
如何可视化基因网络和基因簇群?
如何可视化基因网络和基因簇群?
提问于 2010-09-13 08:26:41
我在研究生物数据,也就是基因群。例如:
group 1: geneA geneB geneC
group 2: geneD geneE
group 3: geneF geneG geneH对于每一对基因,geneX和geneY,我都有一个分数,说明这两个基因有多相似(实际上,我有两个分数,因为我使用了BLAST,它是“定向的”:我首先根据所有其他基因搜索geneX,然后针对所有其他基因搜索geneY,所以我有两个geneX--geneY分数,但我想我可以取两个较低的分数,也就是平均值)。
那么,假设我每对基因只有一个分数。我的数据可以看作是一个无向图:
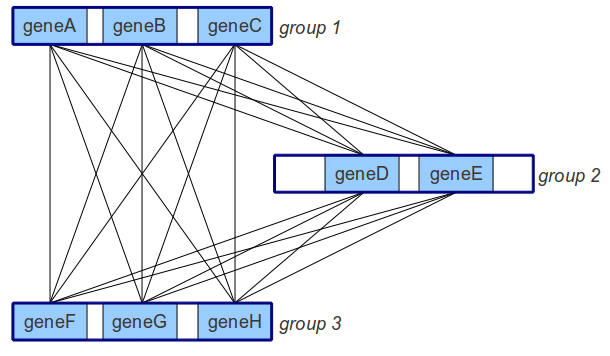
回想一下每一个边缘都有一个分数附加在上面。
现在,我想做的是:
- 交互式地可视化我的数据:能够点击基因节点并打开连接到它们的链接,只显示某个阈值以上/以下的边缘,控制网络如何“传播”等等。
- 聚在一起的组是相似的,也就是有相似基因的组。
我该怎么做呢?我想这是基本的集群,我希望在这里对软件包/软件有任何帮助。
谢谢。
回答 2
Stack Overflow用户
回答已采纳
发布于 2010-09-13 13:18:00
如果您在BioStar (生物信息学stackexchange )询问这个问题,您可能会得到更好的响应。具体来说,这篇文章中的许多答案可能是相关的:
用有向图(网络)表示生物通路的最佳软件是哪一个?
Stack Overflow用户
发布于 2010-09-13 08:30:01
你可以试试会社。您必须将您的三元组(gene_1、gene_2、相似性)转换为一个矩阵,并使用“s群集”。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/3698807
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号