
如何优化这个索引算法?
我的问题
- 我能加快计算速度吗?
- 是否有更好的算法或实现可以用来计算相同的值?
描述算法
我有一个复杂的索引问题,我正在努力以一种有效的方式解决。
目标是使用相同大小的矩阵( w_prime、dY和dX )中的值组合来计算矩阵dY。
w_prime(i,j)的值计算为mean( w( indY & indX ) ),其中indY和indX分别是dY和dX的指数,分别等于i和j。
下面是一个简单的w_prime算法在matlab中的实现
for i = 1:size(w_prime,1)
indY = dY == i;
for j = 1:size(w_prime,2)
indX = dX == j;
w_prime(ind) = mean( w( indY & indX ) );
end
end性能问题
在下面的示例中,这个实现就足够了;但是,在我的实际用例中,w、dY、dX是~3000x3000,w_prime是~60X900。这意味着每个索引计算都发生在大约900万个元素上。没有必要,这个实现太慢,无法使用。此外,我还需要运行这段代码几十次。
算例计算
如果我想计算w(1,1)
- 找到
dY的索引,等于1,另存为indY - 找到
dX的索引,等于1,另存为indX
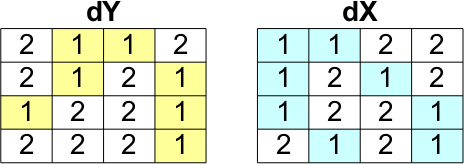
- 找到
indY和indX的交集,另存为ind
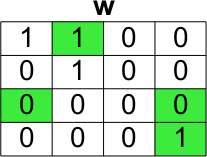
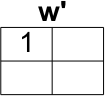
- 将
mean( w(ind) )保存到w_prime(1,1)
一般问题描述
我有一个由两个向量X和T定义的集合点,它们都是1XN,其中N是~3000。另外,X和T的值分别为区间(1 60)和(1 900)的整数。
矩阵dX和dT只是距离矩阵,这意味着它们包含点之间的成对距离。Ie dx(i,j)等于abs( x(i) - x(j) )。
它们是使用:dx = pdist(x);计算的。
矩阵w可以认为是一个权重矩阵,它描述了一个点对另一个点有多大的影响。
计算w_prime(a,b)的目的是确定a在X维数中与b在T维数中分离的点子集之间的平均权重。
这可以表示如下:
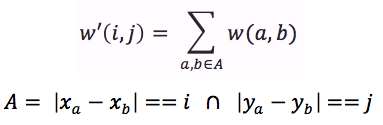
回答 1
Stack Overflow用户
发布于 2012-09-12 16:37:01
这在阿库马雷中是很简单的
nx = max(dX(:));
ny = max(dY(:));
w_prime = accumarray([dX(:),dY(:)],w(:),[nx,ny],@mean,NaN)输出将是一个nx-by-ny大小的数组,在没有对应的索引的地方使用NaNs。如果您确信任何时候都会有完整的索引,则可以将上述计算简化为
w_prime = accumarray([dX(:),dY(:)],w(:),[],@mean)那么,累加数组是做什么的?它查看[dX(:),dY(:)]的行。每一行在w_prime中给出该行所贡献的w_prime坐标对。对于所有对(1,1),它将函数(@mean)应用于w(:)中的相应条目,并将输出写入w_prime(1,1)。
https://stackoverflow.com/questions/12392061
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号