
数学中的条件数据合并
我需要合并来自两个不同来源的数据,。下表说明了我所拥有的情况:
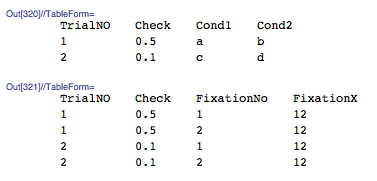
以及期望的产出:

这样做的目的是:
- 研究了第一个领域。Table1 (TrialNO)
- 在第一个目录中寻找它。Table2.
- 检查第二个col中的值。在现实中是平等的。如果通过检查,将不在2列表)
- 中相同的位置,并附加位于col中的值。3&4 (Cond1 & Cond2)到Table2.
- 中的行
**
编辑:精确地显示我的数据和目标的形状
**
我会给一些背景,我如何获得这些数据,以澄清其形状。我相信在技术上可以更准确地描述这一情况。请不要犹豫,请纠正我。
I正在记录眼球运动(扫视和固定),受试者在屏幕上显示刺激时回答一项任务。
- 每个试用版包含两次连续显示,每次显示3秒。它是一个2 2AFC (两种不同的强制choice).
- Each显示器,包括一个框架(屏幕的大约1/4大小),其中有8个形状,显示在screen.
- There的4个象限中有1个是框架本身构成的5个条件,因此每一次试验都可能有10个条件(1帧对另一个没有repetition).
- There的条件是2种标准:选择对象
我从两个不同的来源得到这些数据:
- "display“机器,提供
-Trial号码/显示号码
关于屏幕的-Informations
-Conditions
-Subject答案
-X &Y坐标以及构成所显示的刺激的11个对象的大小。
在此矩阵中,每一行都是一个显示,因此DisplayNO列将从1到400 (1,2,3,4,...,400),而TrialNO列实际上从1到200 (1,1,2,2,..,200,200),因为每次测试有2次显示。
"Eye-Tracking"机器
- 提供:
-Some类似的信息(显示号(1-400),将用于合并2,条件号,可以用来检查映射赌注。2)
然后是大量描述眼球运动的变量:
-Fixations和扫视时间、位置、时间等(约100列)
在这个矩阵中,每一行都是固定的,然后在列中给出扫视的特征(上一次和下一次),每次显示可以有1到30到50次固定。因此,我可以有19行数据用于第一次显示,5行用于第二次显示。
第一步是将2,2,2的数据结构合并,得到一个大的数据结构,每一行对应于一个fixation.
- Will,对每个主题都要这样做,然后将主题数据聚合到另一个主题上。
这是我以后对付这个怪物的计划(这将解释我在其他问题中的需要):
number.
- Present statistics.
- A按组提取标题和列,格式为-General Info (试用ID、条件、主题ID.)、-Display info (屏幕上对象的坐标)、-Fixations信息等.
- 对每个变量都有数据类型(字符串、数字、文本)、范围、列接受多少个不同的值以及一些基本的描述性statistics.
- A系统有条件地提取部分内容(例如:提取条件号、固定时间等)。)通过这种方式提取一些定义良好的表,然后在不触及原始数据的情况下对其进行分析。
如果我使用我的准确情况来提出我的问题,我相信,这可能会产生一个很好的,有效的,易于使用的工具,以处理大量的数据集在一般。
回答 3
Stack Overflow用户
发布于 2011-05-27 06:16:17
为了进行更好的优化,我期待着对您的数据进行更详细的描述。
checkMerge[src_, trg_, si_, ti_, sp_] :=
Module[{rls, ext},
rls = #[[si]] -> #[[sp]] & /@ src;
AppendTo[rls, _ -> {,}];
ext = Replace[trg[[All, ti]], Dispatch@rls, 1];
ArrayFlatten[{{trg, ext}}]
]语法是:
src=“源”列表(data1)trg=“目标”列表(data2)si=索引列表从源到compareti=索引列表从目标到comparesp=索引列表从源到目标
就您的例子而言,这将是:
checkMerge[data1, data2, {1,2}, {1,2}, {3,4}]我不得不猜测要适应的更改级别:
(实际上是这样的)。不会位于两个列表中相同的位置)
因此,这可能有太多或太少的特殊性。
目前,
- 必须是两个索引(列号)的列表,因为这使事情变得简单了一些,我不知道您想要什么。您希望指定从
data1中提取哪些元素并附加到data2,还是应该是在比较元素之后的所有元素,还是其他元素?如果有si、ti、sp的标准值,可以添加默认值,以便您可以省略这些元素,除非需要不同的值。 - 我假设扩展与
Null不匹配的行来创建矩形数组是可以的;如果您愿意的话,这些行可以在之后删除,以生成一个粗略的数组。H 234G 235
Stack Overflow用户
发布于 2011-05-26 16:38:17
以下是一种可能性:
MergeTables[data1_, data2_, samepos1_, samepos2_] :=
Cases[data1,
x_ :> Block[{y =
Cases[data2, z_ /; z[[samepos2]] === x[[samepos1]]]},
Apply[Sequence, Join[x, Delete[#, Thread[{samepos2}]]] & /@ y]]]用法:
MergeTables[data2, data1, {1, 2}, {1, 2}]Stack Overflow用户
发布于 2011-05-26 21:49:05
萨沙的回答太酷了,我甚至还不知道它是如何工作的。
这是我的尝试,作为一个比函数式程序员更多的结构化程序员,我使用了一个表OMG!来完成它。好吧,Table[]仍然处于函数式编程的边缘:)
(这里A是data2,B是data1)
n=Length[A]; m=Length[B];
isMatch[a_,b_] := a[[1]]=== b[[1]]&&a[[2]]===b[[2]]
A[[1]] = A[[1]]~Join~B[[1,3;;-1]]; (*do the header on its own*)
Table[If[ isMatch[B[[i]],A[[j]]],
A[[j]] = Join[A[[j]],B[[i,3;;-1]]]
],
{i,2,m},{j,2,n}
];
A//TableForm-纳赛尔
https://stackoverflow.com/questions/6141840
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号