
Antlr3搜索引擎语法
创建一个语法来解析搜索引擎,比如用antlr3解析语法,这是我需要帮助的任务。
语法应允许:
- 包括术语和术语之间:示例狗猫=狗和猫
- 并且应该优先于OR:猫狗或船=(猫和狗)或船
- 括号中术语的任意封装: cat或(狗和(鱼、牛)或鸟)
实现上述所有标准是一项挑战(对我来说)。请看一看我的语法,建议,错误和修正,因为适当地满足所有的标准是不可能的。
语法
tokens {
FOR;
END;
FIELDSEARCH;
TARGETFIELD;
RELATION;
ANDNODE;
}
startExpression : orEx;
expressionLevel4
: LPARENTHESIS! orEx RPARENTHESIS! | atomicExpression;
expressionLevel3
: (fieldExpression) | expressionLevel4 ;
expressionLevel2
: (nearExpression) | expressionLevel3 ;
expressionLevel1
: (countExpression) | expressionLevel2 ;
notEx : (NOT^)? expressionLevel1;
andEx : (notEx -> notEx)
(AND? a=notEx -> ^(ANDNODE $andEx $a))*;
orEx : andEx (OR^ andEx)*;
countExpression : COUNT LPARENTHESIS WORD RPARENTHESIS (LESSTHEN|MORETHEN) EQUAL? NUMBERS -> ^(COUNT WORD ^(RELATION LESSTHEN? MORETHEN? EQUAL?) NUMBERS);
nearExpression : NEAR^ LPARENTHESIS! (WORD|PHRASE) MULTIPLESEPERATOR! (WORD|PHRASE) MULTIPLESEPERATOR! NUMBERS RPARENTHESIS!;
fieldExpression : WORD PROPERTYSEPERATOR WORD -> ^(FIELDSEARCH ^(TARGETFIELD WORD));
atomicExpression
: WORD
| PHRASE ;
LPARENTHESIS : '(';
RPARENTHESIS : ')';
LESSTHEN : '<';
MORETHEN : '>';
EQUAL : '=';
AND : ('A'|'a')('N'|'n')('D'|'d');
OR : ('O'|'o')('R'|'r');
ANDNOT : ('A'|'a')('N'|'n')('D'|'d')('N'|'n')('O'|'o')('T'|'t');
NOT : ('N'|'n')('O'|'o')('T'|'t');
COUNT:('C'|'c')('O'|'o')('U'|'u')('N'|'n')('T'|'t');
NEAR:('N'|'n')('E'|'e')('A'|'a')('R'|'r');
PROPERTYSEPERATOR : ':';
MULTIPLESEPERATOR : ',';
fragment NUMBER : ('0'..'9');
fragment CHARACTER : ('a'..'z'|'A'..'Z'|'0'..'9'|'*'|'?');
fragment QUOTE : ('"');
fragment SPACE : ('\u0009'|'\u0020'|'\u000C'|'\u00A0');
//fragment UNICODENOSPACES : ('\u0000'..'\u0008'|'\u0010'..'\u0019'|'\u0021'..'\009F'|'\u00A1'..'\009F');
fragment UNICODENOSPACES : ('\u0021'..'\u0039'|'\u003B'..'\u007E'|'\u00A1'..'\uFFFF');
WS : (SPACE) { $channel=HIDDEN; };
NUMBERS : (NUMBER)+;
PHRASE : (QUOTE)(CHARACTER)+((SPACE)+(CHARACTER)+)+(QUOTE);
WORD : (UNICODENOSPACES)+;鉴于投入:
title:cats AND fish OR Bird AND (bird and dirt) OR (bart or title:bard OR bird AND title:dort)这个AST是创建的,请注意(),它是在一个WORD术语中捕获的。
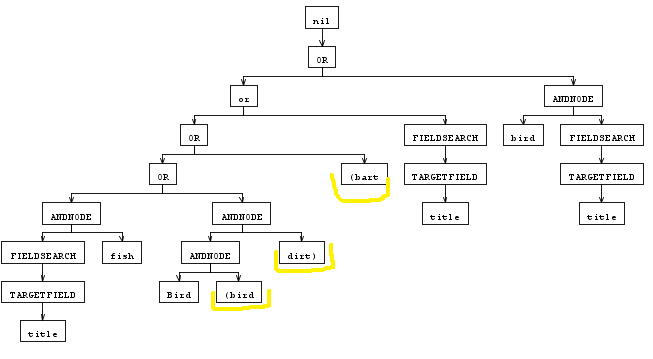
可能还有其他错误或愚蠢的实现细节。这是我第一次尝试使用antlr。
回答 1
Stack Overflow用户
发布于 2012-11-28 18:42:26
在ANTLR的第一次尝试中,你做的不仅仅是一件好事。
事实上,'('和')'在您的WORD令牌中是因为范围'\u0021'..'\u0039'包含括号。ANTLR的lexer匹配贪婪的字符,并尽量匹配(!)。由于最后一条规则(尽可能匹配更多的字符),它将从输入创建一个令牌,比如"(bird" ( WORD令牌),而不是两个令牌( LPARENTHESIS和WORD)。只需确保WORD需要匹配的任何内容中都不包含括号。
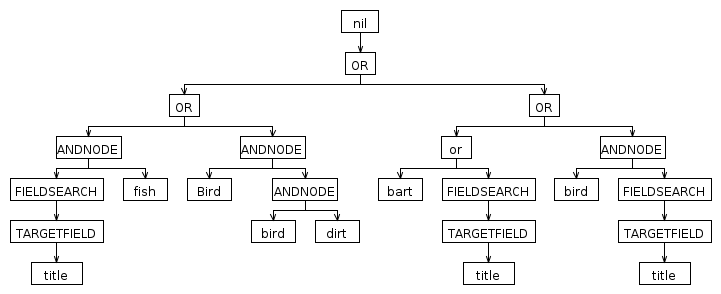
如果我复制您的语法并将WORD更改为:
WORD : CHARACTER+;您的输入被解析为:
编辑
是否可以将括号作为术语的正常部分?是否将blabla(bla( a)blabla识别为两个单词?)解析器必须决定括号是引入了一个子项,还是只是普通字符,形成了一个单词。
如果(a...和...a)中的括号是表达式的一部分,而不是WORD的一部分,则可以在lexer级别这样做。
WORD : UNICODENOSPACES ((UNICODENOSPACES | '(' | ')')* UNICODENOSPACES)?现在只允许在WORD中插入括号。您可以更进一步,允许(在WORD的末尾也是有效的,但我不确定这是否是一个好主意。
https://stackoverflow.com/questions/13608254
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号