
马歇尔转储更快,cPickle装载更快
我正在实现一个需要序列化和反序列化大型对象的程序,所以我使用pickle、cPickle和marshal模块进行了一些测试,以选择最佳的模块。一路走来,我发现了一件非常有趣的事情:
我使用的是dumps,然后是loads (对于每个模块),它们都是在一个数据库、元组、ints、浮点数和字符串列表中使用的。
这是我基准的输出:
DUMPING a list of length 7340032
----------------------------------------------------------------------
pickle => 14.675 seconds
length of pickle serialized string: 31457430
cPickle => 2.619 seconds
length of cPickle serialized string: 31457457
marshal => 0.991 seconds
length of marshal serialized string: 117440540
LOADING a list of length: 7340032
----------------------------------------------------------------------
pickle => 13.768 seconds
(same length?) 7340032 == 7340032
cPickle => 2.038 seconds
(same length?) 7340032 == 7340032
marshal => 6.378 seconds
(same length?) 7340032 == 7340032因此,从这些结果中我们可以看到,marshal在基准测试的倾卸部分中非常快:
比
pickle快14.8倍,比cPickle快2.6倍。
但是,令我惊讶的是,marshal在 than 部分比cPickle慢得多:
比
pickle快2.2倍,比cPickle慢3.1倍。
至于内存,marshal性能在加载时也非常低效:
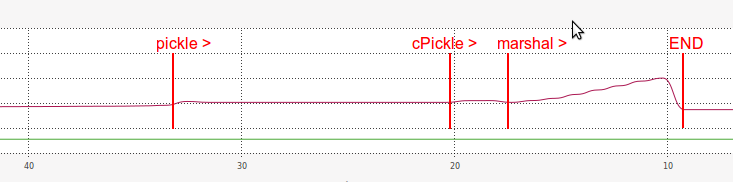
我猜想使用marshal加载如此缓慢的原因与其序列化字符串的长度有关(比pickle和cPickle长得多)。
- 为什么
marshal转储速度更快,加载速度更慢? - 为什么
marshal序列化字符串这么长? - 为什么
marshal在内存中的加载效率这么低? - 有办法提高
marshal的加载性能吗? - 有办法将
marshal快速转储与cPickle快速加载合并吗?
回答 6
Stack Overflow用户
发布于 2011-12-18 13:49:39
cPickle有一个比marshal更聪明的算法,并且能够做一些技巧来减少大型对象所使用的空间。这意味着解码速度较慢,但编码速度较快,因为结果输出较小。marshal是简单化的,它将对象直接序列化为- is,而不做任何进一步的分析。这也解释了为什么marshal加载效率如此之低,它只需做更多的工作--比如从磁盘读取更多的数据--才能与cPickle做同样的事情。
marshal和cPickle实际上是完全不同的,您不能同时获得快速保存和快速加载,因为快速保存意味着对数据结构进行更少的分析,这意味着将大量数据保存到磁盘。
关于marshal可能与其他版本的Python不兼容的事实,您通常应该使用cPickle。
“这不是一个通用的”持久性“模块。要通过RPC调用实现Python对象的一般持久性和传输,请参阅模块的筛选和搁置。封送模块的存在主要是为了支持读取和编写.pyc文件的Python模块的”伪编译“代码。因此,Python维护人员保留在需要时以向后不兼容的方式修改封送件格式的权利。如果您正在序列化和反序列化Python对象,则使用泡菜模块代替--性能相当,版本独立性得到保证,并且泡菜支持的对象范围比封送组大得多。”(蟒蛇有关于元帅的文件)
Stack Overflow用户
发布于 2012-02-14 00:16:38
有些人可能认为这是一次黑客攻击,但我通过简单地用gc.disable()和gc.enable()包装泡菜转储调用获得了巨大的成功。例如,下面编写一个~50 to字典列表的代码片段从78秒到4秒不等。
# not a complete example....
gc.disable()
cPickle.dump(params,fout,cPickle.HIGHEST_PROTOCOL)
fout.close()
gc.enable()Stack Overflow用户
发布于 2011-12-23 11:24:48
这些基准之间的差异为加速cPickle提供了一个想法:
Input: ["This is a string of 33 characters" for _ in xrange(1000000)]
cPickle dumps 0.199 s loads 0.099 s 2002041 bytes
marshal dumps 0.368 s loads 0.138 s 38000005 bytes
Input: ["This is a string of 33 "+"characters" for _ in xrange(1000000)]
cPickle dumps 1.374 s loads 0.550 s 40001244 bytes
marshal dumps 0.361 s loads 0.141 s 38000005 bytes在第一种情况下,列表重复相同的字符串。第二个列表是等价的,但是每个字符串都是一个单独的对象,因为它是表达式的结果。现在,如果您最初是从外部源读取数据,则可以考虑某种类型的字符串去重复。
https://stackoverflow.com/questions/8514020
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号