
聚集索引可以更改动态SQL语句行为并返回不同的结果吗?
可能重复: ORDER BY suddenly conflicting with VARCHAR concatenation in TSQL
最近,我在一个表中发现了创建聚集索引,这个聚集索引更改了动态SQL语句的结果。当表有聚集索引时,该语句只返回最后一个已提交的结果。从表中删除聚集索引或删除“ORDER字段号”,将返回完整的结果(15个字段)。行为上的变化是由聚集索引和替换调用以及order和sample语句中k为1000 vs的声明引起的。
聚集索引可以更改动态SQL语句行为并返回不同的结果或其他我不知道的结果吗?欢迎任何意见!
-创建测试表
USE [test]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[test](
[companyid] [int] NOT NULL,
[fieldName] [nvarchar](50) NOT NULL,
[fieldnumber] [tinyint] NOT NULL,
[Tagname] [nvarchar](15) NULL
) ON [PRIMARY]
GO -插入测试数据
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'Employee Status', 1, N'<CHARACTER_1>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'Admin Grouping', 2, N'<CHARACTER_2>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'Department Code', 3, N'<CHARACTER_3>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'Job Code', 4, N'<CHARACTER_4>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'FLSA - Exempt', 5, N'<CHARACTER_5>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'Action Field 06', 6, N'<CHARACTER_6>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'Action Field 07', 7, N'<CHARACTER_7>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'Action Field 08', 8, N'<CHARACTER_8>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'Action Field 09', 9, N'<CHARACTER_9>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'Action Field 10', 10, N'<CHARACTER_10>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'ProcessLevel', 11, N'<CHARACTER_11>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'Department Name', 12, N'<CHARACTER_12>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'Job Title', 13, N'<CHARACTER_13>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'Information Field 04', 14, N'<CHARACTER_14>')
INSERT [dbo].[test] ([companyid], [fieldName], [fieldnumber], [Tagname]) VALUES (1, N'Information Field 05', 15, N'<CHARACTER_15>')
go -测试脚本
declare @k nvarchar(1000) --–-or max
set @k = ''
SELECT @k = @k + REPLACE(REPLACE(TagName,'<',''),'>','') + ',' FROM test WITH (NOLOCK)
WHERE CompanyID = 1 ORDER BY fieldnumber
select @k as test_result_without_index
go -创建一个集群索引来测试上面的脚本
CREATE CLUSTERED INDEX [ix-test] ON [dbo].[test]
(
[CompanyID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO -用nvarchar(1000)测试脚本,用聚集索引测试行为变化
declare @k nvarchar(1000) --–-or max
set @k = ''
SELECT @k = @k + REPLACE(REPLACE(TagName,'<',''),'>','') + ',' FROM test WITH (NOLOCK)
WHERE CompanyID = 1 ORDER BY fieldnumber
select @k as test_result_with_clustered_index_varchar1000_combine
go -用nvarchar (max)测试行为的测试脚本,在nvarchar(Max)下结合聚集索引测试行为
declare @k nvarchar(Max) --–-or max
set @k = ''
SELECT @k = @k + REPLACE(REPLACE(TagName,'<',''),'>','') + ',' FROM test WITH (NOLOCK)
WHERE CompanyID = 1 ORDER BY fieldnumber
select @k as test_result_with_clustered_index_and_varcharMax__combine
go --删除聚集索引
IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[dbo].[test]') AND name = N'ix-test')
DROP INDEX [ix-test] ON [dbo].[test] WITH ( ONLINE = OFF )
GO -然后创建非聚集索引
USE [test]
GO
CREATE NONCLUSTERED INDEX [ix_test] ON [dbo].[test]
(
[companyid] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO -用nvarchar (100)测试在nvarchar(100)下的行为没有变化的测试脚本与NONclustered索引相结合
declare @k nvarchar(1000) --–-or max
set @k = ''
SELECT @k = @k + REPLACE(REPLACE(TagName,'<',''),'>','') + ',' FROM test WITH (NOLOCK)
WHERE CompanyID = 1 ORDER BY fieldnumber
select @k as test_result_with_nonClustered_index_and_varchar1000_combine
go 回答 1
Stack Overflow用户
发布于 2012-10-23 01:29:56
这个查询从未被保证能正常工作。下面显示创建聚集索引后的查询计划。
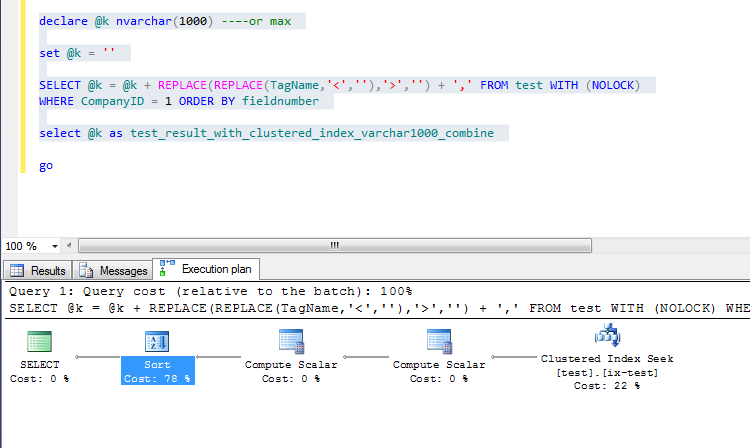
保证使用XML (解决方法和正确方法)的顺序,因为总是在查询完成后处理。但是,使用@var concat查询,Server可以根据需要优化查询。
在这里,您可以看到SELECT语句的连接是在排序之前完成的,因此行可以按任何顺序连接,返回的顺序不一定是最长的(final)。
我更喜欢文本计划,它显示了表达式,所以这里是:
StmtText
---------------------------------------------------------------------------------------------------------------------------------------------
|--Sort(ORDER BY:([test].[dbo].[test].[fieldnumber] ASC))
|--Compute Scalar(DEFINE:([Expr1005]=CONVERT_IMPLICIT(nvarchar(1000),([@k]+[Expr1006])+N',',0)))
|--Compute Scalar(DEFINE:([Expr1006]=replace(replace([test].[dbo].[test].[Tagname],N'<',N''),N'>',N'')))
|--Clustered Index Seek(OBJECT:([test].[dbo].[test].[ix-test]), SEEK:([test].[dbo].[test].[companyid]=(1)) ORDERED FORWARD)替换x2和CONCAT操作被放在一起,表面上是为了性能。
但是,如果将查询更改为
declare @k nvarchar(1000) --–-or max
set @k = ''
SELECT @k = @k + REPLACE(REPLACE(TagName,'<',''),'>','') + ','
FROM (
select TOP(100) TagName, fieldnumber
from test WITH (NOLOCK)
WHERE CompanyID = 1
order by fieldnumber
) X
order by fieldnumber
select @k as test_result_with_clustered_index_varchar1000_combine 您可以看到,在执行CONCAT之前,Server必须在子查询中进行排序。注意: TOP 100 PERCENT不工作,因为它得到优化离开,但顶部(N),其中N大于表中的记录数将工作。然而,正确的解决方案是使用XML。
StmtText
---------------------------------------------------------------------------------------------------------------------------------------------
|--Compute Scalar(DEFINE:([Expr1005]=CONVERT_IMPLICIT(nvarchar(1000),([@k]+[Expr1006])+N',',0)))
|--Sort(TOP 100, ORDER BY:([test].[dbo].[test].[fieldnumber] ASC))
|--Compute Scalar(DEFINE:([Expr1006]=replace(replace([test].[dbo].[test].[Tagname],N'<',N''),N'>',N'')))
|--Clustered Index Seek(OBJECT:([test].[dbo].[test].[ix-test]), SEEK:([test].[dbo].[test].[companyid]=(1)) ORDERED FORWARD)https://stackoverflow.com/questions/13022079
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号