
语音处理解释中的矢量量化
我很难从本研究论文中准确地确定如何复制标准矢量量化算法来根据一组训练数据来确定未知语音输入的语言。以下是一些基本信息:
抽象信息语言识别(如日语、英语、德语等)使用声学特征是当前语音技术中一个重要而又困难的问题。..。本文使用的语音数据库包含20种语言: 16种句子,其中男性4种,女性4种。每句话的持续时间约为8秒。第一种算法基于标准矢量量化(VQ)技术。每一种语言都有自己的VQ码本,
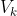
。
识别算法第一种算法是基于标准矢量量化技术的。每一种语言,k,都有自己的VQ码本,
。在识别阶段,输入语音被量化。
计算了累积量化失真( d_k )。被认为是最小失真的语言。计算VQ失真,几种LPC谱失真测度是applied...in本例,加权最小比距离:
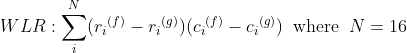
。
标准VQ算法:A码本,
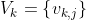
,每种语言都是使用训练语句生成的。句子中输入向量的累积距离定义为:
距离d可以是与声学特征相对应的任意距离,它必须与码本生成所用的距离相同。每种语言的特点都是VQ码本,
。
我的问题是,我到底该怎么做?我有一套50句英语句子。在MATLAB中,我可以很容易地计算任意给定信号的WLR。但是,我如何制定一个码本,因为我必须使用WLR的“码本生成”的英语。我还想知道如何将大小为16 (被发现为最佳大小)的VQ码本与给定的输入信号进行比较。如果有人能帮我把这篇论文撕下来,我会非常感激的。
谢谢!
回答 1
Stack Overflow用户
发布于 2010-02-16 09:10:48
第二个问题(将码本与给定信号进行比较)更容易:对于每个码本条目V_k_j,您必须用输入信号计算距离d。距离最小的'd‘的'j’将共同响应最适合的码本条目。作为距离函数,您可以使用WLR。
构建代码本(trainig)要复杂得多。必须将句子划分为N (16)长的向量,然后使用一些聚类算法(如k-均值)对这些向量进行聚类。那就在每一个星系团中找出小气。这意味着,并将是码本条目。这是一件从脑海中浮现出来的事情。
另一个算法(我相信,它会更好)可以找到这里。另外,在维基百科中还描述了两个简单的训练算法。
https://stackoverflow.com/questions/2271264
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号