
AST在antlr中用“* +”重写规则
AST在antlr中用“* +”重写规则
提问于 2012-12-20 04:17:20
在antlr中,我在重写从解析树转换为AST树的规则时遇到了麻烦。
这是我的反码:
grammar MyGrammar;
options {
output= AST;
ASTLabelType=CommonTree;
backtrack = true;
}
tokens {
NP;
NOUN;
ADJ;
}
//NOUN PHRASE
np : ( (adj)* n+ (adj)* -> ^(ADJ adj)* ^(NOUN n)+ ^(ADJ adj)* )
;
adj : 'adj1'|'adj2';
n : 'noun1';当我输入"adj1 noun1 adj2“时,解析树的结果如下:
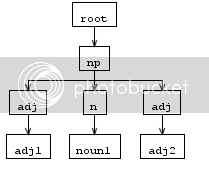
但是重写规则后的AST树看起来并不完全像解析树,adj是双重的,没有顺序,如下所示:
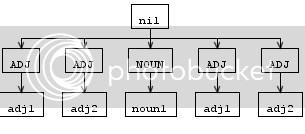
因此,我的问题是,如何重写规则以获得类似于上面的解析树的结果?
回答 1
Stack Overflow用户
回答已采纳
发布于 2012-12-20 05:12:37
您的名词短语规则收集所有形容词并将它们复制到名词的两边,因为ANTLR不能自动区分一组匹配的adjs和另一组。
下面是np规则的分解:
np : (
(adj)* //collect some adjectives
n+
(adj)* //collect some more adjectives
-> ^(ADJ adj)* //all adjectives written
^(NOUN n)+ //all nouns written
^(ADJ adj)* //all adjectives written again
)
;将这两个组分开的一种方法是将它们收集到各自的名单中。下面是一个应用于规则np的示例
np : (
(before+=adj)* //collect some adjectives into "before"
n+
(after+=adj)* //collect some adjectives into "after"
-> ^(ADJ $before)* //"before" adjectives written
^(NOUN n)+ //all nouns copied
^(ADJ $after)* //"after" adjectives written
)
;这样,ANTLR就知道在adjs之前和之后写出哪个ns。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/13965243
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号