
分析多层分布式web应用程序(服务器端)
我想从服务器配置文件中获取一个复杂的web应用程序PoV。
根据上面的维基百科链接和堆栈溢出profiling标签描述,分析(以其形式之一)意味着获取应用程序API/组件的列表(或图形表示),每个组件都包含运行时调用的次数和花费在其中的时间。
请注意,与传统的一种程序/一种语言不同,web服务器应用程序可能是:
- 分布在多台机器上
- 不同的组件可以用不同的语言编写。
- 不同的组件可能运行在不同的OSes上,等等。
因此,传统的“只使用分析器”的答案并不容易适用于这个问题。
我叫,不是,我在找:
- 粗糙的性能统计数据,如各种日志分析工具(例如模拟)所提供的,也不适用于
- 客户端,按页计算的性能数据,就像Google的Pagespeed或Yahoo这样的工具显示的那样!Y!慢、瀑布图和浏览器组件加载时间)
相反,我正在寻找一个典型的分析器风格的报告:
- 通话次数
- 呼叫持续时间
根据函数/API/component-name,在web应用程序的服务器端。
归根结底,问题是:
如何能够描述一个多层、多平台、分布式的web应用程序?
基于自由软件的解决方案更受青睐。
我已经在网上搜索了一段时间的解决方案,除了一些非常昂贵的商业产品之外,我找不到任何令人满意的东西来满足我的需求。最后,我咬紧牙关,思考了这个问题,写了我自己的解决方案,我想自由地分享。
我正在发布我自己的解决方案因为这样做是被鼓励的
这个解决方案远非完美,例如,它处于非常高的级别(单个URL),这可能并不适合所有的用例。尽管如此,它还是帮了我很大的忙,试图了解我的web应用程序花在哪里的时间。
本着开放源码和知识共享的精神,我欢迎来自其他人的任何其他方法和解决方案,特别是优越的方法和解决方案。
回答 2
Stack Overflow用户
发布于 2013-03-02 20:10:03
考虑到传统的分析器是如何工作的,想出一个通用的自由软件解决方案应该是直截了当的。
让我们把这个问题分成两部分:
- 收集数据
- 显示数据
收集数据
假设我们可以将我们的web应用程序分解成它的各个组成部分(API,函数),并测量完成这些部分所需的时间。每个部分每天被调用数千次,因此我们可以在多个主机上收集一整天左右的数据。当这一天结束时,我们将有一个相当大的相关数据集。
Epiphany #1:将‘函数’替换为'URL',我们现有的web日志就是"it“。我们需要的数据已经在那里了:
- web的每个部分都由请求URL (可能带有一些参数)定义。
- 往返时间(通常以微秒为单位)出现在每一行上,我们手头上有一天(周、月)价值的行数。
因此,如果我们能够访问web应用程序的所有分布式部分的标准web日志,那么我们问题的第一部分(收集数据)就会得到解决。
显示数据
现在我们有了一个庞大的数据集,但仍然没有真正的洞察力。我们如何才能获得洞察力?
Epiphany #2:直接可视化我们的(多个)web服务器日志。
一幅画胜过一千字。我们可以用哪张照片?
我们需要将上千到数百万行的多个web服务器日志压缩成一个简短的摘要,这将告诉我们大多数关于我们性能的故事。换句话说:目标是直接从我们的web日志中生成一个类似分析器的报告,或者更好的:一个图形分析器报告。
想象一下我们可以绘制地图:
- 对一维的调用延迟
- 调用另一个维度的次数,以及
- 函数标识与颜色(实质上是一个三维)
其中一幅图片:下面显示了API所显示的延迟的叠加密度图(函数名是为说明性的目的而建立的)。
图表:
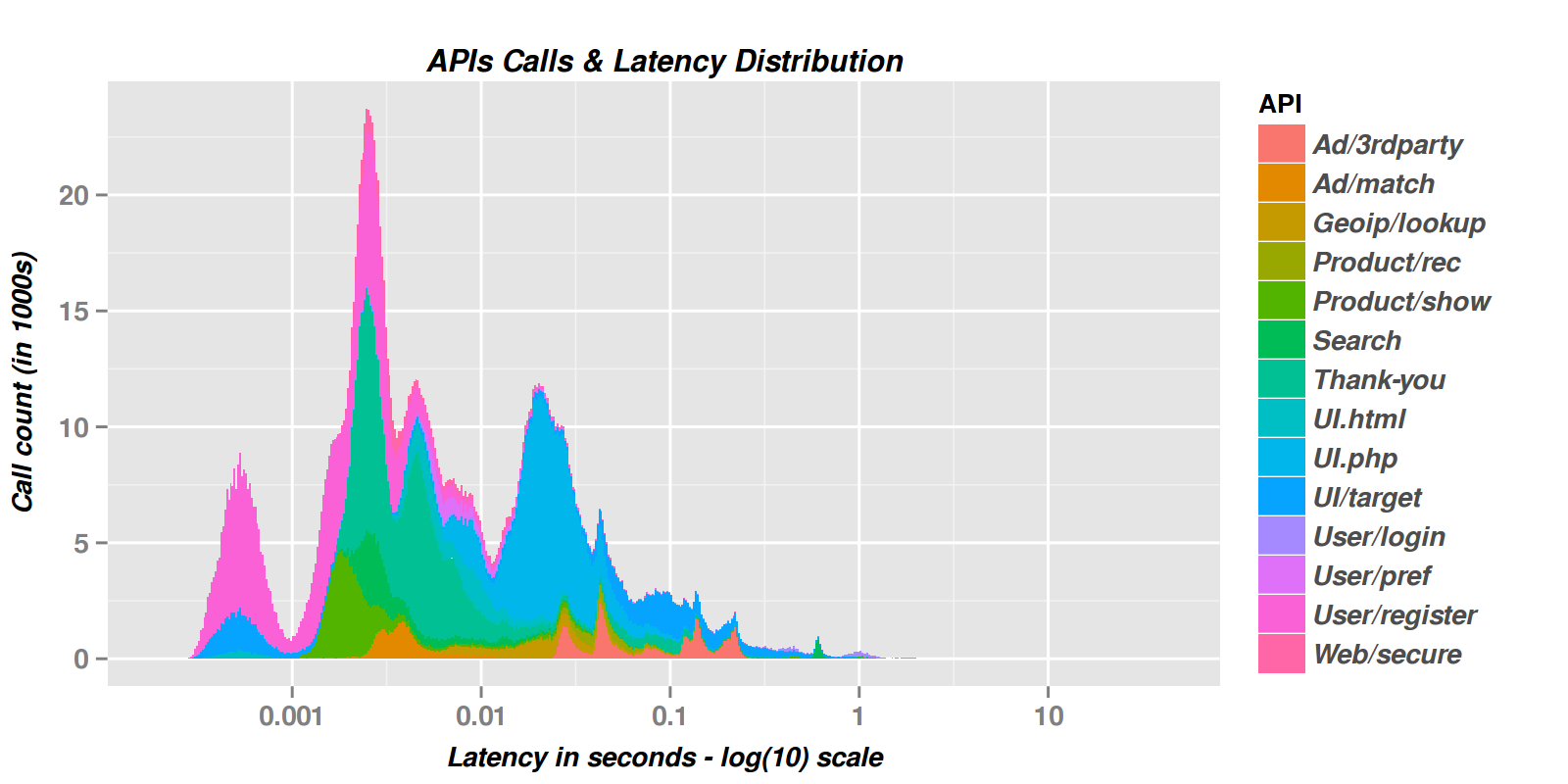
从这个例子中的一些观察
- 我们的应用程序中有一个三模态分布,代表了三个截然不同的“世界”:
- 最快的反应,集中在大约300微秒的延迟。这些响应来自我们的清漆缓存。
- 第二快,平均不到0.01秒,来自我们的中间层web应用程序(Apache/Tomcat)所提供的各种APIs。
- 最慢的响应集中在0.1秒左右,有时需要几秒钟来响应,包括往返于我们的SQL数据库。
我们可以看到缓存对应用程序的巨大影响(注意x轴是在log10规模上)。
我们可以明确地看到哪些API是快的还是慢的,所以我们知道应该关注什么。
我们可以看到每天最常调用哪些API。我们也可以看到,其中一些是如此罕见的名称,甚至很难看到他们的颜色在图表上。
该怎么做呢?
第一步是预处理并从日志中提取所需的子集。在这里,像多个日志上的Unix 'cut‘这样的简单实用程序就足够了。您还可能需要将多个类似的URL折叠到较短的字符串中,这些字符串描述函数/API,如“注册”或“购买”。如果您有一个由负载均衡器生成的多主机统一日志视图,这个任务可能会更容易。我们只提取APIs (URL)的名称和它们的延迟,因此我们最终得到一个带有一对列的大文件,由制表符隔开。
*API_Name Latency_in_microSecs*
func_01 32734
func_01 32851
func_06 598452
...
func_11 232734现在,我们在生成的数据对上运行下面的R脚本,以生成想要的图表(使用Hadley的出色的ggplot2库)。沃利亚!
生成图表的代码
最后,下面是从API+Latency TSV数据文件生成图表的代码:
#!/usr/bin/Rscript --vanilla
#
# Generate stacked chart of API latencies by API from a TSV data-set
#
# ariel faigon - Dec 2012
#
.libPaths(c('~/local/lib/R',
'/usr/lib/R/library',
'/usr/lib/R/site-library'
))
suppressPackageStartupMessages(library(ggplot2))
# grid lib needed for 'unit()':
suppressPackageStartupMessages(library(grid))
#
# Constants: width, height, resolution, font-colors and styles
# Adapt to taste
#
wh.ratio = 2
WIDTH = 8
HEIGHT = WIDTH / wh.ratio
DPI = 200
FONTSIZE = 11
MyGray = gray(0.5)
title.theme = element_text(family="FreeSans", face="bold.italic",
size=FONTSIZE)
x.label.theme = element_text(family="FreeSans", face="bold.italic",
size=FONTSIZE-1, vjust=-0.1)
y.label.theme = element_text(family="FreeSans", face="bold.italic",
size=FONTSIZE-1, angle=90, vjust=0.2)
x.axis.theme = element_text(family="FreeSans", face="bold",
size=FONTSIZE-1, colour=MyGray)
y.axis.theme = element_text(family="FreeSans", face="bold",
size=FONTSIZE-1, colour=MyGray)
#
# Function generating well-spaced & well-labeled y-axis (count) breaks
#
yscale_breaks <- function(from.to) {
from <- 0
to <- from.to[2]
# round to 10 ceiling
to <- ceiling(to / 10.0) * 10
# Count major breaks on 10^N boundaries, include the 0
n.maj = 1 + ceiling(log(to) / log(10))
# if major breaks are too few, add minor-breaks half-way between them
n.breaks <- ifelse(n.maj < 5, max(5, n.maj*2+1), n.maj)
breaks <- as.integer(seq(from, to, length.out=n.breaks))
breaks
}
#
# -- main
#
# -- process the command line args: [tsv_file [png_file]]
# (use defaults if they aren't provided)
#
argv <- commandArgs(trailingOnly = TRUE)
if (is.null(argv) || (length(argv) < 1)) {
argv <- c(Sys.glob('*api-lat.tsv')[1])
}
tsvfile <- argv[1]
stopifnot(! is.na(tsvfile))
pngfile <- ifelse(is.na(argv[2]), paste(tsvfile, '.png', sep=''), argv[2])
# -- Read the data from the TSV file into an internal data.frame d
d <- read.csv(tsvfile, sep='\t', head=F)
# -- Give each data column a human readable name
names(d) <- c('API', 'Latency')
#
# -- Convert microseconds Latency (our weblog resolution) to seconds
#
d <- transform(d, Latency=Latency/1e6)
#
# -- Trim the latency axis:
# Drop the few 0.001% extreme-slowest outliers on the right
# to prevent them from pushing the bulk of the data to the left
Max.Lat <- quantile(d$Latency, probs=0.99999)
d <- subset(d, Latency < Max.Lat)
#
# -- API factor pruning
# Drop rows where the APIs is less than small % of total calls
#
Rare.APIs.pct <- 0.001
if (Rare.APIs.pct > 0.0) {
d.N <- nrow(d)
API.counts <- table(d$API)
d <- transform(d, CallPct=100.0*API.counts[d$API]/d.N)
d <- d[d$CallPct > Rare.APIs.pct, ]
d.N.new <- nrow(d)
}
#
# -- Adjust legend item-height &font-size
# to the number of distinct APIs we have
#
API.count <- nlevels(as.factor(d$API))
Legend.LineSize <- ifelse(API.count < 20, 1.0, 20.0/API.count)
Legend.FontSize <- max(6, as.integer(Legend.LineSize * (FONTSIZE - 1)))
legend.theme = element_text(family="FreeSans", face="bold.italic",
size=Legend.FontSize,
colour=gray(0.3))
# -- set latency (X-axis) breaks and labels (s.b made more generic)
lat.breaks <- c(0.00001, 0.0001, 0.001, 0.01, 0.1, 1, 10)
lat.labels <- sprintf("%g", lat.breaks)
#
# -- Generate the chart using ggplot
#
p <- ggplot(data=d, aes(x=Latency, y=..count../1000.0, group=API, fill=API)) +
geom_bar(binwidth=0.01) +
scale_x_log10(breaks=lat.breaks, labels=lat.labels) +
scale_y_continuous(breaks=yscale_breaks) +
ggtitle('APIs Calls & Latency Distribution') +
xlab('Latency in seconds - log(10) scale') +
ylab('Call count (in 1000s)') +
theme(
plot.title=title.theme,
axis.title.y=y.label.theme,
axis.title.x=x.label.theme,
axis.text.x=x.axis.theme,
axis.text.y=y.axis.theme,
legend.text=legend.theme,
legend.key.height=unit(Legend.LineSize, "line")
)
#
# -- Save the plot into the png file
#
ggsave(p, file=pngfile, width=WIDTH, height=HEIGHT, dpi=DPI)Stack Overflow用户
发布于 2013-03-03 01:26:38
你对“回到过去”剖析实践的讨论是正确的。它一直有一个小问题:
- 在非玩具软件中,它可能会发现一些东西,但它找不到多少https://stackoverflow.com/a/1779343/23771。
高性能机会的关键是,如果你找不到它们,软件就不会中断,所以你可以假装它们不存在。也就是说,直到尝试了另一种方法,并找到了它们。
在统计中,这被称为类型2错误-假阴性。有机会,但你没找到。它的意思是,如果有人知道如何找到它,他们会赢,很重要的时间。https://scicomp.stackexchange.com/a/2719/1262
因此,如果你在查看web应用程序中相同的内容--调用计数、时间测量--那么你就不会比同类的非结果做得更好。
我不喜欢网络应用程序,但是很多年前我在一个基于协议的工厂自动化应用程序中做了相当多的性能调整。我用的是伐木技术。我不会说这很容易,但确实成功了。我看到做类似事情的人是在这里,他们使用他们所称的。基本思想是,您可以通过一个逻辑事务线程来跟踪,而不是抛出一个很宽的网络和获取大量的度量,分析哪些地方发生了不必要的延迟。
所以如果结果是你想要的,我会看不起这条思路。
https://stackoverflow.com/questions/15178903
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号