
插入mongodb (pymongo)时的效率
为了清晰起见,进行了更新:在插入/附加到capped collection时需要性能建议。我有两个python脚本正在运行:
(1)跟踪光标。
while WSHandler.cursor.alive:
try:
doc = WSHandler.cursor.next()
self.render(doc)(2)插入如下:
def on_data(self, data): #Tweepy
if (len(data) > 5):
data = json.loads(data)
coll.insert(data) #insert into mongodb
#print(coll.count())
#print(data)它运行了一段时间(以每秒50次插入)。然后,在20-60秒之后,它会跌跌撞撞,撞上cpu的屋顶(尽管它以前运行的速度是20% ),永远也不会恢复。我的蒙古人正在潜水(潜水如下所示)。
Mongostat产出:
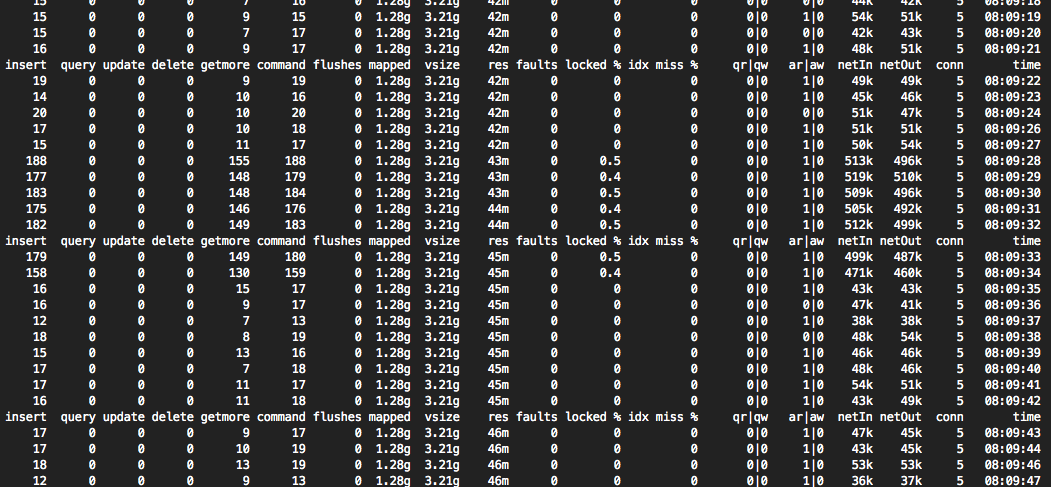
CPU现在被执行插入的进程阻塞(至少根据htop)。
当我使用print(data)运行上面的Tweepy行,而不是将它添加到db (coll.insert(data))中时,在15%的cpu使用率下,一切都运行得很好。
我在蒙古人身上看到的是:
res继续爬升。(尽管堵塞可能发生在40米处,但也可能在100米时运行良好。)flushes似乎不干预。locked %在0.1%时稳定。这最终会导致堵塞吗?
(我正在运行AWS微实例;pymongo。)
回答 1
Stack Overflow用户
发布于 2012-10-03 01:22:22
我建议在运行测试时使用mongostat。有许多事情可能是错误的,但是mongostat会给你一个很好的指示。
http://docs.mongodb.org/manual/reference/mongostat/
我要看的前两件事是锁百分比和数据吞吐量。通过在专用机器上的合理吞吐量,我通常在遭受任何退化之前,每秒进入1000-2000更新/插入。对于我工作过的几个大型生产部署来说,情况就是如此。
https://stackoverflow.com/questions/12698949
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号