
基于PCA的手写体数字分类
用主成分分析法对手写数字进行分类。列车阶段使用200位数字,测试使用20位数字。
我不知道PCA作为分类方法是如何工作的。我学会了把它作为一种降维方法,从它的平均值中减去原始数据,然后计算协方差矩阵、特征值和特征向量。从那里,我们可以选择主成分,而忽略其余的。我该如何分类一堆手写数字?如何区分不同类别的数据?
回答 3
Stack Overflow用户
发布于 2013-01-30 22:15:26
如果您绘制了从PCA中获得的分数,您将看到某些类将屈服于一个集群。
简单R脚本:
data <- readMat(file.path("testzip.mat"))$testzip
pca <- princomp(t(data))
plot(pca$scores)会屈服于这样的阴谋:
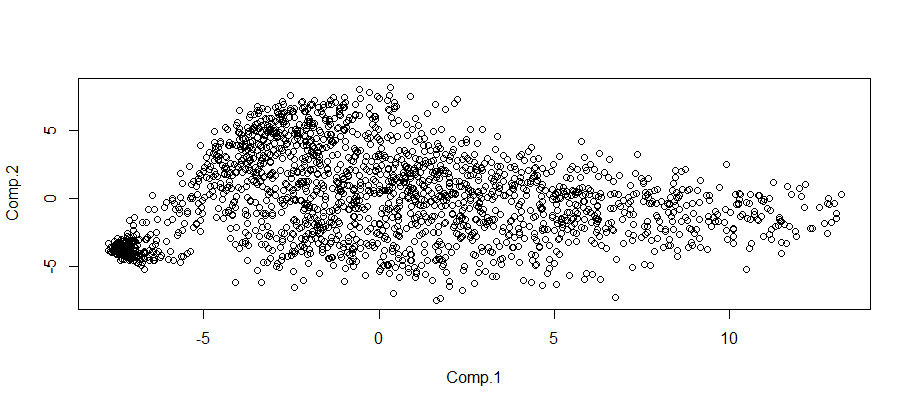
我不能给它着色,因为mat文件没有包含一个向量到一个数字类的结果。但是,您至少可以看到一个集群,它帮助您将单个类与其他类进行分类(其他内容似乎是噪音吗?)。
另外,Olivier Grisel (scikit-learn的贡献者)回答了您关于元优化的问题:
如何使用PCA进行分类?
他说,这实际上是一种无监督的降维方法,但是可以用一些奇特的方法进行分类:
实际上,我在Stéphane Mallat的这篇文章中找到了另一种“用PCA进行分类”的方法:每一类以第一分量为方向的仿射流形近似,质心作为偏移,而新的样本是用正交投影测量到最近流形的距离来分类的。 谈话:https://www.youtube.com/watch?v=lFJ7KdSdy0k (简历人士非常感兴趣) 相关论文:http://www.cmap.polytechnique.fr/scattering/
但我觉得这对你来说太过分了。如果你有类标签,你可以使用任何分类器来适应这个问题的PCA输出。如果不是,选择一个基于密度的集群,比如DBSCAN,看看它是否找到了您在那里看到的集群,并使用它对新图像进行分类(例如,根据距离集群平均值的距离)。
Stack Overflow用户
发布于 2013-02-01 15:18:20
是的,正如Thomas指出的,PCA和相关技术基本上是进行降维的工具。其思想是通过只获取最重要的信息并将其映射到低维子空间来对抗“维度诅咒”。在这个子空间中,您可以使用更简单的技术来实际对数据进行分类或聚类。
您可以从简单的K近邻到支持向量机来进行分类。为此,您还需要数据的标签。
让我们尝试使用kNN的最简单的方法(不一定是最好的方法):
现在,为了执行分类,您将需要另一个向量与实际标记。假设你有100个16x16像素的图像。在这100位中,有10位数字"0",10位数字"2“等等。
把这些图片做成一个1x1600的向量,把它们放进去。还创建一个带有“标签”的100x1向量。在matlab中是这样的:
labels = kron([0:1:9],ones(1,10))现在,将PCA应用于您的数据(假设每幅图像都是矩阵sampleimgs - so 256x100矩阵的一列),您也可以使用svd完成此操作:
[coeff,scores]= pca(sampleimgs');要将它们发送到所需的低维空间(例如R^2),只需选择两个第一个主成分:
scatter(scores(:,1),scores(:,2))现在,您可以将K应用于这些图像,并将新传入的图像newimg发送到相同的PC子空间后对其进行分类:
mdl = ClassificationKNN.fit(scores(1:100,[1 2]),labels);
%get the new image:
newimgmap = coef(:,1:2)'*newimg
result = predict(mdl,newimgmap)希望能帮上忙。
Stack Overflow用户
发布于 2014-08-29 02:24:07
丁和何(2004)表明,主成分分析降维和k均值聚类是密切相关的.聚类.a.无监督学习仍然不是分类。有监督的学习,但正如其他人所指出的,聚类可能有助于识别属于不同数字的数据点组。
https://stackoverflow.com/questions/14610377
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号