
神经网络:为什么感知器规则只适用于线性可分离的数据?
我以前用asked来解释线性可分数据。我还在读米切尔的机器学习书,我很难理解为什么感知器规则只适用于线性可分离的数据?
Mitchell对感知器的定义如下:
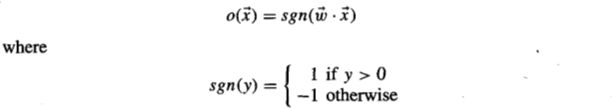
也就是说,如果加权输入之和超过某个阈值,则y为1或-1。
现在,问题是确定一个权重向量,使感知器为每个给定的训练示例产生正确的输出(1或-1)。实现这一目标的一种方法是通过感知器规则:
学习一个可接受的权重向量的一种方法是从随机权值开始,然后迭代地将感知器应用于每个训练示例,当感知器的权重错误分类时,修改感知器的权重。这个过程被重复,根据需要反复重复训练示例,直到感知器正确地对所有训练示例进行分类。根据感知器训练规则在每一步修改权重,根据该规则修正与输入xi相关的权重:
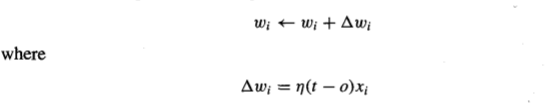
所以,我的问题是:为什么这只适用于线性可分数据?谢谢。
回答 1
Stack Overflow用户
发布于 2012-12-21 10:56:08
因为w和x的点积是xs的线性组合,而实际上,您使用超平面a_1 x_1 + … + a_n x_n > 0将数据分割成两个类。
考虑一个2D示例:X = (x, y)和W = (a, b),然后是X * W = a*x + b*y。如果它的参数大于0,则sgn返回1,即对于类#1,您有a*x + b*y > 0,它等同于y > -a/b x (假设b != 0)。这个方程是线性,并将二维平面分成2部分。
https://stackoverflow.com/questions/13988601
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号