
图算法解做得对吗?
我偶然发现了上一次Facebook黑客杯的问题(所以这不是我的家庭作业,我只是觉得它很有趣),我也想到了一个好奇的,但相当不错的解决方案。你能检查一下我的想法吗?以下是一项任务:
给你一个网络,有N个城市和M个双向道路连接这些城市。第一个K城市很重要。您需要移除最少数量的道路,以便在剩余的网络中没有包含重要城市的循环。循环是至少三个不同城市的序列,使得每一对相邻城市通过一条道路连接,序列中的第一个和最后一个城市也通过一条道路连接起来。
输入
第一行包含测试用例T的数量。
每种情况都以一条包含整数N、M和K的线开始,它们分别代表城市的数目、道路的数目和重要城市的数目。城市编号从0到N1,重要城市编号从0到K-1。下面的M行包含两个整数ai和bi,0≤i< M,它们代表通过道路连接的两个不同城市。
保证了0≤ai,bi
输出
对于按1到T顺序编号的每个测试用例,输出"Case #i:“后面跟着一个整数,这是需要移除的最小道路数,这样就没有包含重要城市的循环。
约束
1≤T≤20
1≤N≤10000
1≤M≤50000
1K≤N≤示例
在第一个例子中,我们有通过N=5公路连接的M=7城市,而城市0和1非常重要。我们可以拆除连接(0,1)和(1,2)的两条道路,剩下的网络将不包含与重要城市之间的循环。请注意,在剩下的网络中,只有一个周期只包含不重要的城市,并且有多种方法可以移除两条道路并满足所有条件。一个人不能只拆除一条道路,摧毁所有包含重要城市的循环。
示例输入
1
5 7 2
0 1
1 2
1 4
0 2
2 4
2 3
3 4
所以我是这样想的:在构建图表时,让我们有一个单独的数组来存储每个城市有多少邻居的信息(==how --许多道路都连接到给定的城市)。在示例中,城市0有2,城市1有3等等。让我们把这个数字称为一个特定城市的“城市价值”。
在获得整个输入后,我们遍历整个城市值数组,寻找值为1的城市。当到达城市值时,意味着它不可能处于一个循环中,因此我们减少了它的值,“删除”(不失去一般性)连接到其唯一邻居的道路,并降低邻居的值。在此之后,我们递归地去邻居那里检查相同的东西,如果值是1-重复该方案,然后递归地进行更深入的检查。如果不是-别碰。
在该操作之后,我们清除了图的所有部分,这些部分不是循环,也不能是循环的一部分。我们也摆脱了所有的道路拆除,这是没有任何意义的。所以我们称之为另一种功能,这一次只在重要的城市工作。所以我们取顶点1--在使用上一段中描述的函数之后,它的值不能是1(因为它已经被函数变为零了),所以它要么是0,要么是什么>1。在第一个例子中,我们不需要做任何事情。在后一种情况下,我们必须使值1,这是通过执行值-1清除。类似于前一段,每次拆除后,我们都会降低这个城市和它的邻居的价值,同时也拆除这条路。我们重复一遍所有的k个重要城市,总结所有重要城市的价值-1,这就是我们的答案。
这有什么意义吗?对于所有的测试,我已经试过了,我想相信它是正确的,但不知怎么的,我觉得在某个地方可能有漏洞。能帮我查一下吗?有什么好处吗?如果没有,为什么这个思维过程是正确的?:)
回答 3
Stack Overflow用户
发布于 2012-02-07 17:48:35
这是一个不正确的解决方案。
Counterexample用于您的解决方案。假设,正方形的那个是唯一重要的。你的解决方案会删除一条路。
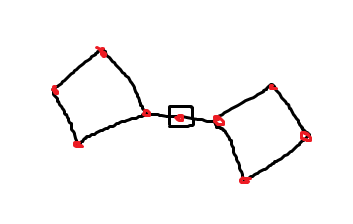
Stack Overflow用户
发布于 2012-02-08 00:03:05
如果您可以证明最佳割集数等于包含一个重要节点的不同循环的数目,那么解决这个问题并不困难。
您可以执行DFS,跟踪已访问的节点,并且无论何时到达您已经访问过的节点,您都会得到一个循环。要判断循环是否包含重要节点,请跟踪访问每个节点的深度,并记住搜索当前分支中最后一个重要节点的深度。如果周期的起始深度小于(即早期)上一个重要节点的深度,则周期包含一个重要节点。
C++实现:
// does not handle multiple test cases
#include <iostream>
#include <vector>
using namespace std;
const int MAX = 10000;
int n, m, k;
vector<int> edges[MAX];
bool seen[MAX];
int seenDepth[MAX]; // the depth at which the DFS visited the node
bool isImportant(int node) { return node < k; }
int findCycles(int node, int depth, int depthOfLastImp)
{
if (seen[node])
{
if (seenDepth[node] <= depthOfLastImp && (depth - seenDepth[node]) > 2)
{
// found a cycle with at least one important node
return 1;
}
else
{
// found a cycle, but it's not valid, so cut this branch
return 0;
}
}
else
{
// mark this node as visited
seen[node] = true;
seenDepth[node] = depth;
// recursively find cycles
if (isImportant(node)) depthOfLastImp = depth;
int cycles = 0;
for (int i = 0; i < edges[node].size(); i++)
{
cycles += findCycles(edges[node][i], depth + 1, depthOfLastImp);
}
return cycles;
}
}
int main()
{
// read data
cin >> n >> m >> k;
for (int i = 0; i < m; i++)
{
int start, stop;
cin >> start >> stop;
edges[start].push_back(stop);
edges[stop].push_back(start);
}
int numCycles = 0;
for (int i = 0; i < m; i++)
{
if (!seen[i])
{
// start at depth 0, and last important was never (-1)
numCycles += findCycles(i, 0, -1);
}
}
cout << numCycles << "\n";
return 0;
}*所谓“不同”,我的意思是,如果一个循环的所有边都已经是不同周期的一部分,它就不算在内。在下面的示例中,我认为循环数是2,而不是3:
A–B
| |
C–D
| |
E–FStack Overflow用户
发布于 2012-02-08 06:50:12
我的算法基于以下观察:因为我们不关心只包含不重要的节点的循环,所以不重要的节点可以折叠。我们将两个相邻的不重要的节点折叠,用一个不重要的节点替换为原始节点的边之和。
在折叠两个不重要的节点时,我们需要处理两个特殊情况:
- 两个节点都连接到同一个不重要的节点U上,这意味着在原始图中存在一个不重要的节点的循环,我们可以忽略这个循环,而新的节点将被连接到同一个不重要的节点U上。
- 两个节点都连接到同一个重要的节点I。这意味着原始图中存在一个不重要的节点和单个重要的节点I的循环;在折叠这些节点之前,我们需要删除连接到重要<代码>E 227>节点I的一条边,从而消除循环;新节点将连接到
E 128重要<代码>E 229节点i,并具有单个边缘。H 230G<231/code>
根据上述节点折叠的定义,该算法是:
继续折叠相邻的不重要的节点,直到没有相邻的不重要的节点为止。如上文(2)所定义的,在solution.Find中删除了重要和不重要的节点之间的所有边,将剩余图的生成树计算在内,并删除不包含在生成树中的所有边缘。在此步骤中移除的所有边缘都指向解决方案。
该算法在O(M)时间内运行。我相信我可以证明它是正确的,但我想在我花太多时间在它上之前得到你的反馈:)
https://stackoverflow.com/questions/9180871
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号