
防止xml.etree.ElementTree.xml( )在元素标记中包含网站名称
防止xml.etree.ElementTree.xml( )在元素标记中包含网站名称
提问于 2011-12-19 02:19:50
我正在使用python,并试图获取一些XML并将其转换为一个小块。代码工作正常,只是将一些奇怪的文本添加到元素标记中,然后添加到dict属性名称中。本文似乎是"WebServiceGeocodeQueryResult“属性"xmlns”的值。
我的代码如下所示:
import xml.etree.ElementTree as ET
import xml_to_dictionary # This is some code I found, it seems to work fine:
# http://code.activestate.com/recipes/410469-xml-as-dictionary/
def doSomeStuff()
theXML = """
<?xml version="1.0" encoding="utf-8"?>
<WebServiceGeocodeQueryResult
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns="https://webgis.usc.edu/">
<TransactionId>7307e84c-d0c8-4aa8-9b83-8ab4515db9cb</TransactionId>
<Latitude>38.8092475915888</Latitude>
<Longitude>-77.2378689948621</Longitude>
...
"""
tree = ET.XML(result.content) # this is where the element names get the added '{https://webgis.usc.edu/}'
xmldict = xml_to_dictionary.XmlDictConfig(tree)(如您在调试器中所看到的),对象"tree“中的元素名具有烦人的前缀: "{https://webgis.usc.edu/}":
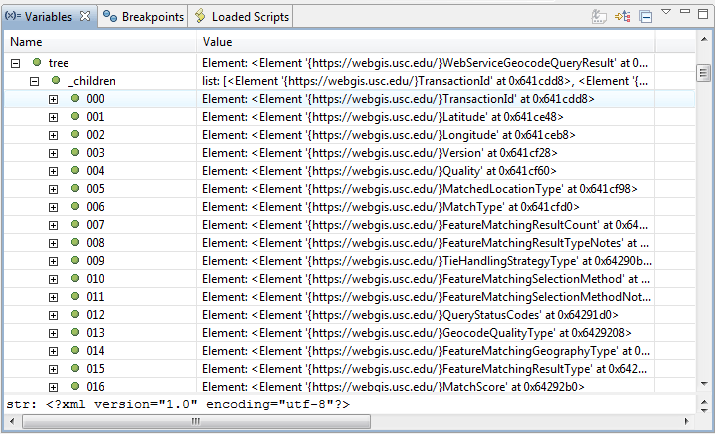
和此前缀被转换为dict属性名称:。
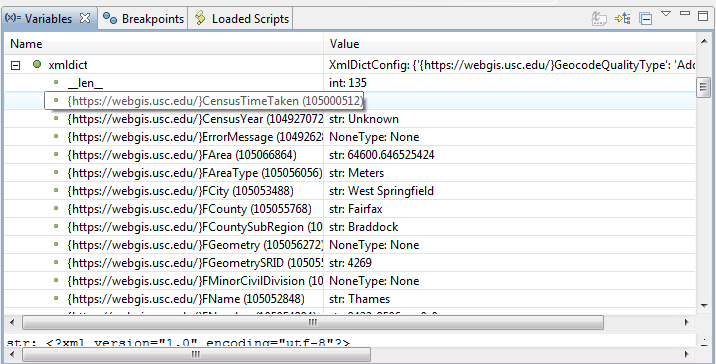
回答 1
Stack Overflow用户
回答已采纳
发布于 2011-12-19 03:22:22
“奇怪的文本”是元素的命名空间。ElementTree expands element names to .
您可以像这样对元素名进行预处理:
tree = ET.XML(thexml)
et = ET.ElementTree(tree) # this is to include root node
for elem in et.getiterator(): #in python 2.7 or greater, getiterator() is unnecessary
elem.tag = elem.tag.split('}', 1)[-1]另外,如果cElementTree可用,您应该使用它,因为它会更快。(import xml.etree.cElementTree as ET)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/8556501
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号