
用Python解析Word文档
我想把一个word文档转换成文本。所以我用了剧本。
import win32com.client
app = win32com.client.Dispatch('Word.Application')
doc = app.Documents.Open(r'C:\Users\SBYSMR10\Desktop\New folder (2)\GENERAL DATA.doc')
content=doc.Content.Text
app.Quit()
print content我的结果是:
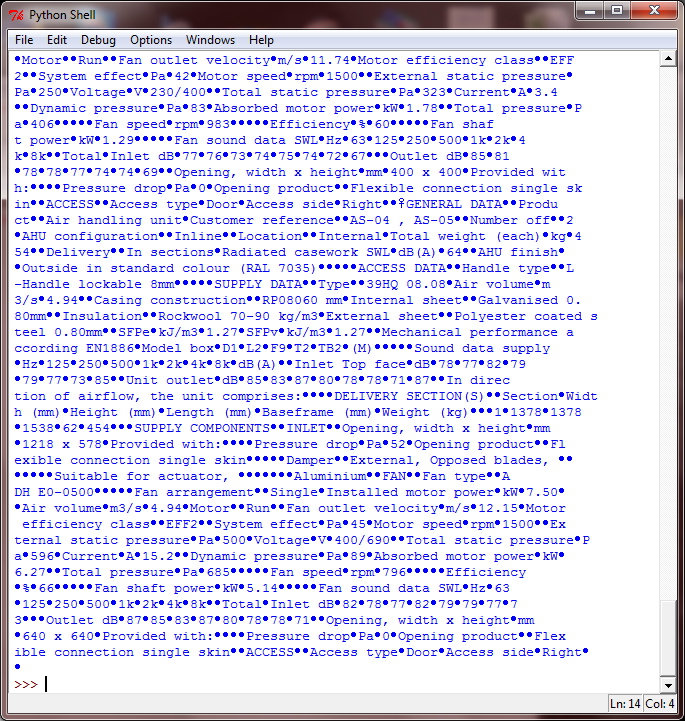
现在我想把这个文本转换成一个包含所有项目的列表。我用过
content = " ".join(content.replace(u"\xa0", " ").strip().split())编辑
当我这么做的时候,我得到:
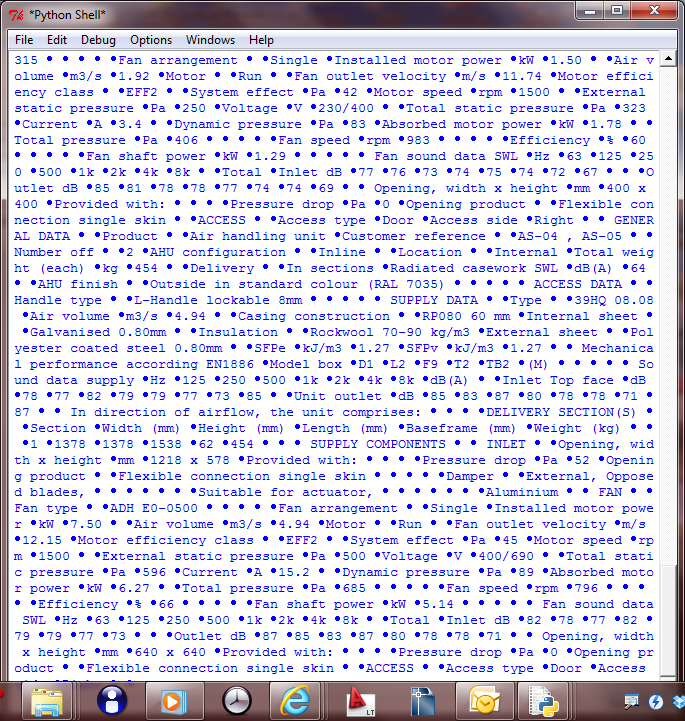
这不是一份名单。有什么问题吗?那个大点字是什么?
回答 4
Stack Overflow用户
发布于 2011-12-27 08:33:21
Word文档不是文本,而是文档:它们有控制信息(如格式)和文本。如果忽略控制信息,文本将非常无用。
因此,您必须深入了解细节,如何导航文档的控制结构,以找到您感兴趣的文本,然后获取该结构的文本内容。
注意:你会发现这个词非常复杂。如果可以的话,也可以考虑这两种方法:
- 将Word文档从Word中保存为HTML。它将失去一些格式,但列表将保持原样。HTML的解析和理解比Word简单得多。
- 将文档保存为OOXML (至少从Office 10开始就存在,扩展名是
.docx)。这是一个包含XML文档的ZIP归档文件。XML比完整的Word文档更容易解析/理解,但比HTML版本更难。
Stack Overflow用户
发布于 2011-12-27 09:16:06
现在我想把这个文本转换成一个包含所有项目的列表。我用过 content = ".join(content.replace(u"\xa0",“").strip().split()) 这不是一份名单。有什么问题吗?
.join方法总是返回字符串。。它希望您传递一个列表,然后将该列表与给定的分隔符(“”在您的情况下)连接起来。
除此之外,亚伦·迪古拉说的话。
Stack Overflow用户
发布于 2011-12-27 09:37:01
请查看此链接中的帖子及其注释:将Word文档转换为文本(Python食谱)
另外,这篇文章可能很有用:python将microsoft office文档转换为linux上的纯文本。
https://stackoverflow.com/questions/8642415
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号