
HDFS中的存储格式
HDFS如何存储数据?
我想以压缩的方式存储巨大的文件。
我有一个1.5GB的文件,默认的复制因子是3。
它需要(1.5)*3 =4.5GB的空间。
我相信目前还没有对数据进行隐式压缩。
是否有压缩文件并将其存储在HDFS中以节省磁盘空间的技术?
回答 4
Stack Overflow用户
发布于 2012-06-01 22:40:23
HDFS将任何文件存储在多个“块”中。块大小在每个文件的基础上是可配置的,但有一个默认值(如64/128/256 MB)
因此,如果文件大小为1.5GB,块大小为128 MB,hadoop将将文件分解为~12个块(12x128MB ~= 1.5GB)。每个块也被复制了可配置的次数。
如果您的数据压缩良好(就像文本文件一样),那么您可以压缩这些文件并将压缩文件存储在HDFS中--同样如此,所以如果1.5GB文件压缩到500 be,那么这将被存储为4个块。
但是,在使用压缩时要考虑的一件事是压缩方法是否支持拆分文件--也就是说,您可以随机地查找文件中的某个位置并恢复压缩流(例如,GZIp不支持拆分,BZip2支持)。
即使该方法不支持拆分,hadoop仍然会将文件存储在多个块中,但是您将失去“数据局部性”的一些好处,因为这些块很可能分布在集群中。
在映射减少代码中,Hadoop默认安装了许多压缩编解码器,并将自动识别某些文件扩展名(例如,.gz用于GZip文件),从而使您不必担心是否需要压缩输入/输出。
希望这是有意义的
编辑一些附加信息以回应评论:
当将FileOutputFormat写入HDFS作为Map作业的输出时,请参见用于HDFS的API,特别是以下方法:
- setCompressOutput(作业,布尔)
- setOutputCompressorClass(工作,班级)
当将文件上传到HDFS时,是的,它们应该是预压缩的,并且与该压缩类型相关的文件扩展名(开箱即用,hadoop支持带有.gz扩展名的gzip,因此file.txt.gz将表示一个gzip文件)
Stack Overflow用户
发布于 2016-02-14 09:29:45
一段时间前,我试图在博客文章这里中总结这一点。本质上,这是一个数据可拆分性问题,因为文件被划分为作为复制的基本块的块。Name节点负责跟踪属于一个文件的所有块。在选择压缩时,块必须是自治的--并不是所有的编解码器都是可拆分的。如果格式+编解码器是不可分的,这意味着为了解压缩它需要在一个地方,这对mapreduce中的并行性有很大的影响。基本上是在一个槽里运行。希望这能有所帮助。
Stack Overflow用户
发布于 2016-02-15 06:22:44
查看一下presentation @ 峰顶,特别是幻灯片6和幻灯片7。
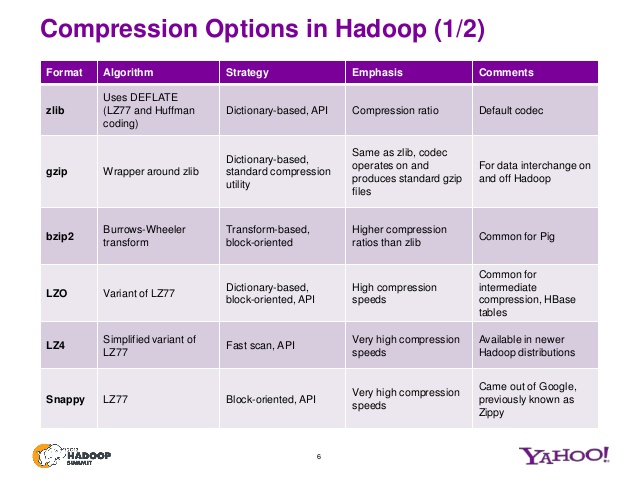

- 如果DFS块大小为128 MB,对于4.5GB存储(包括复制因子3),则需要35.15 (~36个块)
- 只有bzip2文件格式是可拆分的。在其他格式中,整个文件的所有块都存储在同一个Datanode中。
- 查看算法类型、类名和代码。
- @Chris答案提供了关于如何在编写Map输出时启用压缩的信息
https://stackoverflow.com/questions/10857880
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号