
如何用水平线和文本来表示图形中的因素
我的数据如下所示:
dataExample<-data.frame(Time=seq(1:10),
Data1=runif(10,5.3,7.5),
Data2=runif(10,4.3,6.5),
Application=c("Substance1","Substance1","Substance1",
"Substance1","Substance2","Substance2","Substance2",
"Substance2","Substance1","Substance1"))
dataExample
Time Data1 Data2 Application
1 1 6.511573 5.385265 Substance1
2 2 5.870173 4.512775 Substance1
3 3 6.822132 5.109790 Substance1
4 4 5.940528 6.281412 Substance1
5 5 7.269394 4.680380 Substance2
6 6 6.122454 6.015899 Substance2
7 7 5.660429 6.113362 Substance2
8 8 6.649749 4.344978 Substance2
9 9 7.252656 4.764667 Substance1
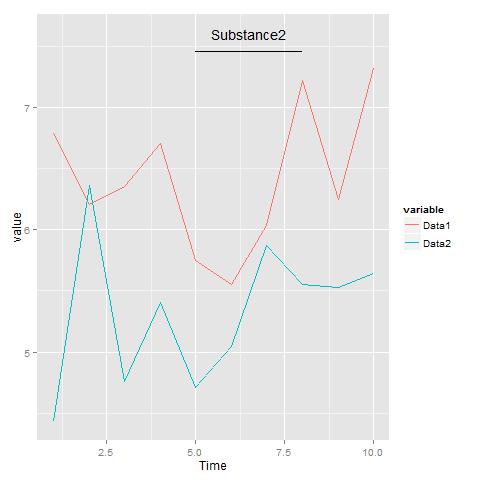
10 10 7.204440 5.835590 Substance1我想指出,什么时候使用了与dataExample$Application[1]不同的任何物质。
这里我向你们展示了我绘制这个图形的方法,但是我假设有一个更简单的方法来完成这个任务。
library(reshape2)
library(ggplot)
plotDataExample<-function(DataFrame){
longDF<-melt(DataFrame,id.vars=c("Time","Application"))
p=ggplot(longDF,aes(Time,value,color=variable))+geom_line()
maxValue=max(longDF$value)
minValue=min(longDF$value)
yAppLine=maxValue+((maxValue-minValue)/20)
xAppLine1=min(longDF$Time[which(longDF$Application!=longDF$Application[1])])
xAppLine2=max(longDF$Time[which(longDF$Application!=longDF$Application[1])])
lineData=data.frame(x=c(xAppLine1,xAppLine2),y=c(yAppLine,yAppLine))
xAppText=xAppLine1+(xAppLine2-xAppLine1)/2
yAppText=yAppLine+((maxValue-minValue)/20)
appText=longDF$Application[which(longDF$Application!=longDF$Application[1])[1]]
textData=data.frame(x=xAppText,y=yAppText,appText=appText)
p=p+geom_line(data=lineData,aes(x=x, y=y),color="black")
p=p+geom_text(data=textData,aes(x=x,y=y,label = appText),color="black")
return(p)
}
plotDataExample(dataExample)
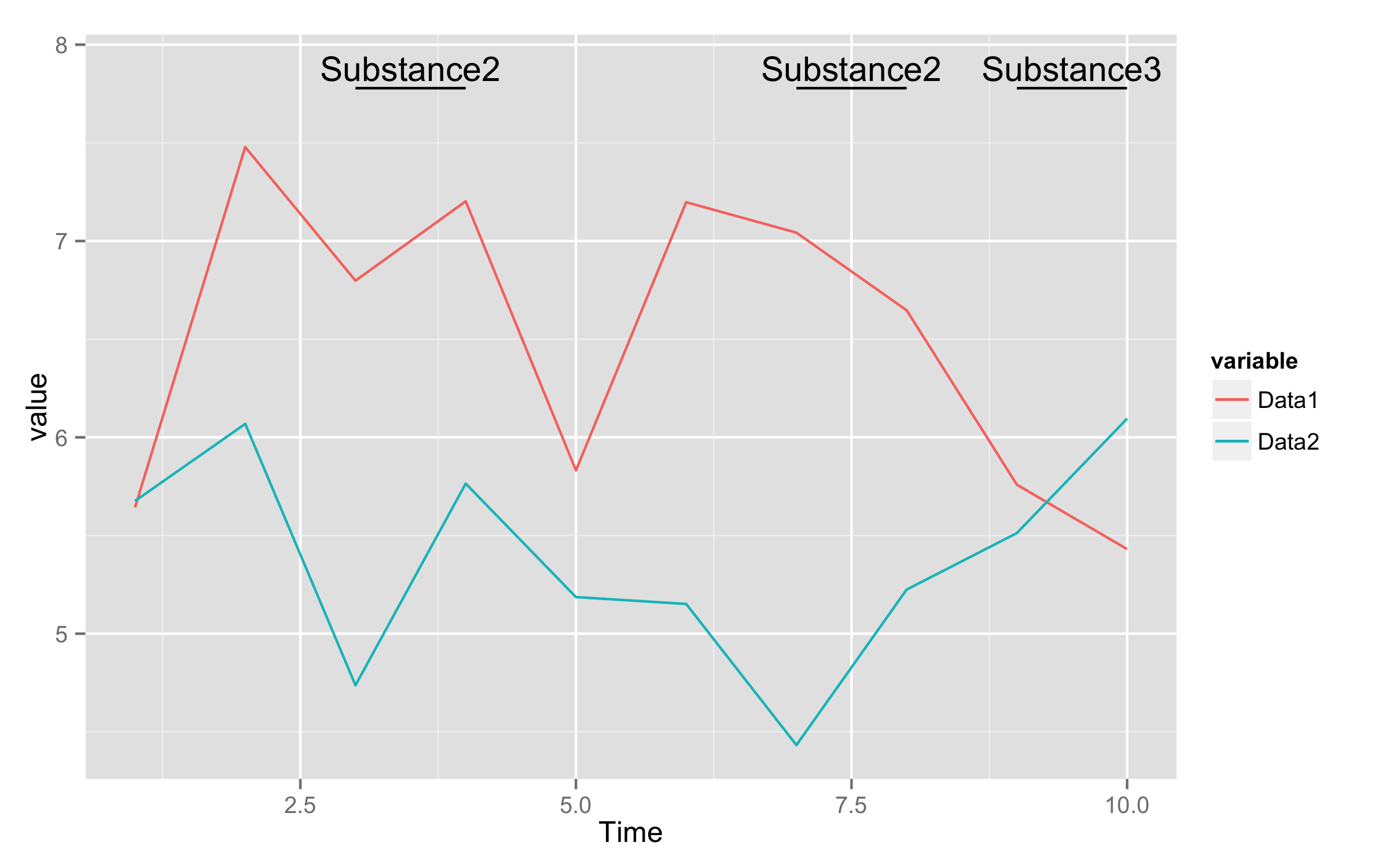
问题:,您知道获得类似结果的更好方法吗?这样我就可以指出多个因素(例如Substance3、Substance4 .)。
回答 1
Stack Overflow用户
发布于 2013-04-17 12:54:32
首先,使新的样本数据具有两个以上的水平和两次重复的Substance2。
dataExample<-data.frame(Time=seq(1:10),
Data1=runif(10,5.3,7.5),
Data2=runif(10,4.3,6.5),
Application=c("Substance1","Substance1","Substance2",
"Substance2","Substance1","Substance1","Substance2",
"Substance2","Substance3","Substance3"))没有把它作为显示每一步的功能。
将新列groups添加到原始数据帧--这包含用于分组Applications的标识符--如果物质发生更改,则形成新的组。
dataExample$groups<-c(cumsum(c(1,tail(dataExample$Application,n=-1)!=head(dataExample$Application,n=-1))))将数据行转换为长格式数据。
longDF<-melt(dataExample,id.vars=c("Time","Application","groups"))计算物质标识符的位置。使用函数ddply()从库plyr。对于计算,只使用与第一个Application值不同的数据(即subset())。然后使用Application和groups对数据进行分组。计算x轴上的起始位置、中间位置和结束位置,y值取最大值value +0.3。
library(plyr)
lineData<-ddply(subset(dataExample,Application != dataExample$Application[1]),
.(Application,groups),
summarise,minT=min(Time),maxT=max(Time),
meanT=mean(Time),ypos=max(longDF$value)+0.3)现在用ggplot()和geom_line()绘制ggplot()数据,并使用geom_segment()添加上面的分段,使用新的数据框架lineData添加annotate()的文本。
ggplot(longDF,aes(Time,value,color=variable))+geom_line()+
geom_segment(data=lineData,aes(x=minT,xend=maxT,y=ypos,yend=ypos),inherit.aes=FALSE)+
annotate("text",x=lineData$meanT,y=lineData$ypos+0.1,label=lineData$Application)
https://stackoverflow.com/questions/16058697
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号