
曲线拟合参数的scikits.learn聚类方法
我想建议使用最好的集群化技术,使用python和scikits.learn。我们的数据来自表型芯片,它测量细胞在不同底物上的代谢活性。输出是一系列乙状结肠曲线,我们通过对乙状结肠函数的拟合来提取一系列的曲线参数。
我们希望通过集群化来“排列”这个活动曲线,使用固定数量的集群。目前,我们使用的是包提供的k-均值算法,其中包含(init=‘随机’,k=10,n_init=100,max_iter=1000)。输入是一个矩阵,每个样本包含n_samples和5个参数。样本的数量可能各不相同,但通常在几千(即5'000)左右。集群似乎是高效和有效的,但我希望就不同的方法或对集群质量进行评估的最佳方法提出任何建议。
这里有几个可能有用的图表:
- 输入参数的散射图(其中有些参数相关性很强),单个样本的颜色相对于指定的聚类。
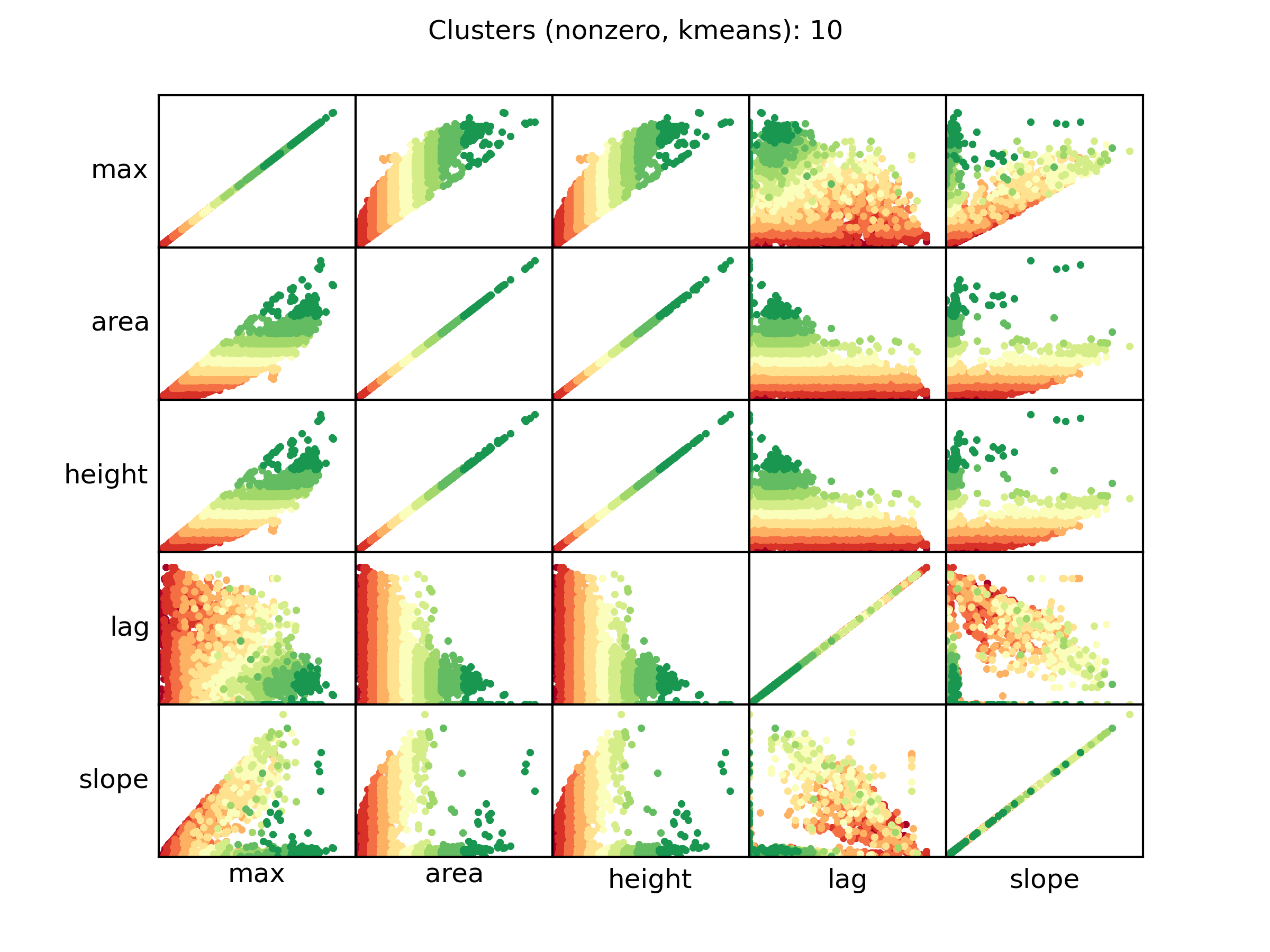
- 提取输入参数的乙状结肠曲线,其颜色相对于它们指定的聚类。
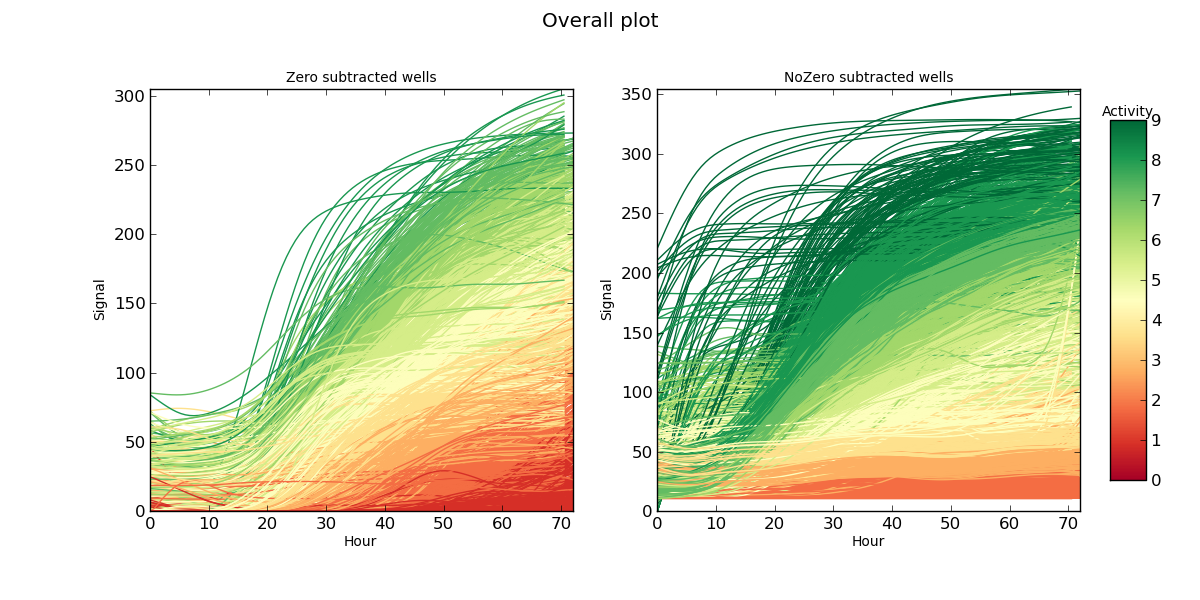
编辑
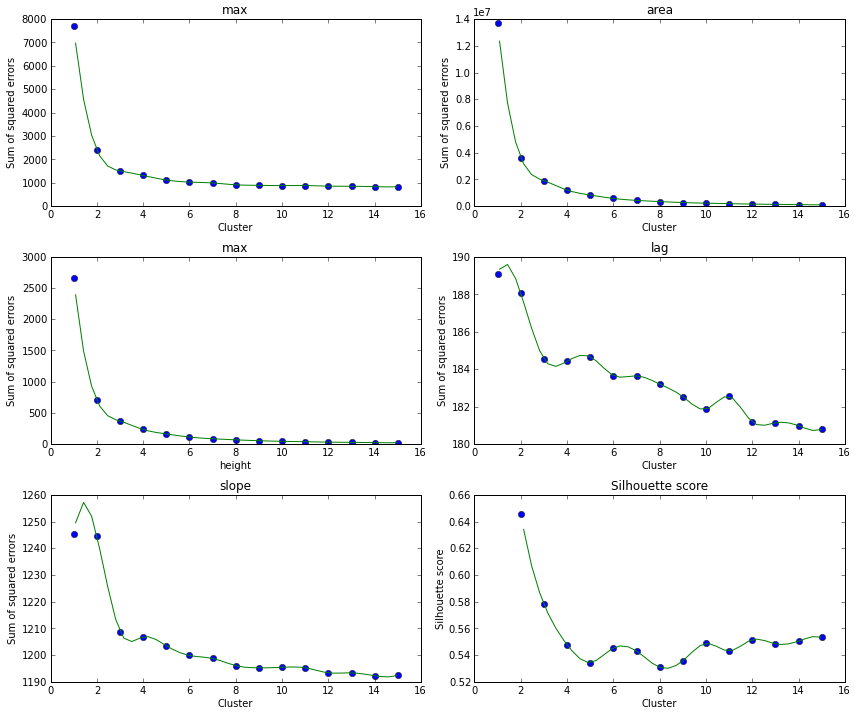
下面是一些肘部的图解和每一簇的剪影得分。
回答 2
Stack Overflow用户
发布于 2013-06-11 20:51:14
你注意到你情节中的条纹图案了吗?
这表明您没有很好地规范您的数据。
“面积”和“高度”是高度相关的,而且可能是规模最大的。所有的聚类都发生在这个轴上。
你绝对必须:
- 进行仔细的预处理
- 检查您的距离函数是否产生了一个有意义的相似概念(对您而言,而不仅仅是计算机)。
- 现实--检查你的结果,检查它们是否太简单,例如,由一个属性决定
不要盲目地跟随数字。不管你给出什么数据,K-表示都会很高兴地产生k个簇。它只是优化了一些数字。这取决于你检查结果是否有用,并分析它们的语义含义--它很可能只是数学上的局部最优,但对你的任务来说却毫无意义。
Stack Overflow用户
发布于 2013-06-11 15:53:26
对于5000个样本,所有的方法都应该没有问题。这是一个相当好的概述这里。需要考虑的一件事是,您是否想要固定集群的数量。根据这一点,请参见表中可能的集群算法选择。
我认为光谱聚类是一种很好的方法。例如,您可以与RBF内核一起使用它。不过,你必须调整伽马,并可能限制连接性。
不需要n_clusters的选择是WARD和DBSCAN,它们也是可靠的选择。你也可以咨询这张我个人意见的图表,我在科学学习文档中找不到这个链接.
用于判断结果:如果您没有任何类型的基本真理(如果这是探索性的,我想您没有),那么就没有好的度量现在还没有。
有一个没有监督的测度,剪影评分,但afaik,它支持非常紧凑的星系团,如k-均值。集群的稳定性措施可能会有所帮助,尽管它们还没有在sklearn中实现。
我的最佳选择是找到一种检查数据和可视化集群的好方法。你试过PCA并考虑过多种学习技术吗?
https://stackoverflow.com/questions/17046397
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号