
数据库分析体系结构
我们有一个架构,我们为每个客户提供类似商业智能的服务,为他们的网站(互联网商人)。现在,我需要在内部分析这些数据(为了算法改进、性能跟踪等等)。这些问题可能相当沉重:我们有多达数百万行/客户/天,我可能想知道上个月我们有多少查询,每周比较,等等……这是数以十亿计的条目,如果不是更多的话。
目前的方法是相当标准的:每天扫描数据库的脚本,并生成大的CSV文件。我不喜欢这个解决方案,原因有几点:
- 与这些类型的脚本一样,它们属于写一次和从未接触过的类别。
- 在“实时”中跟踪事物是必要的(我们有单独的工具集来查询最后几个小时的ATM)。
- 这是缓慢和非“敏捷”的。
虽然我在处理用于科学使用的庞大数据集方面有一些经验,但就传统的RDBM而言,我是一个完全的初学者。使用面向列的数据库进行分析似乎是一种解决方案(分析不需要我们在应用程序数据库中拥有的大部分数据),但我想知道有哪些其他选项可以用于这类问题。
回答 3
Stack Overflow用户
发布于 2010-04-21 08:51:14
你会想要谷歌星型模式。其基本思想是对现有OLTP系统的一个特殊数据仓库/ OLAP实例进行建模,并对其进行优化以提供您描述的聚合类型。这个实例将由事实和维度组成。
在下面的例子中,销售“事实”被建模,以提供基于客户、商店、产品、时间和其他“维度”的分析。
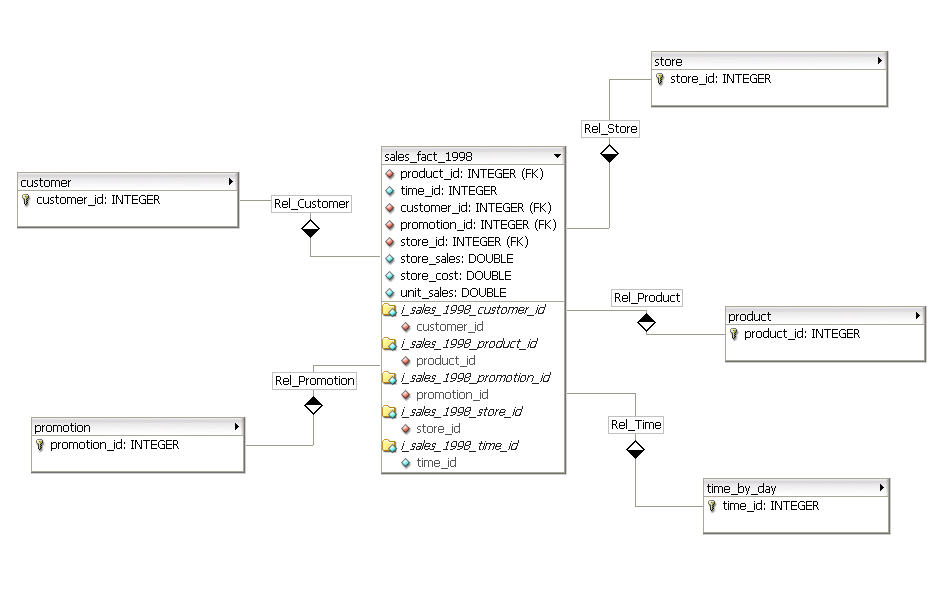
您将发现微软的冒险工程示例数据库具有指导性,因为它们提供了OLTP和OLAP模式以及具有代表性的数据。
Stack Overflow用户
发布于 2010-05-15 18:21:31
有专门的db分析,如格林梅,Aster数据,Vertica,Netezza,Infobright和其他。你可以在这个网站上读到关于数据库的信息:http://www.dbms2.com/
Stack Overflow用户
发布于 2010-04-23 04:57:38
关于星型模式类型数据仓库的规范手册是Raplh Kimball的“数据仓库工具包”(在同一系列中也有“点击流数据仓库”,但我认为这是从2002年开始的,有点过时,我认为如果有一个新版本的Kimball图书,它可能会更好地为您服务)。如果你在谷歌上搜索“网络分析数据仓库”,可以下载和学习一堆样例模式。
另一方面,在现实生活中发生的许多非sql是基于挖掘clickstream数据的,因此可能值得看看Hadoop/Cassandra/最新的酷事物社区在案例研究方面有什么东西,看看您的用例是否与他们所能做的完全匹配。
https://stackoverflow.com/questions/2680853
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号