
Solr:使用EdgeNGramFilterFactory进行准确的短语查询
在Solr (3.3)中,是否有可能使字段逐个字母通过EdgeNGramFilterFactory进行搜索,同时对短语查询也很敏感?
例如,我正在寻找一个字段,如果包含“containing”,如果用户输入:
- 反制
- 信息化
- 康德
- informa
- “对比信息”
- “控制信息”
目前,我做了这样的事情:
<fieldtype name="terms" class="solr.TextField">
<analyzer type="index">
<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-ISOLatin1Accent.txt"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="2" maxGramSize="15" side="front"/>
</analyzer>
<analyzer type="query">
<charFilter class="solr.MappingCharFilterFactory" mapping="mapping-ISOLatin1Accent.txt"/>
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<tokenizer class="solr.LowerCaseTokenizerFactory"/>
</analyzer>
</fieldtype>...but在短语查询中失败。
当我查看solr admin中的模式分析器时,我发现"contrat“生成了以下标记:
[...] contr contra contrat in inf info infor inform [...]因此,该查询使用"contrat“(连续令牌),而不使用"contrat”(因为这两个标记是分开的)。
我确信任何类型的词干都可以用于短语查询,但我无法在EdgeNGramFilterFactory之前找到正确的过滤器标记器。
回答 4
Stack Overflow用户
发布于 2011-10-07 08:29:50
遗憾的是,我无法像Jayendra建议的那样正确地使用PositionFilter (PositionFilter使任何查询成为一个或布尔的查询),我使用了另一种方法。
对于EdgeNGramFilter,我添加了一个事实,即用户输入的每个关键字都是强制性的,并且禁用了所有短语。
因此,如果用户请求"cont info",它将转换为+cont +info。一个真正的短语更容易理解,但它成功地做到了我想做的事情(并且不返回结果,其中只有一个词)。
唯一反对这一解决办法的是,术语可以在结果中转换(因此也会找到一份带有“信息对比”的文档),但这并不是什么大不了的事情。
Stack Overflow用户
发布于 2012-02-08 20:09:59
确切的短语搜索不起作用,因为默认情况下,查询slop参数=0。搜索一个短语“Hello”,它搜索具有顺序位置的术语。我希望EdgeNGramFilter有一个参数来控制输出定位,这看起来像一个旧的问题。
通过将qs参数设置为一些非常高的值(大于ngram之间的最大距离),您可以将短语返回。这部分解决了问题,允许短语,但不是确切的,置换也会被发现。因此,搜索“反向信息”将匹配文本,如"...contract废弃。信息.“
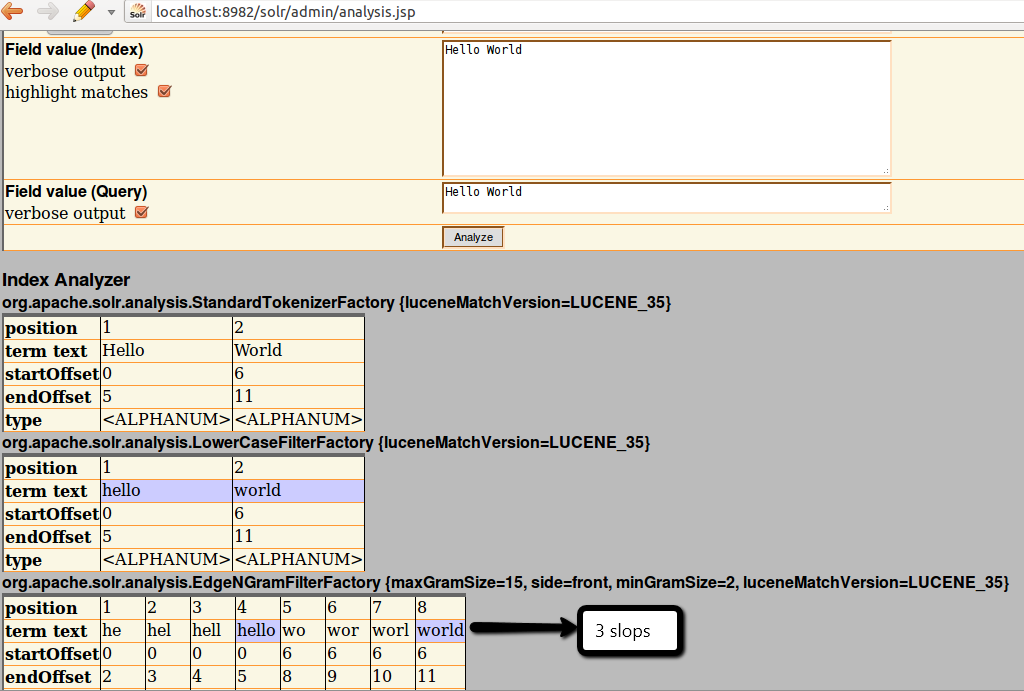
为了支持精确的短语查询,我最终使用了ngrams的单独字段。
需要步骤:
定义单独的字段类型以索引正则值和克:
<fieldType name="text" class="solr.TextField" omitNorms="false">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="ngrams" class="solr.TextField" omitNorms="false">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="2" maxGramSize="15" side="front"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>索引时告诉solr到复制字段:
您可以为每个字段定义单独的ngram反射:
<field name="contact_ngrams" type="ngrams" indexed="true" stored="false"/>
<field name="product_ngrams" type="ngrams" indexed="true" stored="false"/>
<copyField source="contact_text" dest="contact_ngrams"/>
<copyField source="product_text" dest="product_ngrams"/>或者你可以把所有的纳克都放在一个字段里:
<field name="heap_ngrams" type="ngrams" indexed="true" stored="false"/>
<copyField source="*_text" dest="heap_ngrams"/>请注意,在这种情况下,您将无法分离助推器。
最后一件事是在查询中指定ngram字段和增强器。一种方法是配置应用程序。另一种方法是在solrconfig.xml中指定“追加”参数。
<lst name="appends">
<str name="qf">heap_ngrams</str>
</lst>Stack Overflow用户
发布于 2011-09-30 18:33:16
我是这么想的-
对于要匹配短语的ngram,为每个单词生成的标记的位置应该是相同的。
我检查了边缘图过滤器,它增加了令牌,但是没有找到任何参数来阻止它。
有一个位置过滤器可用,这将令牌位置保持在与起始标记相同的位置上。
因此,如果使用以下配置,则所有标记都位于相同的位置,并且与短语查询匹配(相同的标记位置与短语匹配)
我通过anaylsis工具检查了它,查询匹配。
所以你可以试试这个提示:-
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory" />
<charFilter class="solr.MappingCharFilterFactory"
mapping="mapping-ISOLatin1Accent.txt" />
<filter class="solr.WordDelimiterFilterFactory" generateWordParts="1"
generateNumberParts="1" catenateWords="1" catenateNumbers="1"
catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.EdgeNGramFilterFactory" minGramSize="2"
maxGramSize="15" side="front"/>
<filter class="solr.PositionFilterFactory" />
</analyzer>https://stackoverflow.com/questions/7612889
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号