
连接100个表
假设我有一个主表,其中有100个列引用(作为外键)到大约100个表(包含主键)。
整个信息包需要加入这100个表。加入这么多的表无疑是一个性能问题。我们希望,任何用户都希望请求一组数据,其中包含来自大约5-7个表的值(在这100个表中),这些查询从大约3-4个表(其中的100个表中)将条件(部分查询的部分)放在字段中。不同的查询有不同的表组合,这些表用于生成查询的"SELECT“部分并将条件放在"WHERE”中。但是,每一个选择都需要大约5-7个表,而每个WHERE需要大约3-4个表(当然,用于生成SELECT的表列表可能与用于放置条件的表列表重叠)。
我可以用底层代码编写一个视图,将所有100个表连接起来。然后,我可以将上面提到的SQL-查询写到这个视图中。但是,在这种情况下,如何指示SQL Server (尽管代码中有加入所有这100个表的明确指令)是一个很大的问题,但只需要连接大约11个表(11个表就足以产生选择结果,并考虑到条件)。
另一种方法可能是创建一个转换以下“假”代码的“功能”
SELECT field1, field2, field3 FROM TheFakeTable WHERE field1=12 and field4=5转换成以下“真实”代码:
SELECT T1.field1, T2.field2, T3.field3 FROM TheRealMainTable
join T1 on ....
join T2 on ....
join T3 on ....
join T4 on ....
WHERE T1.field1=12 and T4.field4=5从语法角度看,即使允许这种“功能表-机制”与实际表格和结构的任何混合组合,也不是一个问题。这里真正的问题是如何在技术上实现这个“特性”。我可以创建一个函数,它以“假”代码作为输入,并生成“真实”代码。但这并不方便,因为它需要使用动态SQL工具,无论在什么地方出现这种“TheFakeTable机制”。一个幻想之地解决方案是扩展Management中SQL语言的语法,允许编写这样的假代码,然后在发送到服务器之前自动将这些代码转换成真实的代码。
我的问题是:
- 是否可以指示SQl服务器只加入11个表,而不是在上面描述的视图中加入100个表?
- 如果我决定创建这个“TheFakeTable-机理”特性,那么在技术上实现该功能的最佳形式是什么?
感谢大家的每一个评论!
PS有100个表的结构来自于我在这里提出的以下问题:使一张超大的桌子正常化
回答 3
Stack Overflow用户
发布于 2013-02-08 20:34:29
Server优化器确实包含删除冗余连接的逻辑,但是有一些限制,连接必须是可证明的冗余。总之,连接可以有四种效果:
- 它可以添加额外的列(从联接表)
- 它可以添加额外的行(联接的表可以多次匹配源行)
- 它可以删除行(联接的表可能没有匹配)
- 它可以引入
NULL(对于RIGHT或FULL JOIN)
要成功地删除冗余连接,查询(或视图)必须考虑所有四种可能性。如果这样做是正确的,效果可能是惊人的。例如:
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID优化器可以成功地简化以下查询:
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';至:
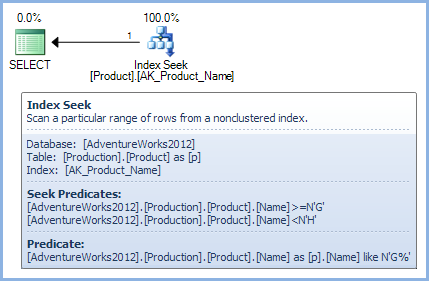
罗伯·法利( Rob )在原始MVP深海潜水艇书中对这些想法做了深入的描述,在SQLBits上有一个录制他就这一主题所作的发言。
主要的限制是外键关系必须基于单个键有助于简化过程,针对这样一个视图的查询的编译时间可能会变得相当长,特别是随着联接数量的增加。编写一个能使所有语义完全正确的100表视图可能是一个相当大的挑战。我倾向于找到另一种解决方案,也许使用动态SQL。
也就是说,非规范化表的特殊特性可能意味着视图的组装非常简单,只需要强制的FOREIGN KEYs非NULL可引用列,以及适当的UNIQUE约束,以使该解决方案如您所希望的那样工作,而不需要计划中的100个物理连接操作符的开销。
示例
使用10个表而不是100个表:
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);父表定义(带有页压缩):
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);意见:
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;黑掉统计信息,使优化器认为表非常大:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;示例用户查询:
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';给我们这个执行计划:
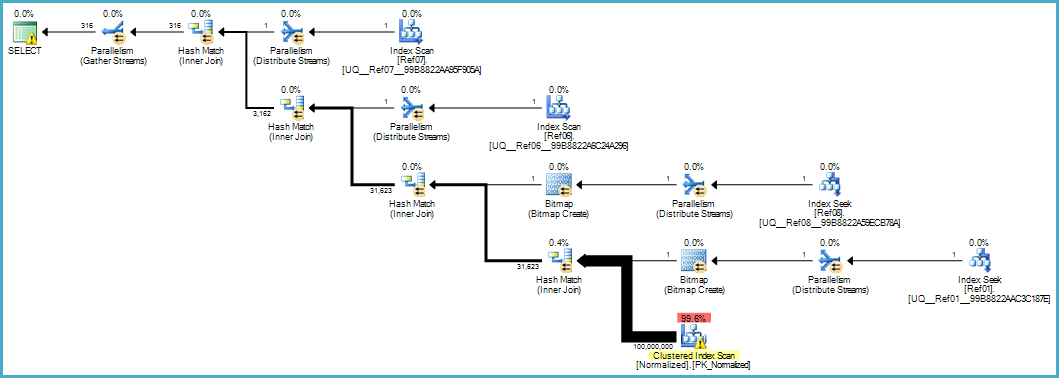
标准化表的扫描看起来很糟糕,但是两个Bloom-filter位图都是在扫描期间由存储引擎应用的(因此不能匹配的行甚至不能像查询处理器那样显示表面)。在您的情况下,这可能足以提供可接受的性能,当然比扫描具有溢出列的原始表更好。
如果您能够在某个阶段升级到Server 2012 Enterprise,则还可以选择另一个选项:在规范化表上创建列存储索引:
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);执行计划是:
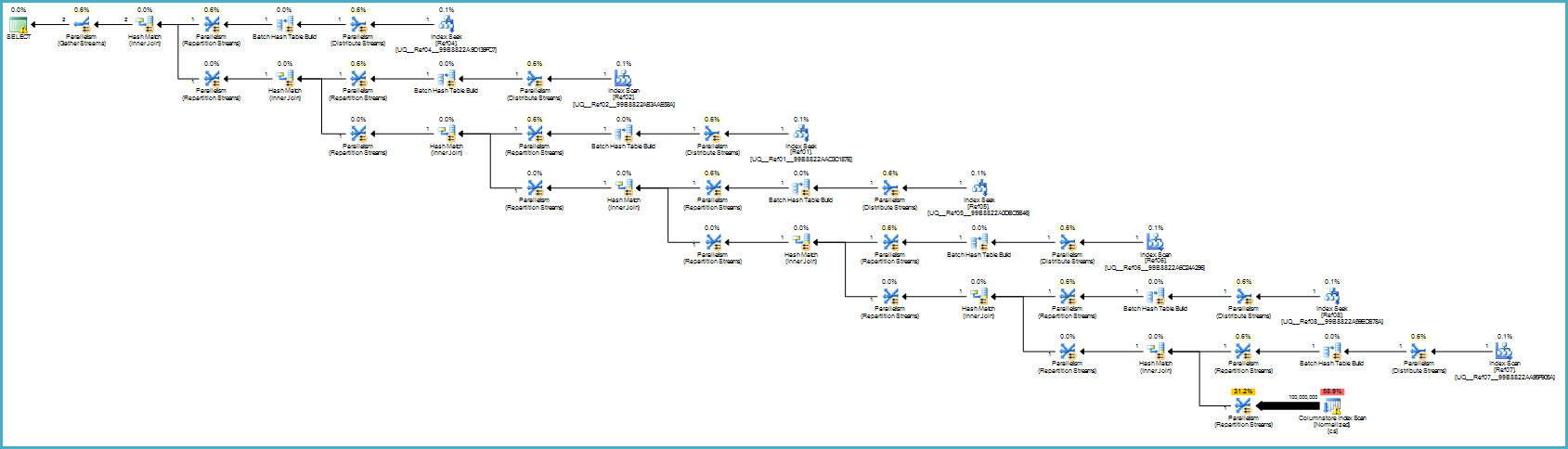
这在您看来可能更糟,但是列存储提供了异常的压缩,整个执行计划在批处理模式下运行,对所有的贡献列都有过滤器。如果服务器有足够的线程和内存可用,那么这个替代方案将真正发挥作用。
最终,考虑到表的数量和获得糟糕的执行计划或需要过多编译时间的可能性,我不确定这种规范化是否是正确的方法。我可能会首先更正非规范化表的模式(适当的数据类型等等),可能会应用数据compression...the通常的内容。
如果数据确实属于星型模式,那么它可能需要更多的设计工作,而不仅仅是将重复的数据元素分割成单独的表。
Stack Overflow用户
发布于 2013-02-08 19:56:18
为什么您认为加入100个表将是一个性能问题?
如果所有的键都是主键,那么所有的联接都将使用索引。那么,唯一的问题是索引是否适合内存。如果它们适合记忆,那么性能可能根本就不是一个问题。
在创建这样的语句之前,您应该尝试使用100个联接进行查询。
此外,根据最初的问题,参考表中只有几个值。表本身适合于一个页面,再加上索引的另一个页面。这是200页,最多占用几兆字节的页面缓存。不要担心优化,创建视图,如果您有性能问题,那么考虑接下来的步骤。不要预设性能问题。
阐述:
这得到了许多评论。让我解释一下为什么这个想法可能没有听起来那么疯狂。
首先,我假设所有连接都是通过主键索引完成的,并且索引适合内存。
页面上的100个键占用400个字节。假设原始字符串平均为40个字节。它们在页面上占据了4,000个字节,所以我们可以节省一些。事实上,在以前的计划中,大约有2条记录可以放在一页上。在一页纸上约有20把钥匙。
因此,用键读取记录在I/O方面比读取原始记录快10倍。假设少量的值,索引和原始数据适合内存。
读20张唱片需要多长时间?旧的方法要求阅读10页。有了键,就有一个页面读取和100*20索引查找(可能需要额外的查找来获取值)。根据系统的不同,2,000个索引查找可能比额外的9页I/O更快--甚至更快--我想指出的是,这是一个合理的情况。这种情况可能发生在某个特定的系统上,也可能不会发生,但它并不疯狂。
这有点过于简单了。Server实际上不会一次读取页面。我认为它们是按4组阅读的(在进行全表扫描时,可能会有前瞻性读取)。另一方面,在大多数情况下,表扫描查询将比处理器绑定更多I/O绑定,因此在引用表中查找值有空闲的处理器周期。
事实上,使用键可以比不使用键更快地读取表,因为空闲处理周期将用于查找(“备用”,即读取时可用处理能力)。事实上,带有键的表可能足够小,可以容纳到可用的缓存中,大大提高了更复杂查询的性能。
实际性能取决于许多因素,如字符串的长度、原始表(大于可用的缓存吗?)、底层硬件同时进行I/O读取和处理的能力,以及查询优化器对正确执行连接的依赖。
我最初的观点是,假设预先假定100个联接是一件坏事是不正确的。这个假设需要进行测试,使用键甚至可以提高性能。
Stack Overflow用户
发布于 2013-02-08 20:46:04
如果您的数据没有太大的变化,您可能会受益于创建一个索引视图,它基本上实现了视图。
如果数据经常发生变化,这可能不是一个好的选择,因为服务器必须为视图的底层表中的每个更改维护索引视图。
这里有一个很好的博客帖子,可以更好地描述它。
来自博客:
CREATE VIEW dbo.vw_SalesByProduct_Indexed
WITH SCHEMABINDING
AS
SELECT
Product,
COUNT_BIG(*) AS ProductCount,
SUM(ISNULL(SalePrice,0)) AS TotalSales
FROM dbo.SalesHistory
GROUP BY Product
GO下面的脚本在我们的视图中创建索引:
CREATE UNIQUE CLUSTERED INDEX idx_SalesView ON vw_SalesByProduct_Indexed(Product)要显示已经在视图上创建了索引,并且它确实占用了数据库中的空间,请运行以下脚本,以了解聚集索引中有多少行以及视图占用了多少空间。
EXECUTE sp_spaceused 'vw_SalesByProduct_Indexed'下面的SELECT语句与前面的语句相同,但这次它执行聚集索引查找,这通常非常快。
SELECT
Product, TotalSales, ProductCount
FROM vw_SalesByProduct_Indexed
WHERE Product = 'Computer'https://stackoverflow.com/questions/14780307
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号