
是什么使这个桶排序功能变慢了?
函数被定义为
void bucketsort(Array& A){
size_t numBuckets=A.size();
iarray<List> buckets(numBuckets);
//put in buckets
for(size_t i=0;i!=A.size();i++){
buckets[int(numBuckets*A[i])].push_back(A[i]);
}
////get back from buckets
//for(size_t i=0,head=0;i!=numBuckets;i++){
//size_t bucket_size=buckets[i].size();
//for(size_t j=0;j!=bucket_size;j++){
// A[head+j] = buckets[i].front();
// buckets[i].pop_front();
//}
//head += bucket_size;
//}
for(size_t i=0,head=0;i!=numBuckets;i++){
while(!buckets[i].empty()){
A[head] = buckets[i].back();
buckets[i].pop_back();
head++;
}
}
//inseration sort
insertionsort(A);
}其中,List只是STL中的list<double>。
数组的内容是在[0,1)**.**中随机生成的,从理论上讲,对于大容量的,桶排序应该比快速排序快,因为它是O(n),但是它失败了,如下图所示。
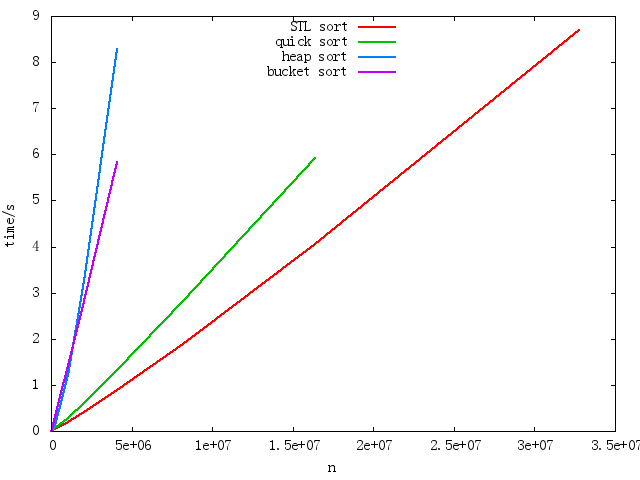
我使用google-perftools在10000000双数组上分析它。它的报告如下
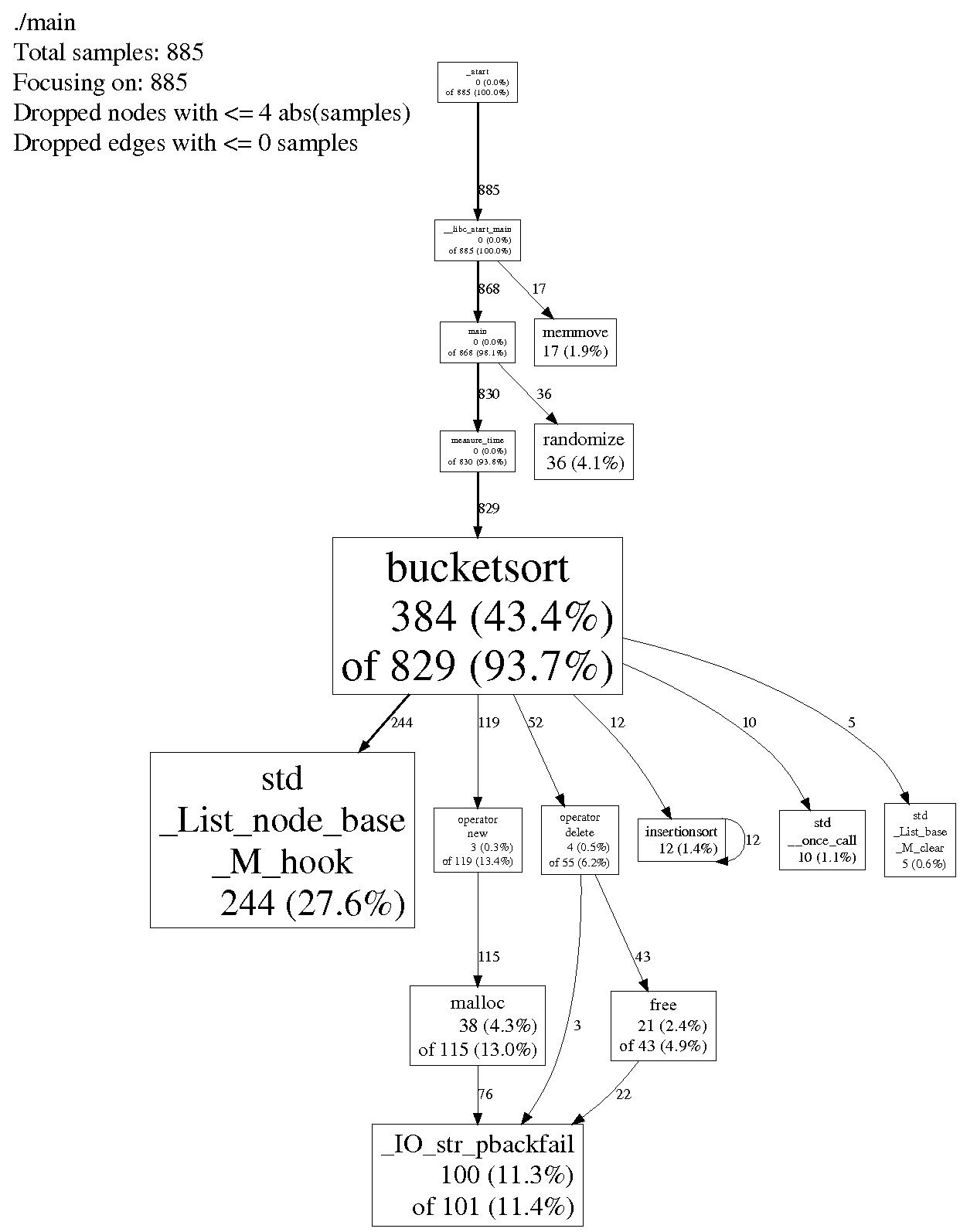
似乎我不应该使用STL列表,但我想知道为什么?std_List_node_base_M_hook是做什么的?我应该自己写单子吗?
PS:实验与改进
我试过只留下放入桶的代码,这解释了大多数时间用于构建桶。
改进如下:-使用STL向量作为桶并为桶保留合理的空间--使用两个助手数组存储构建桶时使用的信息,从而避免使用链接列表,如下所示
void bucketsort2(Array& A){
size_t numBuckets = ceil(A.size()/1000);
Array B(A.size());
IndexArray head(numBuckets+1,0),offset(numBuckets,0);//extra end of head is used to avoid checking of i == A.size()-1
for(size_t i=0;i!=A.size();i++){
head[int(numBuckets*A[i])+1]++;//Note the +1
}
for(size_t i=2;i<numBuckets;i++){//head[1] is right already
head[i] += head[i-1];
}
for(size_t i=0;i<A.size();i++){
size_t bucket_num = int(numBuckets*A[i]);
B[head[bucket_num]+offset[bucket_num]] = A[i];
offset[bucket_num]++;
}
A.swap(B);
//insertionsort(A);
for(size_t i=0;i<numBuckets;i++)
quicksort_range(A,head[i],head[i]+offset[i]);
}下图中的结果
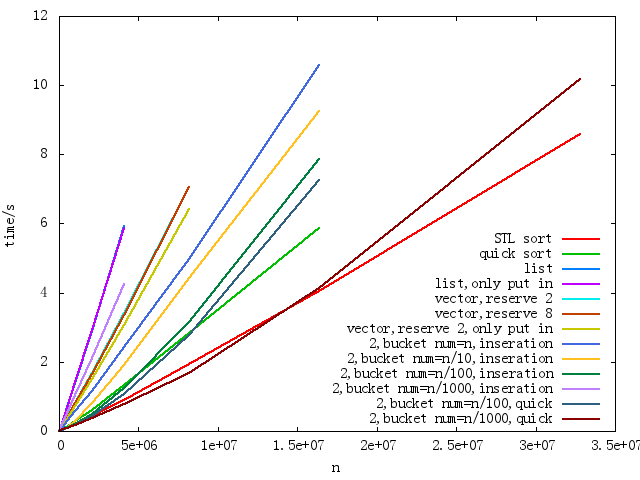
其中行以列表开始,以列表作为桶,从向量开始,以向量作为桶,最后使用helper 2,默认插入排序,还有一些使用快速排序,因为桶大小很大。
注:“列表”和“列表,只放在”,“向量,保留8”和“向量,保留2”几乎重叠。
我会尝试小尺寸和足够的内存预留。
回答 5
Stack Overflow用户
发布于 2010-10-17 16:08:26
使用
iarray<List> buckets(numBuckets);你基本上创建了很多列表,这会花费你很多钱,尤其是在理论上是线性的内存访问,但实际上并非如此。
尽量减少桶的数量。
要验证我的断言,只需创建列表就可以分析代码速度。
另外,要迭代列表中的元素,不应该使用.size(),而应该使用
//get back from buckets
for(size_t i=0,head=0;i!=numBuckets;i++)
while(!buckets[i].empty())
{
A[head++] = buckets[i].front();
buckets[i].pop_front();
}在某些实现中,.size()可以位于O(n)中。不太可能但是..。
经过一些研究,我发现此页解释了std::_List_node_base::hook的代码是什么。
似乎只需要在列表中的给定位置插入元素。不该花很多钱..。
Stack Overflow用户
发布于 2010-10-18 03:00:44
在我看来,这里最大的瓶颈是内存管理功能(如new和delete)。
快速排序( STL可能使用优化版本)可以对数组进行就地排序,这意味着它绝对不需要堆分配。这就是它在实践中表现如此出色的原因。
桶排序依赖于额外的工作空间,理论上假设这是现成的(即假定内存分配根本不需要时间)。在实践中,内存分配从(大的)恒定时间到请求内存大小的线性时间(例如,Windows将花费时间使页面的内容在分配时为零)。这意味着标准链接列表实现将受到影响,并主导您的排序的运行时间。
尝试使用为大量项预先分配内存的自定义列表实现,您应该会看到您的排序运行得更快。
Stack Overflow用户
发布于 2010-10-17 15:08:54
链接列表不是数组。它们执行像查找这样的操作的速度要慢得多。STL排序很可能有一个特定的列表版本,它考虑到了这一点并对其进行了优化--但是您的函数盲目地忽略了它使用的容器。您应该尝试使用STL向量作为数组。
https://stackoverflow.com/questions/3953734
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号