
使用Mahout的K均值聚类
使用Mahout的K均值聚类
提问于 2011-11-25 17:01:47
我使用给定这里的聚类技术对大型数据集进行聚类,这在Mahout示例中给出。然而,当我可视化特定的集群时,我得到了下面的图。
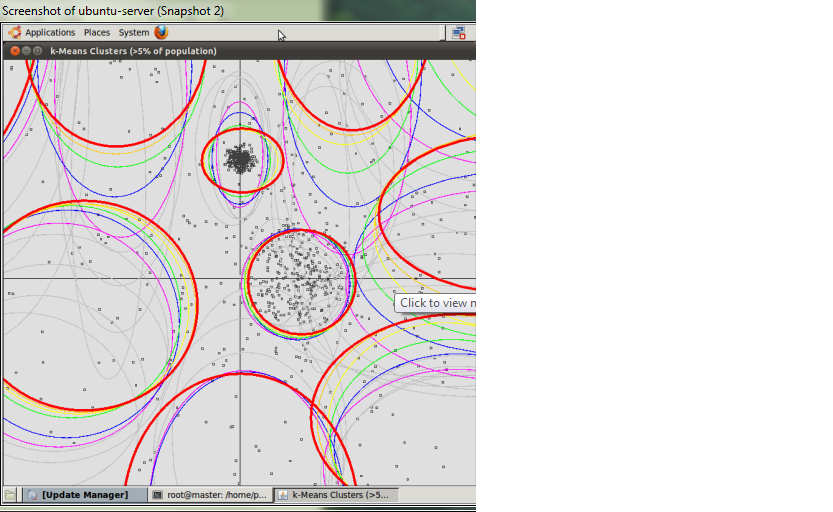
我真的很难理解这意味着什么,我有几个问题。
- 所有的彩色线条都表明了什么?
- 这么多星系团意味着什么?
- 为什么很少有区域拥挤,为什么其他区域不拥挤?
- 为什么很少有彩色线条互相重叠?
回答 1
Stack Overflow用户
回答已采纳
发布于 2011-11-25 22:00:14
K-均值并不是最先进的聚类技术.圆圈作为一种可视化技术是有误导性的,它实际上是将数据空间划分为Voronoi单元(在Wikipedia上查找)。它也更喜欢类似规模的集群。
- 我假设不同的颜色表示k-均值的不同迭代。它需要几次运行才能优化其结果(通常只达到局部最小值,不同的运行将导致不同的结果)。所以结果还不是很稳定,我想。它们的移动速度很慢,这就是它们不太重叠的原因。
- 簇数是k-均值的一个参数.它通常被表示为
k。k -表示无法确定集群的数量,但如果您使用多个k值运行,则可以测试哪一个结果最适合数据集。 - 意思是不看密度。你需要一个基于密度的聚类算法。K-表示更喜欢相似大小的星系团。你的"k“可能太高了。
- 因为它们是迭代更新的,所以不同的迭代不应该有太多的重叠。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/8272184
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号