
我如何训练一个嗯与鲍姆-韦尔奇和多个观察?
我如何训练一个嗯与鲍姆-韦尔奇和多个观察?
提问于 2013-06-15 16:07:49
我在理解Baum算法的精确工作上有一些问题。我读到,它调整了HMM的参数(转移和发射概率),以最大化我的观测序列被给定的模型所看到的概率。
然而,如果我有多个观察序列,会发生什么呢?我想针对大量的观察来训练我的HMM (我认为这就是通常所做的)。
例如,ghmm可以为baumWelch方法同时获取一个观测序列和一组完整的观测数据。
在这两种情况下都是一样的吗?还是算法必须同时知道所有的观测结果?
回答 1
Stack Overflow用户
回答已采纳
发布于 2014-05-30 15:59:27
在Rabiner的纸中,GMMs (权值、均值和协方差)的参数在Baum算法中被重新估计,使用以下方程:
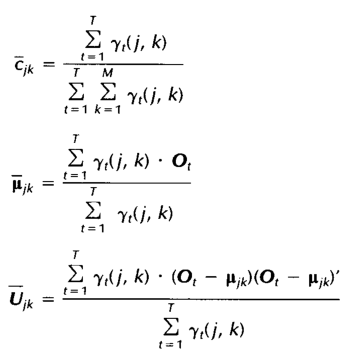
这些只是用于单次观测序列的情况。在多个情况下,分子和分母只是所有观测序列上的求和,然后除以得到参数。(这是可以做到的,因为它们仅仅代表占领数量,参见pg。(文件的273份)
因此,在调用该算法时,不需要知道所有的观察序列。例如,HTK中的HERest工具有一种机制,允许在多台机器之间分割训练数据。每台机器计算分子和分母,并将它们转储到一个文件中。最后,由一台机器读取这些文件,对分子和分母进行求和,并将它们除以得到结果。见皮格。129本HTK书第3.4卷
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/17125519
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号