
一般选择哪种机器学习分类器?
假设我在研究分类问题。(欺诈检测和评论垃圾邮件是我目前正在研究的两个问题,但我对任何分类任务都很好奇。)
我如何知道我应该使用哪个分类器?
- 决策树
- 支持向量机
- 贝氏
- 神经网络
- K近邻
- Q-学习
- 遗传算法
- 马尔可夫决策过程
- 卷积神经网络
- 线性回归或logistic回归
- 加强,包装,诱捕
- 随机爬山或模拟退火
- ..。
在哪种情况下,这些都是“自然”的第一选择,选择这一选择的原则是什么?
我正在寻找的答案类型的例子(来自Manning等人的http://nlp.stanford.edu/IR-book/html/htmledition/choosing-what-kind-of-classifier-to-use-1.html书):
如果您的数据被标记,但您的数量有限,则应该使用具有高偏见的分类器(例如,朴素贝叶斯)。
我猜这是因为高偏倚分类器的方差较低,这是因为数据量很小。
如果你有大量的数据,那么分类器就不那么重要了,所以你应该选择一个具有良好可扩展性的分类器。
- 其他的准则是什么?甚至有这样的回答:“如果你必须向高层管理人员解释你的模型,那么也许你应该使用决策树,因为决策规则是相当透明的”。不过,我不太关心实现/库问题。
- 另外,除了标准的贝叶斯分类器之外,对于一个有点不同的问题,是否有“标准的最先进的”方法来检测垃圾邮件(而不是垃圾邮件)?
回答 9
Stack Overflow用户
发布于 2015-05-09 06:53:28
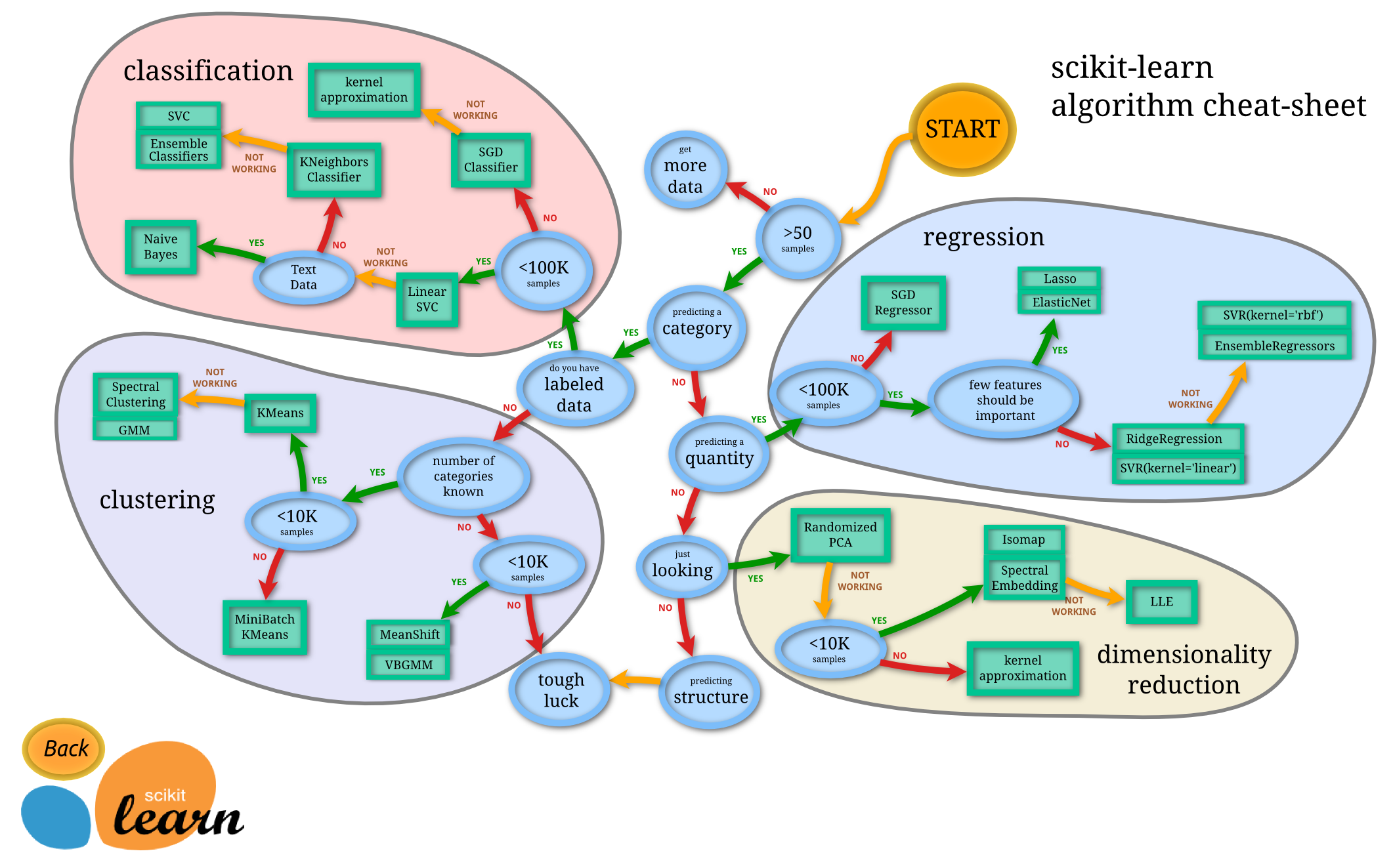
首先,你需要找出你的问题。这取决于您所拥有的数据类型以及您希望完成的任务。
如果您是
Predicting Category:
- 你有
Labeled Data- 您需要遵循
Classification Approach及其算法
- 您需要遵循
- 你没有
Labeled Data- 你得去找
Clustering Approach
- 你得去找
如果您是Predicting Quantity:
- 你得去找
Regression Approach
否则
- 你可以去找
Dimensionality Reduction Approach
上述每种方法都有不同的算法。特定算法的选择取决于数据集的大小。
来源:http://scikit-learn.org/stable/tutorial/machine_learning_map/
Stack Overflow用户
发布于 2010-04-08 08:18:04
模型选择使用交叉验证可能是您所需要的。
交叉验证
您所做的只是将您的数据集分割成k个不重叠的子集(折叠),使用k-1折叠来训练一个模型,并使用遗漏的折叠来预测它的性能。对于每一个可能的折叠组合,您都会这样做(首先将第1次折叠,然后是第2次,.,然后是kth,并与其余的折叠一起训练)。完成后,您估计所有折叠的平均性能(也可能是性能的方差/标准差)。
如何选择参数k取决于您拥有的时间。K的通常值是3、5、10甚至N,其中N是数据的大小(这与保留一次交叉验证相同)。我更喜欢5或10。
模型选择
假设您有5个方法(ANN、SVM、KNN等)和每种方法的10个参数组合(取决于方法)。您只需对每个方法和参数组合(5 * 10 = 50)进行交叉验证,并选择最佳的模型、方法和参数。然后,对所有数据进行重新训练,使用最好的方法和参数,然后就有了最终的模型。
还有一些话要说。例如,如果您对每个方法和参数组合使用了很多方法和参数组合,则很可能您会过度适应。在这种情况下,您必须使用嵌套交叉验证。
嵌套交叉验证
在嵌套交叉验证中,您对模型选择算法执行交叉验证。
同样,您首先将数据拆分为k个折叠。在每个步骤之后,您选择k-1作为您的培训数据,选择其余的作为您的测试数据。然后,对这些k折叠的每个可能组合运行模型选择(我前面解释的过程)。在完成之后,您将有k个模型,每个折叠组合一个。然后,使用剩余的测试数据测试每个模型,并选择最佳的模型。同样,在得到最后一个模型之后,您将对所有的数据使用相同的方法和参数来训练一个新的模型。这是你的最后一个模型。
当然,这些方法和其他我没有提到的东西有很多不同的地方。如果您需要更多有关这些主题的信息,请查找有关这些主题的一些出版物。
Stack Overflow用户
发布于 2010-11-01 22:21:18
这本书"OpenCV“在pages 462-463上有很好的两页。搜索亚马逊预览中的“区分性”(可能还有谷歌图书),你就可以看到相关的页面了。这两页是我在这本书中找到的最伟大的宝石。
简言之:
- 促进-通常是有效的时,大量的训练数据是可用的。
- 随机树-通常非常有效的,也可以执行回归。
- K-近邻-最简单的操作,通常有效的但是慢,并且需要大量的内存
E 231。 - 神经网络-训练速度慢,但速度快,运行,仍然是字母识别的最佳表现。
- 支持向量机-是数据有限的中最好的一种,但只有在
E 154大数据集可用时,才能抵抗或随机树E 253的损失。
https://stackoverflow.com/questions/2595176
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号