
使用具有多种结果的C4.5分类器
使用具有多种结果的C4.5分类器
提问于 2013-06-10 19:10:27
我在看C4.5分类器的机器学习任务。我有一个包含城市名称的大型数据集,需要区分伦敦安大略省、伦敦英格兰,甚至法国勃艮第的伦敦,但要注意周围文字的特点:例如邮政编码、州名称,即使没有提到“加拿大”或“英格兰”。我还可以访问元数据,如拨号代码,这可以帮助确定它是哪个国家。
随后,一旦经过训练,我想在大型数据集上运行分类器。
在我发现的所有例子中,这里结果只有两个状态(在这个例子中,打或不打)。
c4.5分类器能否将伦敦(加拿大)、伦敦(英格兰)、伦敦(法国)作为结果类处理,或者我是否需要为伦敦(加拿大)、真假等设置不同的分类器?
回答 1
Stack Overflow用户
发布于 2013-06-11 21:25:57
我在你的案子里有两种选择。
- 第一种方法是对c4.5的直接扩展。在每个叶节点中,保留所有标签,而不是只保留大多数标签。例如,如下图所示,红色标签实际上存在于三种不同的叶子中。当在箭头指向的数据点进行查询时,输出为3个标签(绿色、红色和蓝色)以及相应的条件概率
p(c|v)(给定特征x1和x2,数据x属于c类的概率)。
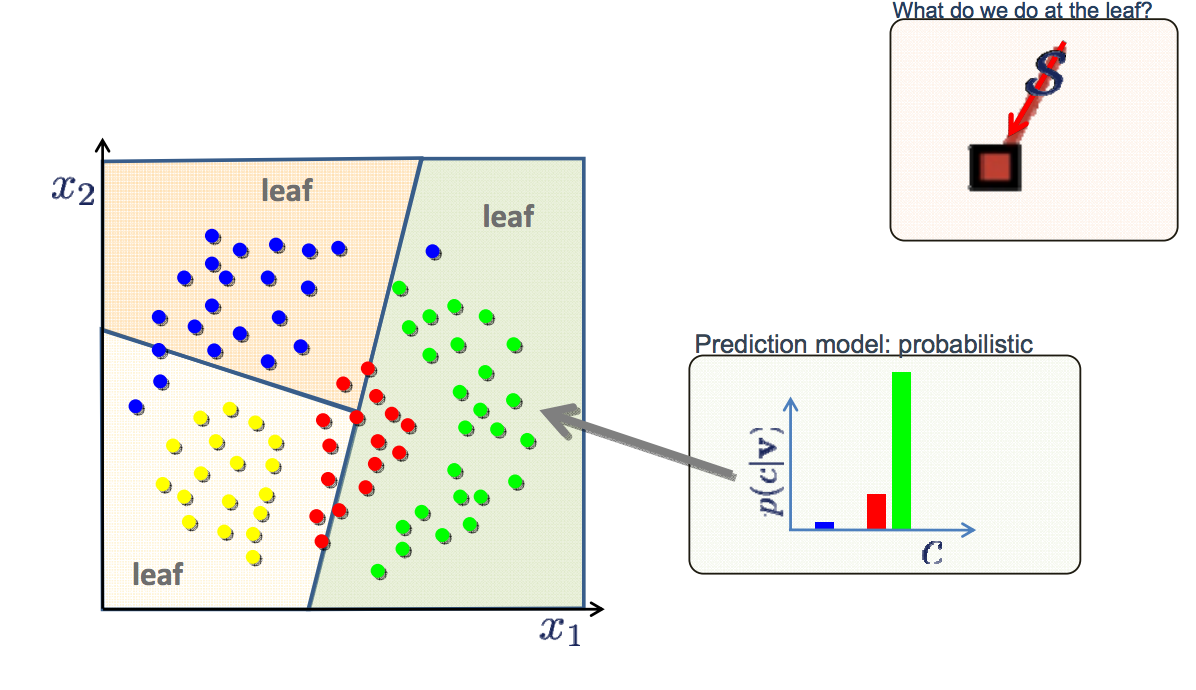
- 第二种方法是生成多个决策树,从而形成一个随机森林。随机化可以通过训练数据的随机抽样子集注入到每个个体树中。在分类时,可以聚合来自所有决策树的投票,以获得多类分类结果。
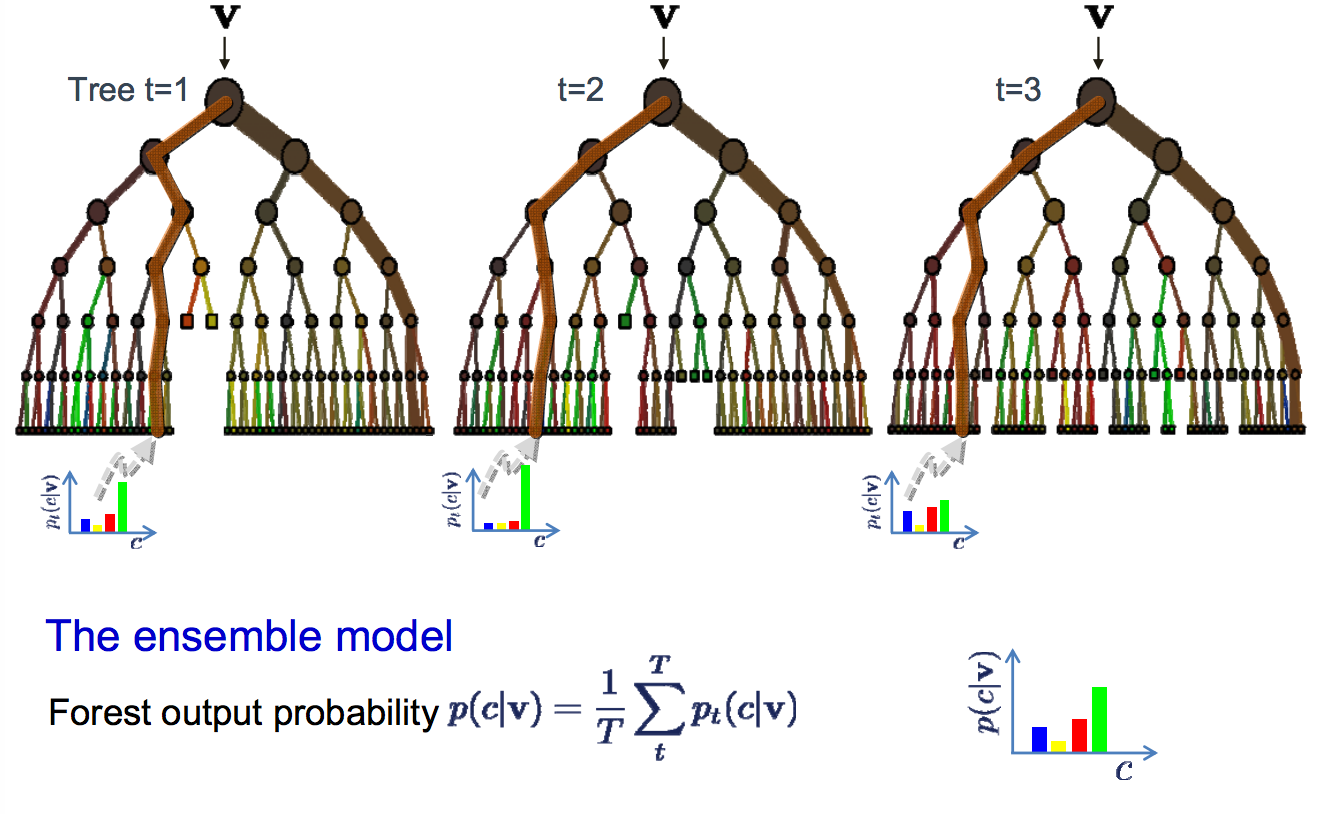
这些数字是借用了这个优秀的教程关于多类分类的安德鲁齐塞尔马。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/17031056
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号