最右边的5个字符。
更新:
select
EmployeeID,
right('0000' + convert(varchar(5),sum(map.value)),5)
from (
select value=10000, benefit = 'Lif' union all
select value= 1000, benefit = 'Med' union all
select value= 100, benefit = 'Uni' union all
select value= 10, benefit = 'Opt' union all
select value= 1, benefit = 'Edu'
) map
join
blah blah
group by EmployeeIDStack Overflow用户
发布于 2013-07-08 04:20:16
我喜欢总结的建议,但我会这样做:
Select
e.employee_id,
e.Name,
e.Lastname,
right('0000' + convert(varchar(5),sum(
case
when eb.benefitcode is null then 0
when eb.benefitcode = 'lf' then 10000
when eb.benefitcode = 'md' then 1000
when eb.benefitcode = 'op' then 100
when eb.benefitcode = 'un' then 10
when eb.benefitcode = 'ed' then 1
end )),5) benefits
from
Employee e
LEFT OUTER JOIN Employee_Benefit eb
on ( eb.Employee_id = e.Employee_id )
group by
e.employee_id,
e.Name,
e.Lastname没有机会尝试它的语法,但这是一般的想法。
https://stackoverflow.com/questions/17518627
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号