
无效益的空间指标
我有一个很大的查询,它试图将质心和它们里面的多边形匹配起来。虽然我确实约束了块和多边形的Z值,但是它仍然做一个多点计算的,并且运行很长的时间。
关于一些背景情况:
包含质心的表有2.5M行,表中的所有空间数据都在世界上很小的区域,整件事物的边框只有7643×2351米的这些行,660 K适合Z标准的criteria
- Running
- ,包含多边形的表有10K行,
H 113表中的所有空间数据都在世界上更小的区域H 214/code>H 115,2366匹配没有任何索引的查询名为/,2366匹配查询需要11个小时并返回91K匹配>
该查询如下所示:
select blocks.Id, blocks.WGS84Centroid, polygons.Shape
from
blocks inner join polygons
on
blocks.ZCentre >= (polygons.ZCentre - (polygons.ZLength/2)) and blocks.ZCentre <= (polygons.ZCentre + (polygons.ZLength/2)) and
polygons.Shape.STIntersects(blocks.WGS84Centroid) = 1
inner join name
on
polygons.nameId = name.ID
where name.Name = 'blah'因此,为了加快查询速度,我在blocks.WGS84Centroid上添加了一个空间索引,在polygons.Shape上添加了一个空间索引。
查询分析器还建议在blocks.ZCentre上建立一个非聚集索引,包括blocks.Id和blocks.WGS84Centroid。
在所有这些之后,下面是查询计划:
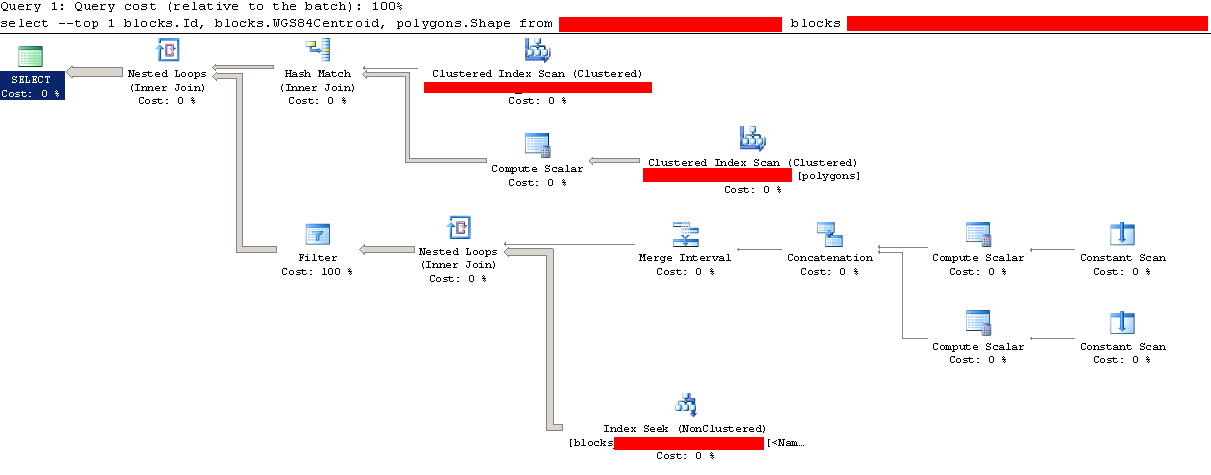
过滤成本:
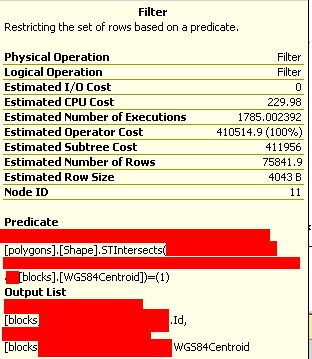
但是,在添加了这3个索引之后,查询仍然需要同样长的时间才能运行。
我现在能做什么?
回答 1
Stack Overflow用户
发布于 2012-05-31 08:17:16
我认为空间指数没有多大帮助的原因可能与地球上这么小的区域的数据密度有关。
我对此做了一些实验,最好的选择似乎是指数的密度越高越好。
在Server 2008中,这是通过在空间索引网格的四个级别中的每一层使用高。通过向优化者暗示使用这个索引,我把连接降到了~1小时而不是10小时!
在Server 2012中,我发现了另一些有趣的方面:
第一种情况是,如果地理对象之一是点,那么STIntersects()就会得到更好的优化,就像我的例子一样。在我的机器上,同样的查询在2012年运行速度是2008年的两倍。
第二个更令人印象深刻!2012年,一种新的空间索引使用了多达8个层次的镶嵌。我猜想稠密的数据特别适合索引中这个几何级别较高的索引,因为当暗示使用新索引而不是旧的4级索引时,相同的查询速度是原来的45倍。
https://stackoverflow.com/questions/10791916
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号