
如何设计处理当前员工和预测员工的数据模型?
我们正在创建一个应用程序来管理员工。员工可以是现职员工,也可以是未来将要加入的员工(预测)。
除了管理员工外,我们还必须每月管理预测。
假设今天是四月,
截至4月26日,现有员工人数为100人。
今天,我预计八月份将有10人加入。20人将于11月加入。
当我说,我预测,我实际上去增加了10和20名雇员在系统中。我可能有或可能没有完整的信息。我甚至可能没有名字,因为他们还没有被雇用。不过,我只是预测八月份会有10名雇员,而11月份则会有20名。
假设没有更多的离开者或加入者在中间。到8月底,我的员工人数将达到110人,到11月底将达到130人。
因此,我在4月份的预测是,8月份为110,11月份为130。
现在,我在五月得知,八月份只有五人加入,而不是十一月有二十人加入,此外,我们将在十二月解雇十名现有雇员。
因此,我预计五月份的员工人数将在8月份为105人,11月为130人,12月为120人。
因此,我需要每月保持雇员的数据,即我在4月份对未来每一个月,即从5月到12月的预测。
再一次,我在五月对八月到十二月的预测是什么。
诸若此类。
我亦要紧记,现时雇员的资料,可能每分钟都会有记录。
他们的头衔可能会改变,地址可能会改变,部门等。
因此,如果员工A在部门,D1在4月份,D2在4月之后。
当我拿出四月的报告时,它应该显示我是D1,当我拿出六月的报告时,它应该向我展示他的部门D2。
请帮帮忙。
在this previous question中还有一些附加的背景。
编辑:
请看下面的图片。
我想知道3月份(月份=3月份)各次月份的雇员人数,即月份=3月份,3月份= 400,4月份= 405。
括号中的数字显示将在该月份加入的新雇员,例如(+10)和(-5)表示该月份离职的雇员。因此,如果在3月份,雇员总数为400人,10人加入,5人在4月份离开,那么4月份的总数将为405人。
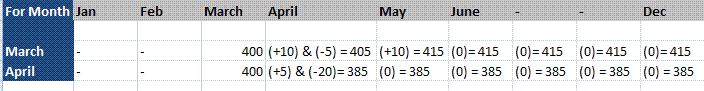
回答 3
Stack Overflow用户
发布于 2012-04-26 12:22:32
我可以看到你需要两张桌子的原因:
实际员工必须有名称、部门等,而预测员工可能只有这些attributes
- there才是真正员工才能承担的职责,因此您希望能够单独引用这些职责(
)。
但同时,您希望确保两个表之间不存在ID冲突,因为(希望)预测员工将成为实际雇员。
这样做的方法是实现一个超级/子类型的结构。因此,您有一个表,即保证单个主键的员工,以及两个用于实际和预测雇员的依赖表。类型列的使用至关重要,因为它确保给定的员工只出现在一个子表中。
create table employees
( emp_id number not null
, emp_type varchar2(8) not null
, constraint emp_pk primary key (emp_id)
, constraint emp_uk unique (emp_id, emp_type)
, constraint emp_type_ck check (emp_type in ('FORECAST', 'ACTUAL'));
create table actual_employees
( emp_id number not null
, emp_type varchar2(8) not null
, name varchar2(30) not null
, deptno number(2,0) not null
, sal number(7,2) not null
, hiredate date not null
, constraint actemp_pk primary key (emp_id)
, constraint actemp_type_ck check (emp_type = 'ACTUAL')
, constraint actemp_emp_fk foreign key (emp_id, emp_type)
references emp (emp_id, emp_type)
deferrable initially deferred ;
create table forecast_employees
( emp_id number not null
, emp_type varchar2(8) not null
, name varchar2(30)
, deptno number(2,0)
, sal number(7,2)
, predicted_joining_date date
, constraint foremp_pk primary key (emp_id)
, constraint foremp_type_ck check (emp_type = 'FORECAST')
, constraint foremp_emp_fk foreign key (emp_id, emp_type)
references emp (emp_id, emp_type)
deferrable initially deferred ;所以钥匙看起来可能有点奇怪。父表具有主键和复合唯一键。主键保证EMP_ID的单个实例,惟一键允许我们在引用EMP_ID和EMP_TYPE的子表上构建外键。结合子表上的检查约束,这是因为它们引用父表上的唯一键,而不是其主键。此安排确保员工可以在FORECAST_EMPLOYEES或ACTUAL_EMPLOYEES中,但不能同时在两者中。
外键是可以推迟的,以便能够将预测的雇员转换为实际就业机会。这需要开展三项活动:
将记录从FORECAST_EMPLOYEES
- inserting中删除到ACTUAL_EMPLOYEES
- changing EMP_TYPE (而不是EMP_ID)中的
- 。
在延迟约束的情况下,同步操作2和3更容易。
另外,请注意,引用员工的其他外键约束应该使用主键而不是唯一键。如果这种关系关心的是雇员的类型,而不是应该链接到子表。
“好头疼”
欢迎来到数据建模的世界。这是一个大头痛。因为试图将混乱的现实融入一个干净的数据模型是很困难的:你需要明确的要求才能使它正确,并且理解什么是最重要的,这样你才能做出明智的妥协。
我在另一个问题的基础上提出了一种超级类型/子类型的方法,因为这似乎是处理两组数据的最佳方法:真正的雇员和名义上的雇员。我认为这两组需要区别对待。例如,我会坚持经理是真正的雇员。使用针对ACTUAL_EMPLOYEES的完整性约束很容易做到这一点,而使用包含这两种类型的雇员的单个表则更难实现。
当然,拥有两个表意味着在同步它们的结构方面可能会产生更多的工作。那又怎么样?这在很大程度上是微不足道的,因为编写两个ALTER语句要比编写一个ALTER语句的工作量要小得多。此外,新列很可能只适用于实际员工,对预测员工没有任何意义(例如EARNED_COMMISSION、LAST_REVIEW_RATING)。因此,有了单独的表,数据模型就更准确了。
关于必须复制相关表,正如Ollie所指出的,这是一个误解。适用于所有员工的表格,无论其实际情况如何,都应该引用employees表,而不是其子表。
最后,我不明白为什么用两个表来维护历史数据比用一个表更困难。大多数日志记录代码应该完全从数据字典中生成。
“如果我有雇员表和Employee_forecast表.”
有三张桌子:
EMP_IDs
- ACTUAL_EMPLOYEES
- EMPLOYEES --保证唯一的
- 的主表--为为您的company
- FORECAST_EMPLOYEES工作的人提供的子表,为您希望招聘到公司
的人提供的子表。
“.它们的产品或活动都将存储在一个产品/活动表中?”
请记住,我是根据您提供的很少的细节对您的业务逻辑进行假设。
现在在我看来,那些还没有为贵公司工作的人不应该有任何相关的活动。在这个场景中,您将有一个表,EMPLOYEE_ACTIVITIES,它是ACTUAL_EMPLOYEES的一个子表。
但也许你真的为那些不存在的人举办了活动。所以这里有一个选择:一张桌子还是两张桌子?一个表的设计将EMPLOYEE_TASKS作为主雇员表的子表。这两个表设计分别将ACTUAL_EMPLOYEE_TASKS和FORECAST_EMPLOYEE_TASKS作为ACTUAL_EMPLOYEES表和FORECAST_EMPLOYEES表的子表。
哪个设计是正确的取决于您是否需要强制执行有关任务分配的规则。例如,您的公司可能有一条规定,即只有真正的人才能雇用新员工。因此,有一个只允许将招聘任务分配给ACTUAL_EMPLOYEES的模型是有用的。
“此设计对逐月预测没有任何考虑”
好的,我在这两个表中添加了日期列。这将允许您运行您想要的报告。
Stack Overflow用户
发布于 2012-04-26 12:25:43
我认为您的数据模型将取决于您需要报告的信息。例如,我倾向于使用标准的EMPLOYEE表和DEPARTMENT表(比如Oracle SCOTT模式)。
我还将有一个状态栏,您可以在该列中表示雇员是当前雇员或潜在雇员,从而允许您报告当前的雇用情况和预测雇用情况。您可以根据员工的状态添加功能约束/业务规则,以便当前的员工有全名、道布等,而潜在的员工可能没有。
然后,我还将创建一个审计表来跟踪EMPLOYEE记录所经历的更改。这将使您能够追溯地发现他们部门的更改,以及记录员工从预期员工更改到当前员工等,以及对EMPLOYEE记录中其他数据的任何更改。
它还具有将所有数据保存在一个位置的优点。如果需要,还可以考虑使用status列对EMPLOYEE表进行分区。
这将给您带来的好处是,在您的应用程序中的各个雇用阶段,每个员工在整个过程中只向他们颁发一个ID。
status列的另一个好处是,您可以介绍员工将来可能经历的任何其他阶段。
编辑:
这还将确保,如果您以后需要添加列,您只需支持一个表结构。
Stack Overflow用户
发布于 2012-04-26 11:45:23
下面是我要做的事情: Employee和Department是典型的,但是emp表中的dept_id没有一个emp_dept表来表示员工和部门之间的多到多的关系的生效日期或生效日期范围。对于perspective_employees,我建议使用一个单独的表,其中包含日期,然后当您需要该信息时,将它与employee表合并。
在这里很难得到真正的细节,但我希望你了解我所说的基本知识。
你好,罗杰
https://stackoverflow.com/questions/10332611
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号