
在使用单个和多个数据库时,性能有什么提高吗?
我们正在构建一个软件,它接收每个系统大约每天发送一次的大约100个数据项的预先计算的小时平均值。可能有20多个客户使用5-50个系统。所以理论上的最大值大约是100 * 24 * 20 * 50 =每天插入的2400000行。
每天不太可能有那么多插入,但这是我们需要记住的事情。
如果我们拆分数据库结构,使每个客户都有自己的数据库,就像在最后一张图片中一样,那么性能会有提高吗?在共享数据库中,将有用户及其与数据库的关联。
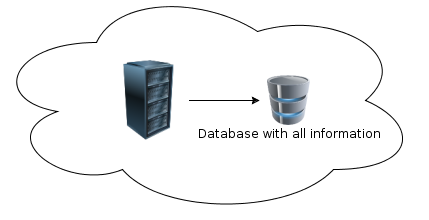
或
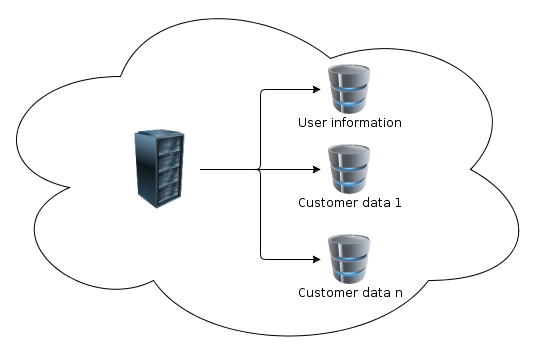
更新
数据将保存约2-3年,然后系统将自动删除旧数据.用户不会删除“任何”,在这种情况下,任何内容都意味着从客户系统发送的数据。
更新2
在图像中,服务器和数据库周围有云。更具体地说:云是Microsoft云计算的实现。
回答 4
Stack Overflow用户
发布于 2011-10-27 07:37:59
如果每个客户只使用自己的数据工作,而不需要访问其他客户数据,那么我认为,由于表锁只会影响一个客户的数据,因此,当客户A在表上运行级联删除时,其他客户仍然能够读取和修改各自数据库中相同表中的数据。如果没有这样的拆分,表锁会影响到所有。
尽管如此,拆分数据库将使管理(备份、修改数据库结构、更新数据库地址等)更加麻烦和容易出错。
您可以从一个数据库开始,保存所有数据。然后,如果您发现客户经常等待其他客户操作完成,则可以拆分数据库;如果您正确地抽象了数据库访问,则不需要对代码进行重大更改。
记住,过早的优化是万恶之源!
Stack Overflow用户
发布于 2011-10-27 08:58:00
如果数据库位于不同的物理磁盘上,则在数据的读写方面都会有性能提高。如果它们位于相同的磁盘/服务器上,那么性能增益就太小而不需要操心。另一方面,如果您使用多台服务器,重要的问题是您可以并行地查询它们吗?如果你做不到,很可能你就不会从你的表现中得到尽可能多的好处。
有许多插入是一种I/O绑定操作,因此您必须优化磁盘访问。在不同磁盘上拆分负载是最好的方法,但如果不能,仍然可以提高性能:
- 确保写是只附加的。在MySQL/InnoDB中,数据按主键的顺序存储,因此使用自动增量来避免随机写入。在其他关系数据库管理系统中,您可以选择集群键,因此,如果可以的话,明智地选择
- ,将数据保存在一个dist上,并在另一个磁盘上存储日志--如果您可以拆分读写(主/从复制),那么
- 将有效地将负载分成2个磁盘,因此主服务器将只忙于编写
。
Stack Overflow用户
发布于 2011-10-27 09:00:04
一个更好、更通用的解决方案是运行一个主db和几个从数据库(只读,自动与主数据库同步) dbs。更新被发送到主服务器,但是selects沿着所有dbs分布(因为selects将得到相同的结果,不管查询在哪里运行)。
有许多产品可以做到“开箱即用”,无论是开源还是商业。
https://stackoverflow.com/questions/7912544
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号