
OCR软件能可靠地从表中读取值吗?
OCR软件是否能够可靠地将像下面这样的图像转换成值列表?
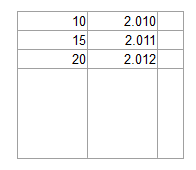
更新:
更详细的任务如下:
我们有一个客户端应用程序,用户可以在其中打开报表。此报告包含一个值表。但是并不是每个报表看起来都是相同的--不同的字体、不同的间距、不同的颜色,也许报表包含了许多具有不同行/列数的表.
用户选择报表中包含表的区域。用鼠标。
现在,我们希望使用OCR工具将选定的表转换为值。
当用户选择矩形区域时,我可以请求额外的信息来帮助OCR过程,并要求确认值是否正确。
它最初将是一个实验项目,因此最有可能使用OpenSource OCR工具--或者至少一个不需要花费任何费用用于实验目的的工具。
回答 8
Stack Overflow用户
发布于 2011-05-31 06:56:11
简单的回答是是的,你应该选择正确的工具。
我不知道开放源码在这些图片上是否能达到100%的准确率,但是根据这里的答案,可能是的,如果你花一些时间训练和解决表格分析的问题之类的事情。
当我们谈论商业OCR像ABBYY或其他,它将提供您的99%+准确性的盒子,它将自动检测表。没有训练,没有任何东西,只是起作用。缺点是你必须为它付费,$$。有些人会反对,对于开放源码,你要花时间来设置它,但是这里的每个人都是自己决定的。
然而,如果我们谈论商业工具,实际上还有更多的选择。这取决于你想要什么。像FineReader这样的盒装产品的目标实际上是将输入文档转换为Word或Excell之类的可编辑文档。由于您实际上希望获得数据,而不是Word文档,您可能需要查看不同的产品类别--数据捕获,这本质上是OCR加上一些额外的逻辑,以在页面上找到必要的数据。如果是发票,可以是公司名称、总额、到期日、表中的项目等。
数据捕获是一门复杂的学科,需要一定的学习,但适当的使用可以保证从文档中获取数据的精确性。它使用不同的规则进行数据交叉检查、数据库查询等。必要时可以发送数据进行手动验证。企业广泛使用数据捕获应用程序,每月输入数百万个文档,严重依赖于在其日常工作流程中提取的数据。
当然,还有OCR,这将使您能够访问API的识别结果,并且您将能够编程处理数据。
如果你能更详细地描述你的任务,我可以给你建议,哪个方向更容易去。
更新
因此,您所做的基本上是数据捕获应用程序,但不是完全自动化的,使用所谓的“点击索引”方法。市场上有很多这样的应用程序:扫描图像,操作员单击图像上的文本(或绘制矩形),然后将字段填充到数据库中。如果要处理的图像数量相对较少,而且手工工作负载不足以证明完全自动化应用程序的成本是合理的,这是一种很好的方法(是的,有些全自动系统可以处理不同字体、间距、布局、表中行数等的图像)。
如果您决定开发产品,而不是购买,那么您所需要的就是选择OCR。所有你要写自己的UI,对吗?最大的选择是决定:开源还是商业。
据我所知,最好的开放源码是tesseract OCR。它是免费的,但在表格分析方面可能存在实际问题,但使用手动分区方法,这不应该是问题所在。至于OCR的准确性-人们经常训练OCR的字体以提高准确性,但这不应该是你的情况,因为字体可能是不同的。所以你可以试着试试,看看你会得到什么样的准确性--这将影响手工工作的数量来纠正它。
商业OCR将提供更高的准确性,但将花费您的钱。我认为你无论如何都应该看看是否值得,或者对你来说已经足够好了。我认为最简单的方法是下载像FineReader这样的盒式OCR试用版。那么,您将很好地了解OCR的准确性。
Stack Overflow用户
发布于 2013-01-19 22:41:13
如果表中始终有坚实的边框,则可以尝试以下解决方案:
- 定位每个页面上的水平线和垂直线(黑色像素的长时间运行)
- 使用线坐标将图像分割成单元格。
- 清除每个单元格(删除边框,阈值为黑白)
- 在每个单元格上执行OCR
- 将结果组装成二维数组
否则,您的文档有一个无边界的表,您可以试着遵循这一行:
光学字符识别是相当惊人的东西,但它并不总是完美的。为了获得最好的结果,它有助于使用最干净的输入。在我的初步实验中,我发现只要去掉单元格边框(长的水平线和垂直线),对整个文档执行OCR实际上就能很好地工作。但是,该软件将所有空白压缩到一个单独的空空间中。由于我的输入文档有多个列,每个列中有几个单词,因此单元格边界正在丢失。保持单元格之间的关系是非常重要的,因此一个可能的解决方案是在每个单元格边界上绘制一个独特的字符,比如“^”-- OCR仍然会识别这一点,稍后我可以使用它来拆分产生的字符串。
我在这个链接中找到了所有这些信息,问谷歌"OCR to table“。作者发表了一种使用Python和Tesseract的完整算法,两个开源解决方案!
如果你想尝试使用Tesseract的能力,也许你应该试试这个网站:
http://www.free-ocr.com/
Stack Overflow用户
发布于 2011-05-30 07:34:30
你说的是哪一种OCR?
你是在开发基于OCR的代码,还是使用从货架上下来的东西?
金融时报:Tesseract OCR
它已经实现了文档读取可执行文件,因此您可以输入整个页面,并且它将为您提取字符。它很好地识别空格,它可能有助于制表符间距。
https://stackoverflow.com/questions/6173439
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号