
字符串相似性: Bitap到底是如何工作的?
我正试图把我的注意力集中在比塔普算法上,但是我很难理解算法背后的原因。
我理解算法的基本前提,即(如果我错了请纠正我):
Two strings: PATTERN (the desired string)
TEXT (the String to be perused for the presence of PATTERN)
Two indices: i (currently processing index in PATTERN), 1 <= i < PATTERN.SIZE
j (arbitrary index in TEXT)
Match state S(x): S(PATTERN(i)) = S(PATTERN(i-1)) && PATTERN[i] == TEXT[j], S(0) = 1在英语中,如果成功匹配了以前的子字符串PATTERN.substring(0,i),并且PATTERN[i]处的字符与TEXT[j]上的字符相同,则PATTERN[i]匹配文本的子字符串。
我不明白的是,这是位变换的实现。详细说明这一算法的官方文件基本上给出了该算法。,但我似乎无法想象应该发生什么。算法规范仅是论文的前2页,但我将重点介绍其中的重要部分:
以下是这个概念的位转换版本:

下面是示例搜索字符串的Ttext:

这是算法的痕迹。
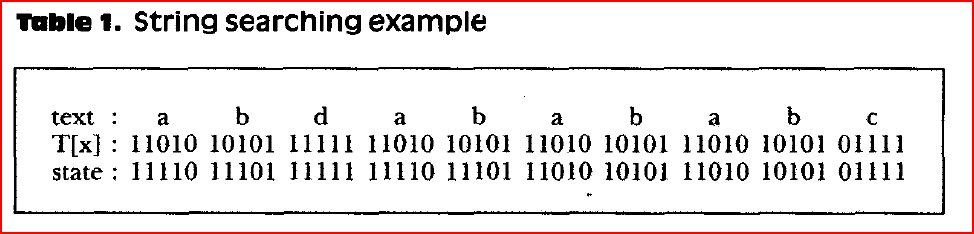
具体来说,我不明白T表意味着什么,也不明白为什么OR在其中使用当前状态的条目。
如果有人能帮我理解到底是怎么回事,我将不胜感激
回答 1
Stack Overflow用户
发布于 2012-07-04 00:17:40
很抱歉没有让其他人回答,但我很肯定我已经想好了。
该算法的基本概念是用二进制表示匹配状态(在原始post中定义)。原文中的文章对此作了正式的解释;我将试着用口语化的方式这样做:
让我们来看看STR,它是一个由给定字母表中的字符创建的字符串。
让我们用一组二进制数字表示STR:STR_BINARY。算法要求这个表示法是向后的(因此,第一个字母对应于最后一个数字,第二个字母对应于第二个到最后一个数字,等等)。
让我们假设RANDOM引用了一个字符串,该字符串具有来自相同字母表STR创建的随机字符。
在STR_BINARY中,给定索引处的0表示RANDOM将STR从STR[0]匹配到
STR[(index of letter in STR that the 0 in STR_BINARY corresponds to)]。空位算作匹配。1表示在同一边界内RANDOM与STR不匹配。
一旦理解了这个算法,学习就变得更简单了。
https://stackoverflow.com/questions/11317973
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号