
在Smalltalk VisualWorks 7.9.1中将开放的声音控制VisualWorks转换成字符串
我正在接收来自服务器的UDP数据包(确切地说:打开声音控制数据包)。我将这些数据包存储在一个ByteArray中。
我想把这个ByteArray转换成字符串,这样我就可以利用接收到的数据。我尝试了大量的转换,但每次我都有不可读的字符。
以下是代码:
| server peerAddr |
server := SocketAccessor newUDPserverAtPort: 3333.
peerAddr := IPSocketAddress new.
buffer := ByteArray new: 1024.
[ server readWait.
server receiveFrom: peerAddr buffer: buffer.
Transcript show: (buffer asString) ; cr ; flush. ] repeat.我也尝试了以下转换,但没有成功:
buffer asByteString.
buffer asStringEncoding:#UTF8.
buffer asStringEncoding:#UTF16.
buffer asString.
buffer asBase64String.
buffer asFourByteString
buffer withEncoding: #ASCII以下是字符串输出:
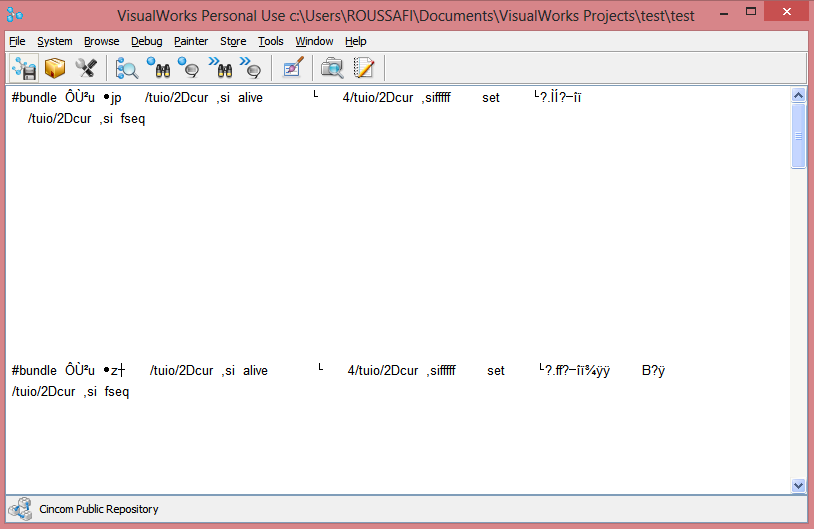
有什么帮助吗?
附加信息:接收到的数据是开放的声音控制数据,所以它有一个特定的格式,这就是为什么它是这样的,我需要解析ints,浮点数,字符串,以及特定的字节数组索引。有没有人推荐能提供这些可能性的套餐?
提前结束。
回答 3
Stack Overflow用户
发布于 2013-03-01 01:50:53
您可能可以借用Squeak的OSC包的大量代码:http://opensoundcontrol.org/implementation/squeak-osc
Stack Overflow用户
发布于 2013-02-28 11:35:02
如果要从字节数组读取数据,请使用UninterpretedBytes类。
你可以:
来自::= UninterpretedBytes : aByteArray。doubleAt: 5。
像那样的东西。还可以使用未解释的字节从字节中读取字符串。
Stack Overflow用户
发布于 2013-02-28 15:19:55
将字节转换为字符串的正确方法肯定是应用正确的字符编码。以下是
(65 to: 75) asByteArray asStringEncoding: #UTF8应该屈服
'ABCDEFGHIJK'使用#asStringEncoding:是正确的方法。然而,从屏幕截图来看,您正在接收的字节似乎不是一个直线字符串。您可能需要先分解一些二进制数据包格式,然后才能将您知道实际上是utf8编码的部分解码成字符串(或任何编码方式)。
https://stackoverflow.com/questions/15126931
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号