
一种快速计算百分位数以去除离群点的算法
我有一个程序,需要反复计算数据集的近似百分位数(顺序统计),以便在进一步处理之前删除异常值。我目前正在对值数组进行排序,并选择适当的元素;这是可行的,但它是配置文件上的一个明显的亮点,尽管它是程序中的一个相当小的部分。
更多信息:
- 该数据集包含最多100000个浮点数,并假定是“合理”分布的--在特定值附近的密度不太可能重复或出现巨大的峰值;如果由于某种奇怪的原因,这种分布是奇数的,那么近似不太准确是可以的,因为数据可能会被弄乱,而且进一步处理也是可疑的。然而,数据不一定是均匀或正态分布的,只是不太可能退化。
- 近似解很好,但我确实需要了解近似是如何引入错误的,以确保它是有效的。
- 由于目标是消除异常值,我一直在计算同一数据的两个百分位数:例如,一个在95%,一个在5%。
- 该应用程序是在C#中使用的,在C++中有一些繁重的操作;伪代码或任何一个预先存在的库都可以。
- 一种完全不同的方法移除离群点也会很好,只要它是合理的。
- 更新:,我似乎在寻找一个近似的选择算法。
尽管所有这些都是在一个循环中完成的,但每次数据(略有)不同,所以要像对于这个问题那样重用数据结构并不容易。
已实现的解决方案
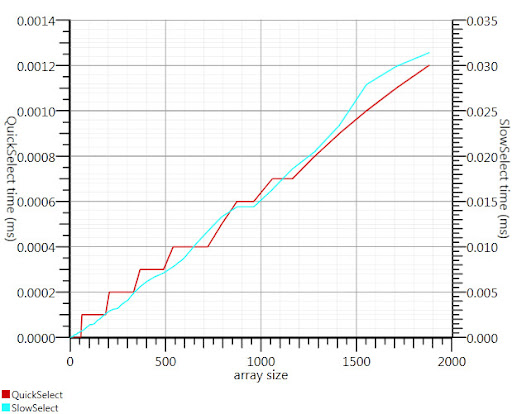
按照Gronim的建议,使用维基百科的选择算法可以将运行时间的这一部分减少大约20倍。
由于我找不到一个C#实现,所以我想出了如下所示。即使对于较小的输入,它也比Array.Sort快;在1000个元素时,它的速度是它的25倍。
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI) / 2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it's good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
谢谢你,格罗尼姆,你给我指明了正确的方向!
回答 10
Stack Overflow用户
发布于 2010-09-23 15:29:24
亨里克的直方图解决方案会有效的。您还可以使用选择算法有效地在O(n)中的n个元素数组中找到k个最大或最小元素。要将其用于第95百分位数集k=0.05n,并查找k个最大元素。
参考资料:
元素
Stack Overflow用户
发布于 2010-09-23 16:00:58
依给它的创建者一个SoftHeap可以用来:
计算精确或近似的中间值和百分位数的最佳。它也适用于近似排序..。
Stack Overflow用户
发布于 2010-09-23 15:23:41
我过去通过计算标准差来识别异常值。任何距离超过2(或3)倍的标准差的东西都是离群点。2倍= 95%左右。
既然你是在计算等价物,它也很容易计算出标准差是非常快的。
您还可以只使用数据的一个子集来计算数字。
https://stackoverflow.com/questions/3779763
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号