
将概念上相似的文档聚在一起?
这更多是一个概念性的问题,而不是一个实际的实现,我希望有人能澄清。我的目标是:给定一组文档,我希望对它们进行聚类,使属于同一个集群的文档具有相同的“概念”。
据我所知,潜在语义分析让我找到一个项文档矩阵的低秩逼近,即给定一个矩阵X,它将X分解为三个矩阵的乘积,其中一个是对角矩阵Σ。
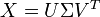
现在,我将选择一个低秩近似,即只从Σ中选择顶k值,然后计算X'。一旦我有了这个矩阵,我就必须应用一些聚类算法,最终的结果就是用相似的概念对文档进行聚类分组。这是应用集群的正确方式吗?我的意思是,计算X',然后在其之上应用集群,还是有其他方法被遵循?
另外,在我的相关问题中,我被告知,当维度的数量增加时,邻居的意义就失去了。在这种情况下,从X'对这些高维数据点进行聚类的理由是什么?我猜想,对类似文档进行集群的要求是一种现实世界的需求,在这种情况下,如何解决这个问题呢?
回答 1
Stack Overflow用户
发布于 2011-07-07 21:11:39
对于问题的第一部分:不,您不再需要执行任何“群集”了。这样的集群已经可以从您的singular value decomposition中获得。如果这还不清楚,请研究更详细的方式,您的链接潜在语义分析。
关于你的第二部分:请先弄清楚你问题的第一部分,然后在此基础上重新陈述你的问题的这一部分。
https://stackoverflow.com/questions/6615833
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号