
如何启用请求异步模式?
对于此代码:
import sys
import gevent
from gevent import monkey
monkey.patch_all()
import requests
import urllib2
def worker(url, use_urllib2=False):
if use_urllib2:
content = urllib2.urlopen(url).read().lower()
else:
content = requests.get(url, prefetch=True).content.lower()
title = content.split('<title>')[1].split('</title>')[0].strip()
urls = ['http://www.mail.ru']*5
def by_requests():
jobs = [gevent.spawn(worker, url) for url in urls]
gevent.joinall(jobs)
def by_urllib2():
jobs = [gevent.spawn(worker, url, True) for url in urls]
gevent.joinall(jobs)
if __name__=='__main__':
from timeit import Timer
t = Timer(stmt="by_requests()", setup="from __main__ import by_requests")
print 'by requests: %s seconds'%t.timeit(number=3)
t = Timer(stmt="by_urllib2()", setup="from __main__ import by_urllib2")
print 'by urllib2: %s seconds'%t.timeit(number=3)
sys.exit(0)这一结果:
by requests: 18.3397213892 seconds
by urllib2: 2.48605842363 seconds在sniffer中,它看起来如下:
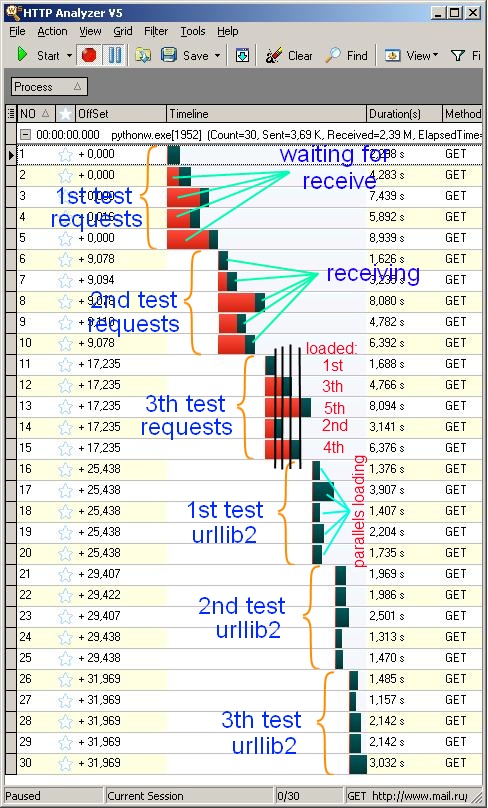
描述:前5个请求由请求库发送,接下来5个请求由urllib2库发送。当工作被冻结,黑暗-当数据接收.什么?!
如果套接字库有补丁和库必须相同工作,它是如何定位的?如何在没有requests.async的情况下使用请求进行异步工作?
回答 5
Stack Overflow用户
发布于 2012-03-05 08:45:28
不好意思肯尼斯·里茨。他的图书馆很棒。
我太蠢了。我需要为httplib选择如下的猴子补丁:
gevent.monkey.patch_all(httplib=True)因为httplib的修补程序默认是禁用的。
Stack Overflow用户
发布于 2012-03-01 23:00:02
正如肯尼斯指出的那样,我们可以做的另一件事是让requests模块处理异步部分。我对您的代码做了相应的更改。同样,对我来说,结果一致地表明requests模块的性能优于urllib2模块。
这样做意味着我们不能“线程”回调部分。但是,这应该是可以的,因为由于请求/响应延迟,HTTP请求的主要收益应该是预期的。
import sys
import gevent
from gevent import monkey
monkey.patch_all()
import requests
from requests import async
import urllib2
def call_back(resp):
content = resp.content
title = content.split('<title>')[1].split('</title>')[0].strip()
return title
def worker(url, use_urllib2=False):
if use_urllib2:
content = urllib2.urlopen(url).read().lower()
title = content.split('<title>')[1].split('</title>')[0].strip()
else:
rs = [async.get(u) for u in url]
resps = async.map(rs)
for resp in resps:
call_back(resp)
urls = ['http://www.mail.ru']*5
def by_requests():
worker(urls)
def by_urllib2():
jobs = [gevent.spawn(worker, url, True) for url in urls]
gevent.joinall(jobs)
if __name__=='__main__':
from timeit import Timer
t = Timer(stmt="by_requests()", setup="from __main__ import by_requests")
print 'by requests: %s seconds'%t.timeit(number=3)
t = Timer(stmt="by_urllib2()", setup="from __main__ import by_urllib2")
print 'by urllib2: %s seconds'%t.timeit(number=3)
sys.exit(0)这是我的结果之一:
by requests: 2.44117593765 seconds
by urllib2: 4.41298294067 secondsStack Overflow用户
发布于 2012-03-01 19:44:33
请求已将gevent支持集成到代码库中:
http://docs.python-requests.org/en/latest/user/advanced/#asynchronous-requests
https://stackoverflow.com/questions/9501663
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号