
求DAG的所有顶点的可达性计数
我试图找到一种快速算法,以适当的空间要求来解决以下问题。
对于一个DAG的每个顶点,在DAG的传递闭包__中,求出其内度和出度__之和。
鉴于此,DAG:
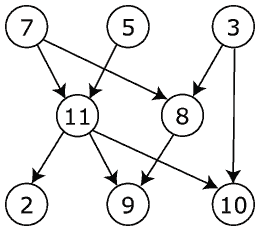
我期望得到以下结果:
Vertex # Reacability Count Reachable Vertices in closure
7 5 (11, 8, 2, 9, 10)
5 4 (11, 2, 9, 10)
3 3 (8, 9, 10)
11 5 (7, 5, 2, 9, 10)
8 3 (7, 3, 9)
2 3 (7, 5, 11)
9 5 (7, 5, 11, 8, 3)
10 4 (7, 5, 11, 3)在我看来,这应该是可能的,而不实际构造传递闭包。我还没有在网上找到任何能准确描述这个问题的东西。我对如何做到这一点有一些想法,但我想看看这么多人能想出些什么来。
回答 4
Stack Overflow用户
发布于 2010-03-11 04:53:44
我已经为这个问题制定了一个可行的解决办法。我的解决方案是基于对拓扑排序算法的修改。下面的算法只计算传递闭包中的内度.出度可以用相同的方式计算,边反,每个顶点的两个计数相加,以确定最终的“可达计数”。
for each vertex V
inCount[V] = inDegree(V) // inDegree() is O(1)
if inCount[V] == 0
pending.addTail(V)
while pending not empty
process(pending.removeHead())
function process(V)
for each edge (V, V2)
predecessors[V2].add(predecessors[V]) // probably O(|predecessors[V]|)
predecessors[V2].add(V)
inCount[V2] -= 1
if inCount[V2] == 0
pending.add(V2)
count[V] = sizeof(predecessors[V]) // store final answer for V
predecessors[V] = EMPTY // save some memory假设集合操作为O(1),则该算法运行在O中。但是,更有可能的是,set联合操作predecessors[V2].add(predecessors[V])会使情况变得更糟。集合联合所需的附加步骤取决于DAG的形状。我认为最坏的情况是O({x}})。在我的测试中,这个算法比我迄今为止尝试过的任何其他算法都表现出了更好的性能。
此外,通过为完全处理的顶点配置前导集,该算法通常比大多数替代方案使用更少的内存。然而,上述算法的最坏的内存消耗与构造传递闭包的内存消耗是一致的,但对于大多数DAG来说并非如此。
Stack Overflow用户
发布于 2010-03-06 17:59:09
要想得到确切的答案,我认为很难超越KennyTM的算法。如果你愿意接受近似,那么坦克计数法( http://www.guardian.co.uk/world/2006/jul/20/secondworldwar.tvandradio )可能会有所帮助。
在[0,1]范围内给每个顶点分配一个随机数。使用一种线性时间动态程序,如多元洗脱剂法,计算每个顶点v的最小可达数(V),然后估计从v到的顶点数目为1 / median (V)-1。为了获得更好的精度,重复几次,并在每个顶点取一个均值中值。
Stack Overflow用户
发布于 2010-03-06 07:23:30
天哪,这是错的!抱歉的!
我会把这个放在一边,直到有一个很好的替代方案。如果可能的话,请随时讨论和扩展这方面的内容。
使用动态规划。
for each vertex V
count[V] = UNKNOWN
for each vertex V
getCount(V)
function getCount(V)
if count[V] == UNKNOWN
count[V] = 0
for each edge (V, V2)
count[V] += getCount(V2) + 1
return count[V]这是带邻接列表的O(|V|+|E|)。它只计算传递闭包中的出度。若要计算内度,请调用边缘反转的getCount .要得到总数,请将两个调用的计数相加。
要了解为什么这是O(|V|+|E|),请考虑以下几个问题:每个顶点V将被精确地访问1 + in-degree(V)时间:一次直接在V上,一次在每个边缘(*, V)上。在随后的访问中,getCount(V)简单地返回了O(1)中的回忆录count[V]。
另一种看待它的方法是,计算每条边将被跟随多少次:准确地说一次。
https://stackoverflow.com/questions/2391672
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号