
在Server上使用SqlBulkCopy推送信封需要建议
我正在设计一个应用程序,其中一个方面是它应该能够接收大量数据到SQL数据库。我将数据库狭窄设计为一个具有bigint标识的表,如下所示:
CREATE TABLE MainTable
(
_id bigint IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED,
field1, field2, ...
)我将省略我打算如何执行查询,因为这与我的问题无关。
我编写了一个原型,它使用SqlBulkCopy将数据插入到这个表中。在实验室里效果很好。我能够以3K记录/秒的速度插入数千万条记录(完整记录本身相当大,~4K)。因为这个表上唯一的索引是自动递增bigint,所以即使在推送了大量行之后,我也没有看到增长放缓。
考虑到实验室SQL服务器是一个配置相对较弱的虚拟机(4Gb RAM,与其他VM磁盘系统共享),我希望在物理机器上获得更好的吞吐量,但没有发生,或者说性能的提高可以忽略不计。我可以,也许能在物理机器上得到更快25%的插入。即使在我配置了3驱动器RAID0之后,它的执行速度是单个驱动器的3倍(通过基准测试软件来衡量),我也没有得到任何改进。基本上:更快的驱动子系统,专用的物理CPU和双RAM几乎没有转化为任何性能的提高。
然后我在Azure上使用最大的实例(8核,16 got )重复了测试,得到了相同的结果。因此,增加更多的核心并没有改变插入速度。
此时,我一直在使用以下软件参数,但性能并没有显著提高:
- 修改SqlBulkInsert.BatchSize参数
- 从多个线程同时插入,并调整线程#
- 在SqlBulkInsert上使用表锁选项
- 通过使用共享内存驱动程序从本地进程插入来消除网络延迟
我正试图提高性能至少2-3倍,我最初的想法是,投掷更多的硬件将得到完成,但到目前为止,它没有。
那么,谁能推荐我:
- 什么资源可能被怀疑是这里的瓶颈?如何确认?
- 考虑到有一个单一的SQL服务器系统,我是否可以尝试获得可靠的可伸缩批量插入改进?
更新我确信加载应用程序不是一个问题。它在一个单独线程中的临时队列中创建记录,所以当有一个插入时,它会如下(简化):
===>start logging time
int batchCount = (queue.Count - 1) / targetBatchSize + 1;
Enumerable.Range(0, batchCount).AsParallel().
WithDegreeOfParallelism(MAX_DEGREE_OF_PARALLELISM).ForAll(i =>
{
var batch = queue.Skip(i * targetBatchSize).Take(targetBatchSize);
var data = MYRECORDTYPE.MakeDataTable(batch);
var bcp = GetBulkCopy();
bcp.WriteToServer(data);
});
====> end loging time将记录时间,而创建队列的部分从不占用任何重要的块。
UPDATE2 I已经实现了收集该周期中每个操作所需的时间,其布局如下:
queue.Skip().Take()-可忽略不计MakeDataTable(batch)- 10%GetBulkCopy()-可忽略不计WriteToServer(data)- 90%
UPDATE3是为SQL的标准版本设计的,所以我不能依赖分区,因为它只能在企业版中使用。但我尝试了一种分区方案的变体:
- 创建了16个文件组(G0到G15),
- 创建了16个仅用于插入的表(T0到T15),每个表绑定到其单独的组。表根本没有索引,甚至没有聚集的int标识。
- 插入数据的线程将遍历所有16个表。这几乎保证了每个大容量插入操作都使用自己的表。
这确实使批量插入的产量提高了20%。CPU核心,局域网接口,驱动器I/O没有最大化,并且在最大容量的25%左右使用。
UPDATE4,我认为它现在已经很好了。我能够使用以下技术将插入推到合理的速度:
- 每个大容量插入进入自己的表,然后将结果合并到主表中。
- 每次大容量插入都重新创建新表,使用表锁。
- 使用IDataReader实现从这里开始而不是DataTable。
- 从多个客户端完成的批量插入
- 每个客户端都使用单独的千兆VLAN访问SQL。
- 使用NOLOCK选项访问主表的侧进程
- 我检查了sys.dm_os_wait_stats和sys.dm_os_latch_stats以消除争论
在这一点上,我很难决定谁会因为回答的问题而获得学分。你们中那些没有得到“回答”的人,我很抱歉,这是一个非常艰难的决定,我感谢你们。
UPDATE5:下面的项目可能需要一些优化:
- 使用IDataReader实现从这里开始而不是DataTable。
除非您在具有大量CPU核心计数的机器上运行您的程序,否则它可能需要一些重构。由于它使用反射来生成get/set方法,这将成为CPU的主要负载。如果性能是一个键,则在手动编写IDataReader代码时,它会增加许多性能,这样就可以编译它,而不是使用反射。
回答 3
Stack Overflow用户
发布于 2012-06-23 06:43:30
有关为批量加载优化Server的建议,请参阅MS中的数据加载和性能指南文件,以及联机书籍中的优化批量进口指南。虽然它们侧重于从Server进行大容量加载,但大多数建议都适用于使用客户端API进行批量加载。本文适用于SQL 2008 --您没有说明您要获得哪个Server版本
两者都有相当多的信息值得详细研究。然而,一些重点是:
- 最低限度地记录大容量操作。使用大容量日志或简单恢复。您可能需要启用traceflat610(但请参阅执行此操作时的注意事项)
- 调整批次大小
- 考虑对目标表进行分区
- 考虑在大容量负载期间删除索引
在数据加载和性能指南的流程图中很好地总结了以下内容:
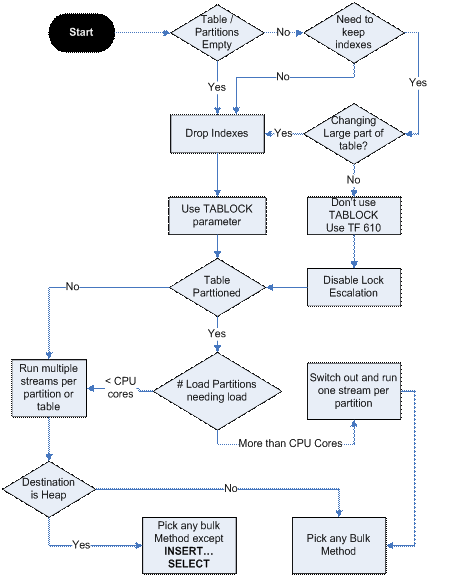
正如其他人所说的,您需要获得一些性能计数器来确定瓶颈的来源,因为您的实验表明IO可能不是限制。数据加载和性能指南包括要监视的SQL等待类型和性能计数器的列表(在“优化大容量加载”一节中,文档中没有要链接到的锚,但在文档中大约有75% )
更新
我花了一段时间才找到这个链接,但托马斯·凯泽( Thomas )的这个SQLBits的谈话也很值得一看--如果你没有时间观看全部内容,幻灯片是可用的。它重复了一些在这里链接的材料,但也涵盖了关于如何处理特定性能计数器的高发生率的一些其他建议。
Stack Overflow用户
发布于 2012-06-23 01:39:34
似乎你已经做了很多,但我不确定你是否有机会研究阿尔贝托法拉利SqlBulkCopy性能分析报告,其中描述了几个因素,以考虑与SqlBulkCopy相关的表现。我想说的是,在那篇论文中讨论的很多事情仍然值得一试,那将是最好的尝试。
Stack Overflow用户
发布于 2012-06-29 17:16:16
我不知道你为什么没有在CPU、IO或内存上获得100%的利用率。但是,如果您只是想提高散装装载速度,请考虑以下几点:
- 将数据文件划分为不同的文件。或者,如果它们来自不同的来源,那么只需创建不同的数据文件。
- 然后同时运行多个大容量插入。
根据您的情况,以上可能是不可行的;但如果您可以,那么我相信它应该提高您的负载速度。
https://stackoverflow.com/questions/11165803
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号