
像Java字节码、文件和ELF这样的机器代码可执行文件的字节码有什么区别?
字节码二进制可执行文件(如Java类文件、鹦鹉字节码文件或CLR文件)与机器代码可执行文件(如ELF、Mach-O和PE )之间有什么区别。
两者有什么不同之处?
例如,ELF结构中的.text区域等于类文件的哪一部分?
或者它们都有头,但是ELF和PE头包含体系结构,但是类文件不包含
Java类文件

精灵文件
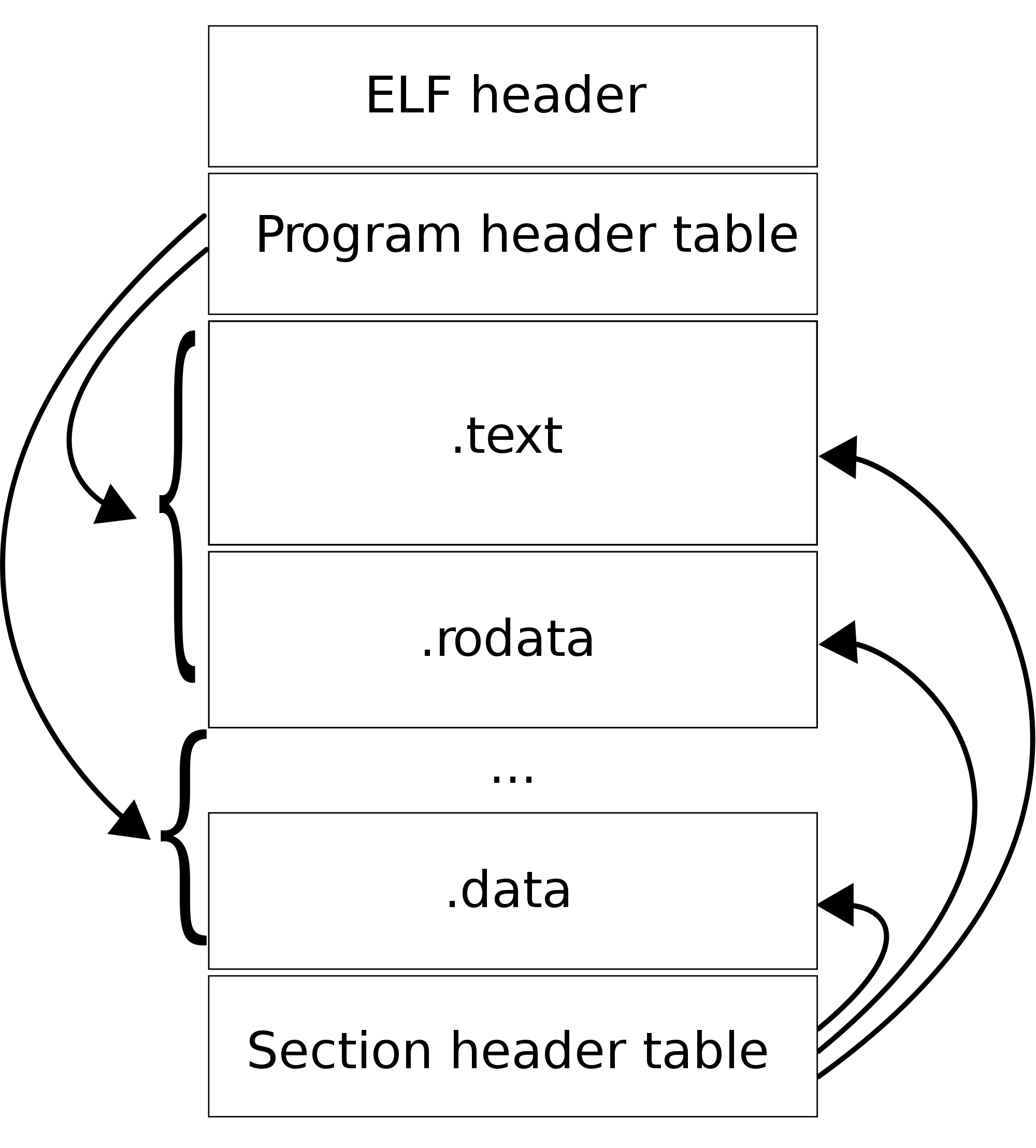
PE文件
回答 2
Stack Overflow用户
发布于 2012-08-30 22:45:10
正如imulsion所指出的,字节码是编译成机器代码之前的中间步骤。因为最后一步是加载时间(通常是运行时,就像JIT编译那样),所以字节代码是独立于体系结构的:运行时(CLR for .net或JVM for Java)负责将字节代码操作码映射到它们的底层机器代码表示形式。
相比之下,本机代码(Windows: PE、PE32+、OS /iOS: Mach-O、Linux/Android/etc: ELF)是编译后的代码,适用于特定的体系结构(Android/iOS: ARM,其他大多数是Intel 32位(i386)或64位)。这些都是非常相似的,但仍然需要部分(或者,在Mach-O术语中是“加载命令”)来设置可执行文件的内存结构,因为它是一个进程(旧的DOS支持".com“格式,这是一个原始的内存映像)。在以上所有内容中,您大致可以这样说:
- 带有“。”的章节。由编译器创建,并且是“默认”的,或者预期具有默认行为。
- 可执行文件有主代码部分,通常称为“文本”或".text“。这是本机代码,可以在特定的体系结构上运行。
- 字符串存储在一个单独的节中。它们用于硬编码输出(打印出来的内容)以及符号名。
- 符号--这些符号是链接器用来将可执行文件与其库(Windows: DLLs、Linux/Android: Shared对象、OS /iOS:.dylibs或框架)放在一起时使用的。通常还有一个"PLT“(过程链接表),它使编译器能够简单地将存根放入到您调用的函数(printf、open等)中,当可执行文件加载时,链接器可以连接这些函数。
- 导入表(用Windows的说法)。在ELF中,这是一个动态部分,在OS中,这是一个LC_LOAD_LIBRARY命令)用于声明其他库。如果在加载可执行文件时找不到这些文件,则加载失败,并且无法运行它。
- 导出表(用于库/dylibs/etc)是库(或在Windows中,甚至在.exe中)可以导出的符号,以便与其他库链接。
- 常量通常位于您所看到的".rodata“中。
希望这能有所帮助。真的,你的问题含糊不清。
热重
Stack Overflow用户
发布于 2012-08-30 07:01:44
字节码是一个“中途”步骤。因此,Java编译器(javac)将把源代码转换为字节代码。机器代码是下一步,计算机获取字节码,将其转换为机器代码(计算机可以读取这些代码),然后通过读取机器代码执行程序。计算机不能直接读取源代码,同样编译器也不能立即转换为机器代码。你需要一个半途而废的步骤来使程序工作。
https://stackoverflow.com/questions/12191462
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号