
数字识别的建议
我正在编写一个Android应用程序,从图片中提取一个数独拼图。对于9x9 Sudoku网格中的每个单元格,我需要确定它是包含数字1到9中的一个还是空白。我从这样的数独开始:

我使用OpenCV对数独进行预处理,提取各个数字的黑白图像,然后通过特塞尔进行处理。然而,对Tesseract有几个限制:
- Tesseract很大,包含了很多我不需要的功能(例如,全文识别),并且需要英语培训数据才能发挥作用,我认为这必须放在设备的SD卡上。至少我可以告诉它只使用
tesseract.setVariable("tessedit_char_whitelist", "123456789");查找数字 - Tesseract常常将单数误解为数字串,通常包含换行符。有时候,这也是显而易见的,但它错了。以下是上述Sudoku的几个示例:
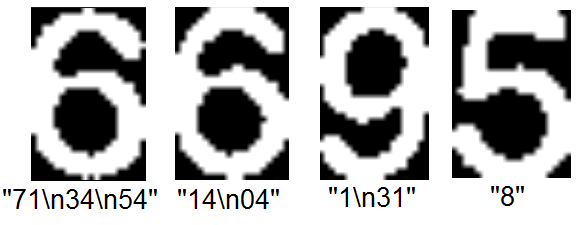
我有三个问题:
- 有什么办法可以克服Tesseract的局限性吗?
- 如果不是,什么是一个有用的,准确的方法来检测单个数字(不是k最近的邻居)是可行的在Android上实现--这可能是一个免费的库或一个DIY解决方案。
- 如何改进预处理以实现该方法?我考虑过的一种可能性是使用细化算法,正如这个职位所建议的那样,但我不会费心去实现它,除非它会产生影响。
回答 2
Stack Overflow用户
发布于 2012-11-10 06:21:08
我参加了计算机视觉超级巨星的一课程,他们在数字识别算法排名中位居榜首。他坚持认为最好的数字识别方法是.
1. Get some hand-labeled training data.
2. Run Histogram of Oriented Gradients (HOG) on the training data, and produce one
long, concatenated feature vector per image
3. Feed each image's HOG features and its label into an SVM
4. For test data (digits on a sudoku puzzle), run HOG on the digits, then ask
the SVM classify the HOG features from the sudoku puzzleOpenCV有一个HOGDescriptor对象,用于计算猪特征。有关如何优化HOG特性参数的建议,请参阅本论文。任何支持向量机库都应该做的job...the OpenCV附带的东西应该是好的。
对于训练数据,我建议使用手写体数字数据库,它有数千张数字图片和地面真实数据。
一个稍微困难的问题是在自然出现的数字周围画一个边框。幸运的是,看起来您已经找到了一种执行包围框的策略。:)
Stack Overflow用户
发布于 2012-11-10 09:35:35
最简单的方法是使用归一化中心矩来识别数字。如果您有一个字体(或非常类似的字体,它工作良好)。
参见此解决方案: https://github.com/grzesiu/Sudoku-GUI
核心是负责数字识别、提取、瞬间训练的东西。第一次运行应用程序时,运算符必须提供所看到的数字信息。然后将图像的矩量(提取的平方roi)分配给数字(算子输入)。基于比较矩的应用。
这里第一部youtube电影展示了应用程序的工作方式: http://synergia.pwr.wroc.pl/2012/06/22/irb-komunikacja-pc/
https://stackoverflow.com/questions/13319730
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号