
Delphi/Pascal (时态差异学习)中的TD(λ)
我有一个人工神经网络来玩Tic Toe,但它还没有完成。
我所拥有的:
- 奖励数组"Rt“包含每个时间步长或移动"t”的整数值(1=player A获胜,0=draw获胜,-1=player B获胜)
- 输入值通过网络正确传播。
- 调整权重的公式:
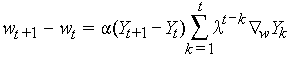
所缺少的:
- TD学习:我仍然需要一个使用TD(λ)算法“反向传播”网络错误的过程。
但我不太懂这个算法。
我的方法到目前为止.
跟踪衰变参数λ应该是"0.1“,因为远端状态不应该得到那么多的奖励。
两层(输入和隐藏)的学习率为"0.5“。
这是一种延迟奖励的情况:在游戏结束之前,奖励仍然是"0“。然后,第一人获胜时奖励为"1“,第二人获胜时为"-1”,在平局情况下为"0“。
我的问题:
- 如何以及何时计算网络的错误(TD错误)?
- 如何实现错误的“反向传播”?
- 如何使用TD(λ)调整权重?
(提前谢谢你:)
回答 3
Stack Overflow用户
发布于 2011-01-30 22:56:18
如果你是认真的让这个工作,那么了解TD将是非常有用的。Sutton和Barto的书“强化学习”是可免费获得HTML格式,详细介绍了这个算法。基本上,TD所做的就是在游戏状态和游戏结束时的预期回报之间创建一个映射。随着游戏的进行,更有可能导致州获胜的州往往会获得更高的预期奖励值。
对于一个简单的游戏,如抽搐-战术-脚趾,你最好从表格映射开始(只跟踪每个可能的游戏状态的预期奖励值)。然后,一旦完成了这一任务,就可以尝试使用NN作为映射。但我建议先尝试一个单独的,简单的NN项目.
Stack Overflow用户
发布于 2011-01-31 01:24:19
我也对此感到困惑,但我相信这就是它的工作方式:
从结束节点开始,检查R (接收到的输出)和E (预期的输出)。如果E= R,那就好了,你没有什么要做的改变。
如果E= R,你会看到它有多远,基于阈值和诸如此类的东西,然后将权重或阈值向上或向下移动一点。然后,根据新的权重,你返回,并猜测它是太高,还是太低,并重复,与一个较弱的效果。
我从未真正尝试过这个算法,但这基本上就是我所理解的想法的版本。
Stack Overflow用户
发布于 2011-02-08 21:14:34
据我所知,您使用已知的结果集进行培训--因此您计算已知输入的输出并从中减去已知的输出值--这就是错误。
然后你用这个错误来修正这个网络--对于一个用δ规则调整的单层NN,我知道0.5的epsilon太高了--比如0.1更好--更慢但更好。有了反向传播,它就更先进了一些--但据我所知,神经网络的数学方程描述很复杂,也很难理解--它没有那么复杂。
看看http://www.codeproject.com/KB/recipes/BP.aspx
或谷歌的“反向传播c”-它可能更容易理解在代码。
https://stackoverflow.com/questions/4845489
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号