
如何尽可能快地使用数百台服务器解析DNS A记录?
现在我用了这个:
from selenium import webdriver
from selenium.webdriver import FirefoxProfile
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.firefox.options import Options
class DNS_LOOKUP:
ROBTEX_IPLOOKUP = 'https://www.robtex.com/ip-lookup/'
ROBTEX_HEAD = '//section[1]/div[3]/p/a'
ROBTEX_TABLE = '//section[2]/div[3]/table/tbody/tr/td//a'
NSLOOKUP_IPV4 = '//div[2]/div[1]/table/tbody/tr/td[2]/span[1]'
NSLOOKUP_IPV6 = '//div[2]/div[2]/table/tbody/tr/td[2]/span[1]'
NSLOOKUP_SOURCES = ['cloudflare', 'google', 'opendns', 'authoritative']
def __init__(self):
options = Options()
options.add_argument("--headless")
options.add_argument("--log-level=3")
options.add_argument("--mute-audio")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument('--disable-extensions')
options.add_argument('--disable-gpu')
capabibilties = DesiredCapabilities().FIREFOX
capabibilties['pageLoadStrategy'] = 'eager'
profile = FirefoxProfile(os.environ['appdata'] + '\\Mozilla\\Firefox\\Profiles\\bkpihn0o.bot')
profile.set_preference("http.response.timeout", 1)
profile.set_preference("dom.max_script_run_time", 0)
profile.set_preference('permissions.default.stylesheet', 2)
profile.set_preference('permissions.default.image', 2)
profile.set_preference('dom.ipc.plugins.enabled.libflashplayer.so', 'false')
profile.set_preference("permissions.default.script", 2)
profile.set_preference("javascript.enabled", False)
self.Firefox = webdriver.Firefox(capabilities=capabibilties, options=options, firefox_profile=profile)
self.AltFirefox = webdriver.Firefox(capabilities=capabibilties)
def _robtex(self, addr):
self.Firefox.get(f'https://www.robtex.com/dns-lookup/{addr}')
ips = {href.removeprefix(DNS_LOOKUP.ROBTEX_IPLOOKUP) for e in self.Firefox.find_elements('xpath', DNS_LOOKUP.ROBTEX_HEAD) if (href := e.get_attribute('href')).startswith(DNS_LOOKUP.ROBTEX_IPLOOKUP)}
ips |= {href.removeprefix(DNS_LOOKUP.ROBTEX_IPLOOKUP) for e in self.Firefox.find_elements('xpath', DNS_LOOKUP.ROBTEX_TABLE) if (href := e.get_attribute('href')).startswith(DNS_LOOKUP.ROBTEX_IPLOOKUP)}
ipv4, ipv6 = set(), set()
for i in sorted(ips):
if IPV4.match(i):
ipv4.add(i)
elif is_ipv6(i):
ipv6.add(i)
return ipv4, ipv6
def _nslookup(self, addr):
ipv4, ipv6 = set(), set()
for source in DNS_LOOKUP.NSLOOKUP_SOURCES:
self.AltFirefox.get(f'https://www.nslookup.io/dns-records/{addr}#{source}')
ipv4 |= {ip for e in self.AltFirefox.find_elements('xpath', DNS_LOOKUP.NSLOOKUP_IPV4) if IPV4.match((ip := e.text))}
ipv6 |= {ip for e in self.AltFirefox.find_elements('xpath', DNS_LOOKUP.NSLOOKUP_IPV6) if is_ipv6((ip := e.text))}
return ipv4, ipv6
def dns_query(self, addr):
robtex = self._robtex(addr)
nslookup = self._nslookup(addr)
ipv4, ipv6 = robtex
ipv4 |= nslookup[0]
ipv6 |= nslookup[1]
return {'ipv4': sorted(ipv4), 'ipv6': sorted(ipv6)}此方法返回大量地址,但遗憾的是还不够,正如您所看到的,它使用的是selenium而不是requests,因此速度很慢。好吧,说实话,我一次又一次地对硒进行了广泛而严格的测试,硒总是比请求更快。但到目前为止,它的速度仍然是不可接受的。
我也写了这封信:
import dns
resolver = dns.resolver.Resolver()
resolver.nameservers = ['8.8.8.8']
def dns_resolve(address):
return sorted({resolver.query(address)[0].address for i in range(4)})它要快得多,但是它只返回每个服务器每个查询的一个地址,所以我重复了四次操作,希望每个查询至少返回每个服务器4个地址.
我甚至写过这样的话:
import json
import requests
def manual_resolve(address):
return [i['data'] for i in json.loads(requests.get(f'https://dns.google/resolve?name={address}&type=A').text)['Answer']]这是我所能得到的最低水平,但正如我前面说过的,在我的网络条件下,请求实际上比selenium慢得多.
因此,我想知道使用多台服务器查询DNS A记录的最快方法是什么,而多个是指大量的;
我从这里得到了5556个可信的名称-服务器:https://public-dns.info/nameservers.csv (地址指向的文件可能随着时间的推移而改变,下载时的版本有5556个条目),我使用这个脚本来处理信息:
import csv
import json
import ping3
import re
import pickle
import subprocess
import time
from collections import namedtuple
from datetime import datetime
from pathlib import Path
IPV4 = re.compile(r'^((25[0-5]|2[0-4]\d|1?\d\d?)\.){3}(25[0-5]|2[0-4]\d|1?\d\d?)$')
publicdns = Path('C:/Users/Estranger/Downloads/nameservers.csv').read_text(encoding='utf8').splitlines()
publicdns = list(csv.reader(publicdns))
to_date = lambda x: datetime.strptime(x, '%Y-%m-%dT%H:%M:%SZ')
Entry = namedtuple('Entry', publicdns[0])
deserializer = [str, str, int, str, str, str, str, str, bool, float, to_date, to_date]
publicdns = [Entry(*(f(v) for f, v in zip(deserializer, i))) for i in publicdns[1:]]
Path('D:/nameservers.pickle').write_bytes(pickle.dumps(publicdns, protocol=pickle.HIGHEST_PROTOCOL))
IPV4_DNS = [ipv4 for e in publicdns if e.reliability >= 0.75 and IPV4.match((ipv4 := e.ip_address))]
Path('D:/reliable_ipv4_dns.txt').write_text('\n'.join(IPV4_DNS))
def ping(addr, lim=0.5):
return sum(d if (d := ping3.ping(addr, timeout=lim, unit='ms')) else 0 for _ in range(4)) / 4
ping_latency = []
new_servers = []
def format_delta(d):
d = int(d)
h, rem = divmod(d, 3600)
m, s = divmod(rem, 60)
return f'{h:02d}:{m:02d}:{s:02d}'
def ping_filter(condition, timeout):
loop = 1
if loop == 1:
servers = IPV4_DNS.copy()
logs = []
start = datetime.now()
success_rate = 0
while True:
loop_start = datetime.now()
total = len(servers)
ping_latency.clear()
new_servers.clear()
succeeded = 0
failed = 0
l = len(str(total))
for iteration, server in enumerate(servers):
latency = ping(server, timeout)
timestamp = datetime.now()
elapsed = timestamp-start
loop_elapsed = timestamp-loop_start
eta = (loop_elapsed.total_seconds() / (iteration + 1)) * (total - iteration - 1)
entry = {
'timestamp': f'{timestamp:%Y-%m-%d %H:%M:%S}',
'loop': loop,
'loop start': f'{loop_start:%Y-%m-%d %H:%M:%S}',
'iteration': iteration,
'server': server,
'success': True,
'latency': round(latency, 2),
'unit': 'ms',
'total': total,
'succeeded': succeeded,
'failed': failed,
'started': f'{start:%Y-%m-%d %H:%M:%S}',
'elapsed': format_delta(elapsed.total_seconds()),
'loop runtime': format_delta(loop_elapsed.total_seconds()),
'ETA': format_delta(eta),
'success rate': f'{success_rate:06.2%}'
}
if 0 < latency <= int(timeout*1000):
succeeded += 1
entry['succeeded'] += 1
new_servers.append(server)
ping_latency.append((server, latency))
else:
failed += 1
entry['failed'] += 1
entry['success'] = False
entry['latency'] = 'timeout'
if iteration == total - 1:
success_rate = succeeded / total
entry['success rate'] = f'{success_rate:06.2%}'
print(json.dumps(entry, indent=4))
logs.append(entry)
new_total = len(new_servers)
servers = new_servers.copy()
if new_total == total or loop == 32:
timestamp = datetime.now()
elapsed = datetime.now()-start
entry = {
'completed': f'{timestamp:%Y-%m-%d %H:%M:%S}',
'started': f'{start:%Y-%m-%d %H:%M:%S}',
'elapsed': format_delta(elapsed.total_seconds()),
'loop': loop
}
print(json.dumps(entry, indent=4))
logs.append(entry)
break
loop += 1
Path(f'D:/IPv4_DNS_{condition}.txt').write_text('\n'.join(servers))
Path(f'D:/IPv4_DNS_ping_log_{condition}.json').write_text(json.dumps(logs, indent=4))
Path(f'D:/IPv4_DNS_ping_latency_{condition}.json').write_text(json.dumps(dict(ping_latency), indent=4))
ping_filter('NOVPN', 0.3)它需要超过24小时才能完成,简而言之,我最终得到了1518台服务器。
我需要使用所有这1518台服务器来解析每个输入地址的A条记录,这样才有机会找到一个未被阻塞或减速的IP地址,那么如何使用大量的名称服务器异步解析DNS A记录呢?
更新
好的,现在我已经看了asyncio,concurrent.futures.ThreadPoolExecutor和dns.asyncresolver,我认为它们正是我想要的,但是还有一些事情我还不太明白。
我正在考虑使用4个并发线程池,每个线程池同步运行4次(因为现在每个服务器只能获得1个地址,Google没有任何帮助),每个线程池的最大大小为4,每个任务都是在32台服务器上执行异步DNS查询功能。
以下是我想出的:
def split_sixteen(series):
length = len(series)
p4 = -(-length // 4)
p16 = -(-length // 16)
indices = [(0, 1), (1, 2), (2, 3), (3, 4)]
return [[series[p4*a:p4*b][p16*c:p16*d] for c, d in indices] for a, b in indices]
class Assigner:
def __init__(self, tasks, batch=32) -> None:
self.tasks = tasks
self.length = len(tasks)
self.index = 0
self.batch = batch
self.all_assigned = False
def assign(self):
if not self.all_assigned:
start = self.index
if self.index + self.batch <= self.length:
self.index += self.batch
else:
self.index = self.length
if self.index == self.length:
self.all_assigned = True
return self.tasks[start:self.index]
else:
raise StopIteration('All tasks have been assigned')我不知道线程池应该运行什么函数,我认为函数应该有一个while循环,直到分配程序耗尽为止,循环从指定者处占用多达32台服务器,并将其放在线程池中运行,如果已经没有4个coroutine,则等待一个例程结束启动另一个例程,在循环结束后,函数应该等待例程完成合并结果,并且所有4个线程池的结果都应该合并.
我不知道如何让所有这些都一起工作..。
关于selenium比requests快,令人震惊,我知道,但这是真的,如果你不主观地相信真相,就不会变成不真实:
import os
import requests
from selenium import webdriver
from selenium.webdriver import FirefoxProfile
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.firefox.options import Options
options = Options()
options.add_argument("--headless")
options.add_argument("--log-level=3")
options.add_argument("--mute-audio")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument('--disable-extensions')
options.add_argument('--disable-gpu')
capabibilties = DesiredCapabilities().FIREFOX
capabibilties['pageLoadStrategy'] = 'eager'
profile = FirefoxProfile(os.environ['appdata'] + '\\Mozilla\\Firefox\\Profiles\\bkpihn0o.bot')
profile.set_preference("http.response.timeout", 1)
profile.set_preference("dom.max_script_run_time", 0)
profile.set_preference('permissions.default.stylesheet', 2)
profile.set_preference('permissions.default.image', 2)
profile.set_preference('dom.ipc.plugins.enabled.libflashplayer.so', 'false')
profile.set_preference("permissions.default.script", 2)
profile.set_preference("javascript.enabled", False)
Firefox = webdriver.Firefox(capabilities=capabibilties, options=options, firefox_profile=profile)
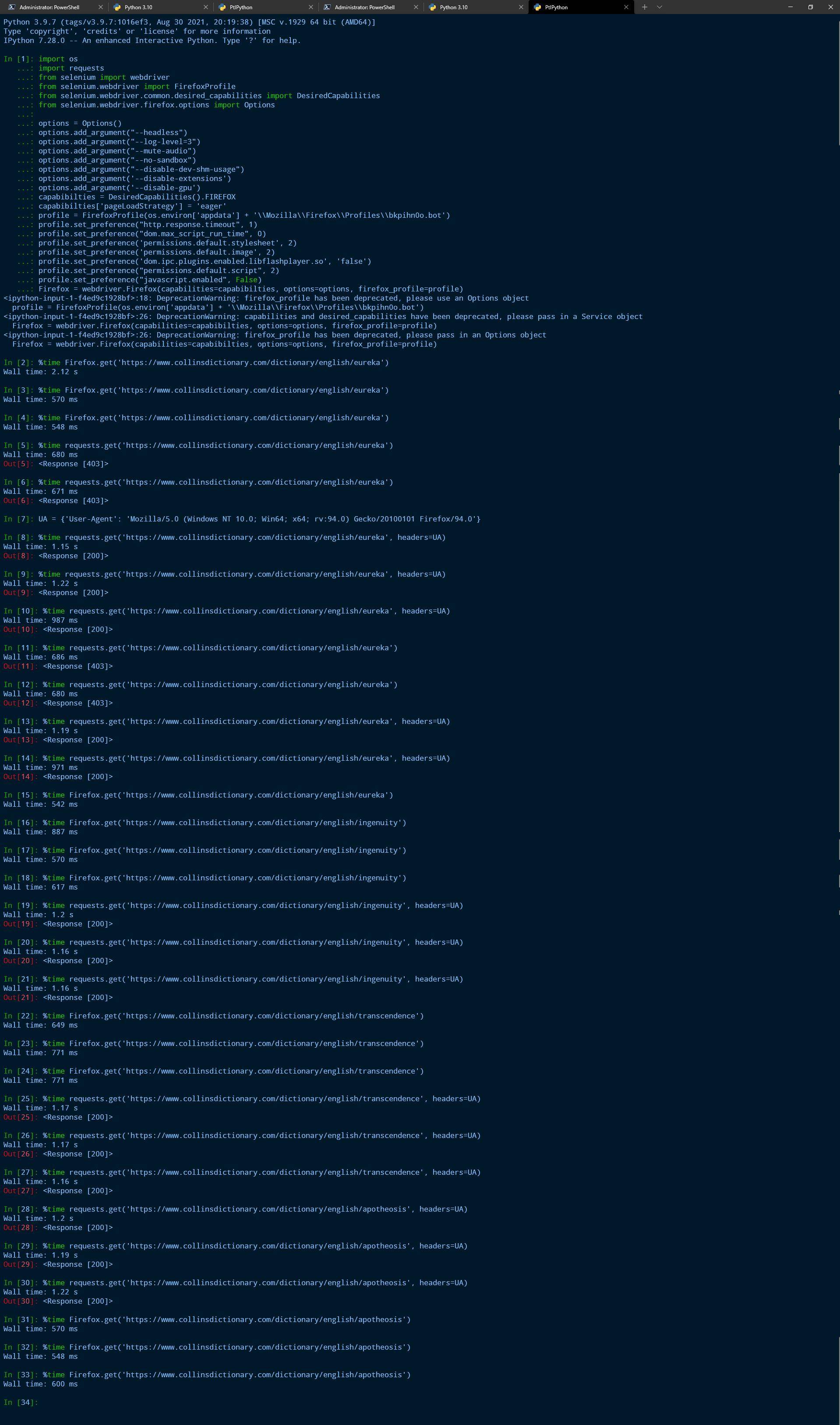
也许我没有提到我在连接到VPN时执行这些测试的事实,而且似乎请求没有利用VPN的优势。
回答 1
Stack Overflow用户
发布于 2021-12-07 15:53:32
请看我对你帖子的评论。
我发现很难相信selenium能够优于直接调用DNS服务器。毕竟,selenium将使用同一个网络发出GET请求。
我在Windows下安装了dnspython,并使用线程池进行了一些基准测试,线程池的大小与我试图解析的域数相等,它是750个,包含15个不同的域,每个域重复重复50次。然后,我从OP引用的CSV文件中创建了一个DNS服务器的小列表。我还试图使用asyncio解析域,但无法使其工作。这些是具体的基准:
test1:所有域都是使用一个服务器列表并发解析的,该列表包含单个DNS服务器“8.8.8.8”。即使对所有请求都使用了相同的DNS服务器地址,但对于不同的解析请求,可以将给定域(如bonappetit.com )解析为不同的IP地址。解析所有请求的时间为1.56秒。
对于这个基准测试,每个请求都得到一个服务器列表,该列表是从DNS服务器列表中一致选择的单个DNS服务器的服务器列表。我很快发现许多DNS服务器地址并不特别可靠,并导致超时异常,必须从服务器列表和基准测试重新运行中删除。解析所有请求的时间为5.57秒。
对于这个基准测试,每个请求都得到了不包括'8.8.8.8‘的DNS服务器的完整列表。基准时间为3.54秒。未显示的是一个基准,我提供了包括“8.8.8.8”在内的全部服务器列表。它的基准时间与“test1 1”的时间基本相同。我再次重复了基准测试,其中'8.8.8.8‘是列表中的最后一个条目,运行时间始终比test1的运行时间慢几百秒,后者是列表中的第一个条目。随后,我再次重新运行此基准,将'8.8.8.8‘排除在列表之外,现在我看到的运行时间与test1的运行时间相当。这表明,我使用的服务器(除了'8.8.8.8‘之外)的响应时间非常不稳定,即使它们不使用timeout.
test4:I使用了一种完全不同的解析方法,即socket.gethostbyname。这是迄今为止最快的.27秒基准时间,每个域只返回一个IP地址。我相信这两个结果都可以通过Windows缓存结果来解释。
test5:--这是对单个DNS服务器'8.8.8.8‘使用asyncio的尝试,并且超时了。我不知道为什么。
结论
首先,您的5556 DNS服务器并不是同样值得信任的,并且它们的可信度每时每刻都在变化。我会对位于您附近的服务器进行实验,以确定最值得信赖的服务器,并将一些服务器列表中的“8.8.8.8”作为第一个条目。为了更清楚地说明这一点,我说的是基准测试test3**,中使用的代码,但不排除服务器'8.8.8.8'.**
第二,我看不到创建多个线程池的理由。但是有一些你不应该超过的最大尺寸。当然,500不应该是一个问题。但是,如果您能够让asyncio工作,您应该能够在没有问题的情况下收集数千个任务。
import dns.resolver
import asyncio
import dns.asyncresolver
import socket
import time
from multiprocessing.pool import ThreadPool
l = [
'yahoo.com',
'cnn.com',
'ibm.com',
'nytimes.com',
'stackoverflow.com',
'tcm.com',
'wqxr.org',
'wahingtonpost.com',
'theatlantic.com',
'nymag.com',
'newyorker.com',
'bonappetit.com',
'seriouseats.com',
'foodtv.com',
'food52.com',
]
domains = []
for _ in range(50):
domains += l
servers = [
'8.8.8.8',
'8.0.7.0',
'8.0.6.0',
'195.99.66.220',
'38.132.106.139',
]
def test1(pool):
def resolve(domain):
resolver = dns.resolver.Resolver()
resolver.nameservers = ['8.8.8.8']
return (domain, resolver.resolve(domain)[0].address)
return pool.map(resolve, domains)
def test2(pool):
def resolve(idx, domain):
resolver = dns.resolver.Resolver()
i = idx % len(servers)
resolver.nameservers = [servers[i]]
try:
return (domain, resolver.resolve(domain)[0].address)
except Exception as e:
print(e, servers[i])
return None
return pool.starmap(resolve, enumerate(domains))
def test3(pool):
def resolve(domain):
resolver = dns.resolver.Resolver()
resolver.nameservers = servers[1:] # omit '8.8.8.8'
return (domain, resolver.resolve(domain)[0].address)
return pool.map(resolve, domains)
def test4(pool):
def resolve(domain):
return (domain, socket.gethostbyname(domain))
return pool.map(resolve, domains)
async def test5():
async def resolve(domain):
resolver = dns.asyncresolver.Resolver()
resolver.nameservers = ['8.8.8.8']
addr = await resolver.resolve(domain)
return (domain, addr[0].address)
return await asyncio.gather(*(resolve(domain) for domain in domains))
pool = ThreadPool(len(domains))
def benchmark(fun):
print()
print(fun.__name__)
start = time.time()
results = fun(pool)
print(time.time() - start)
print(sorted(set(results)))
benchmark(test1)
benchmark(test2)
benchmark(test3)
benchmark(test4)
print()
print('test5')
start = time.time()
results = asyncio.run(test5())
print(time.time() - start)
print(sorted(set(results)))指纹:
test1
1.5600032806396484
[('bonappetit.com', '151.101.0.239'), ('bonappetit.com', '151.101.192.239'), ('bonappetit.com', '151.101.64.239'), ('cnn.com', '151.101.1.67'), ('cnn.com', '151.101.129.67'), ('cnn.com', '151.101.65.67'), ('food52.com', '104.18.166.45'), ('food52.com', '104.18.174.13'), ('foodtv.com', '67.199.248.12'), ('foodtv.com', '67.199.248.13'), ('ibm.com', '184.29.179.199'), ('newyorker.com', '151.101.0.239'), ('newyorker.com', '151.101.128.239'), ('newyorker.com', '151.101.192.239'), ('newyorker.com', '151.101.64.239'), ('nymag.com', '151.101.130.133'), ('nymag.com', '151.101.194.133'), ('nymag.com', '151.101.2.133'), ('nymag.com', '151.101.66.133'), ('nytimes.com', '151.101.1.164'), ('nytimes.com', '151.101.129.164'), ('nytimes.com', '151.101.193.164'), ('nytimes.com', '151.101.65.164'), ('seriouseats.com', '151.101.2.137'), ('stackoverflow.com', '151.101.1.69'), ('stackoverflow.com', '151.101.129.69'), ('stackoverflow.com', '151.101.65.69'), ('tcm.com', '104.127.162.10'), ('theatlantic.com', '151.101.130.133'), ('theatlantic.com', '151.101.194.133'), ('theatlantic.com', '151.101.2.133'), ('theatlantic.com', '151.101.66.133'), ('wahingtonpost.com', '198.72.14.16'), ('wqxr.org', '44.194.174.151'), ('wqxr.org', '54.144.182.133'), ('yahoo.com', '74.6.143.25'), ('yahoo.com', '74.6.143.26'), ('yahoo.com', '74.6.231.21'), ('yahoo.com', '98.137.11.163')]
test2
5.566321611404419
[('bonappetit.com', '151.101.0.239'), ('bonappetit.com', '151.101.128.239'), ('bonappetit.com', '151.101.192.239'), ('bonappetit.com', '151.101.64.239'), ('cnn.com', '151.101.1.67'), ('cnn.com', '151.101.129.67'), ('cnn.com', '151.101.193.67'), ('cnn.com', '151.101.65.67'), ('food52.com', '104.18.166.45'), ('foodtv.com', '67.199.248.12'), ('foodtv.com', '67.199.248.13'), ('ibm.com', '23.218.185.219'), ('newyorker.com', '151.101.0.239'), ('newyorker.com', '151.101.128.239'), ('newyorker.com', '151.101.192.239'), ('newyorker.com', '151.101.64.239'), ('nymag.com', '151.101.130.133'), ('nytimes.com', '151.101.1.164'), ('nytimes.com', '151.101.129.164'), ('nytimes.com', '151.101.193.164'), ('nytimes.com', '151.101.65.164'), ('seriouseats.com', '151.101.130.137'), ('seriouseats.com', '151.101.194.137'), ('seriouseats.com', '151.101.2.137'), ('seriouseats.com', '151.101.66.137'), ('stackoverflow.com', '151.101.1.69'), ('tcm.com', '104.127.162.10'), ('theatlantic.com', '151.101.130.133'), ('theatlantic.com', '151.101.194.133'), ('theatlantic.com', '151.101.2.133'), ('theatlantic.com', '151.101.66.133'), ('wahingtonpost.com', '198.72.14.16'), ('wqxr.org', '44.194.174.151'), ('wqxr.org', '54.144.182.133'), ('yahoo.com', '74.6.143.26'), ('yahoo.com', '74.6.231.21'), ('yahoo.com', '98.137.11.163')]
test3
3.536404609680176
[('bonappetit.com', '151.101.0.239'), ('bonappetit.com', '151.101.128.239'), ('bonappetit.com', '151.101.192.239'), ('bonappetit.com', '151.101.64.239'), ('cnn.com', '151.101.1.67'), ('cnn.com', '151.101.129.67'), ('cnn.com', '151.101.193.67'), ('cnn.com', '151.101.65.67'), ('food52.com', '104.18.166.45'), ('food52.com', '104.18.174.13'), ('foodtv.com', '67.199.248.12'), ('foodtv.com', '67.199.248.13'), ('ibm.com', '23.218.185.219'), ('newyorker.com', '151.101.0.239'), ('newyorker.com', '151.101.128.239'), ('newyorker.com', '151.101.192.239'), ('newyorker.com', '151.101.64.239'), ('nymag.com', '151.101.130.133'), ('nymag.com', '151.101.194.133'), ('nymag.com', '151.101.2.133'), ('nymag.com', '151.101.66.133'), ('nytimes.com', '151.101.1.164'), ('nytimes.com', '151.101.129.164'), ('nytimes.com', '151.101.193.164'), ('nytimes.com', '151.101.65.164'), ('seriouseats.com', '151.101.130.137'), ('seriouseats.com', '151.101.194.137'), ('seriouseats.com', '151.101.2.137'), ('seriouseats.com', '151.101.66.137'), ('stackoverflow.com', '151.101.1.69'), ('stackoverflow.com', '151.101.129.69'), ('stackoverflow.com', '151.101.193.69'), ('stackoverflow.com', '151.101.65.69'), ('tcm.com', '23.75.199.121'), ('theatlantic.com', '151.101.130.133'), ('theatlantic.com', '151.101.194.133'), ('theatlantic.com', '151.101.2.133'), ('theatlantic.com', '151.101.66.133'), ('wahingtonpost.com', '198.72.14.16'), ('wqxr.org', '44.194.174.151'), ('wqxr.org', '54.144.182.133'), ('yahoo.com', '74.6.143.25'), ('yahoo.com', '74.6.143.26'), ('yahoo.com', '74.6.231.20'), ('yahoo.com', '74.6.231.21'), ('yahoo.com', '98.137.11.163'), ('yahoo.com', '98.137.11.164')]
test4
0.33908557891845703
[('bonappetit.com', '151.101.64.239'), ('cnn.com', '151.101.129.67'), ('food52.com', '104.18.174.13'), ('foodtv.com', '67.199.248.12'), ('ibm.com', '104.104.121.251'), ('newyorker.com', '151.101.192.239'), ('nymag.com', '151.101.130.133'), ('nytimes.com', '151.101.193.164'), ('seriouseats.com', '151.101.66.137'), ('stackoverflow.com', '151.101.65.69'), ('tcm.com', '104.127.162.10'), ('theatlantic.com', '151.101.2.133'), ('wahingtonpost.com', '198.72.14.16'), ('wqxr.org', '44.194.174.151'), ('yahoo.com', '98.137.11.164')]
test5
Traceback (most recent call last):
...
addr = await resolver.resolve(domain)
File "C:\Booboo\test\test_venv\lib\site-packages\dns\asyncresolver.py", line 74, in resolve
timeout = self._compute_timeout(start, lifetime)
File "C:\Booboo\test\test_venv\lib\site-packages\dns\resolver.py", line 997, in _compute_timeout
raise Timeout(timeout=duration)
dns.exception.Timeout: The DNS operation timed out after 5.38653302192688 seconds更新
我遇到了this post,它描述了PyPi版本的dnspython中的一个错误,它导致了async解析器清理。解决方案是从Github加载最新版本:
pip install -U https://github.com/rthalley/dnspython/archive/master.zip我重新运行了基准,这次将需要获取的域数量增加到3,000个,坦率地说,这是要创建的许多线程,因此我设置了线程池大小的上限为500 (现在包括在计时中创建线程池的时间),并将完整的DNS服务器列表提供给多线程基准和异步基准(总共两个基准)。我还做了一个改进,即只创建一次解析器类,并重用它来解决所有请求。此外,单个查询返回的所有IP地址都会添加到由该域键键维护的一组IP地址中,以便在针对同一个域(如我的基准测试中的情况)发出多个请求时,最终找到一组唯一的IP地址。返回的是最终的字典。
结果:
multithreading: 1.99 seconds
asyncio: 3.43 seconds这是令人惊讶的,因为我认为有大量的域需要处理,并且限制了线程池的大小,认为异步版本会更有性能。显然,多线程似乎是可行的。
import dns.resolver
import asyncio
import dns.asyncresolver
import socket
import time
from multiprocessing.pool import ThreadPool
l = [
'yahoo.com',
'cnn.com',
'ibm.com',
'nytimes.com',
'stackoverflow.com',
'tcm.com',
'wqxr.org',
'wahingtonpost.com',
'theatlantic.com',
'nymag.com',
'newyorker.com',
'bonappetit.com',
'seriouseats.com',
'foodtv.com',
'food52.com',
]
domains = []
for _ in range(200):
domains += l
servers = [
'8.8.8.8',
'8.0.7.0',
'8.0.6.0',
'195.99.66.220',
'38.132.106.139',
]
def threading_test(pool):
resolver = dns.resolver.Resolver()
resolver.nameservers = servers
ip_addresses = {}
def resolve(domain):
results = resolver.resolve(domain)
s = ip_addresses.setdefault(domain, set())
for result in results:
s.add(result.address)
pool.map(resolve, domains)
return ip_addresses
async def async_test():
resolver = dns.asyncresolver.Resolver()
resolver.nameservers = servers
ip_addresses = {}
async def resolve(domain):
results = await resolver.resolve(domain)
s = ip_addresses.setdefault(domain, set())
for result in results:
s.add(result.address)
await asyncio.gather(*(resolve(domain) for domain in domains))
return ip_addresses
print('threading_test')
start = time.time()
pool = ThreadPool(min(500, len(domains)))
results = threading_test(pool)
print(time.time() - start)
for k in sorted(results.keys()):
print(k, sorted(results[k]))
print()
print('async_test')
start = time.time()
results = asyncio.run(async_test())
print(time.time() - start)
for k in sorted(results.keys()):
print(k, sorted(results[k]))指纹:
1.9919934272766113
bonappetit.com ['151.101.0.239', '151.101.128.239', '151.101.192.239', '151.101.64.239']
cnn.com ['151.101.1.67', '151.101.129.67', '151.101.193.67', '151.101.65.67']
food52.com ['104.18.166.45', '104.18.174.13']
foodtv.com ['67.199.248.12', '67.199.248.13']
ibm.com ['184.29.179.199']
newyorker.com ['151.101.0.239', '151.101.128.239', '151.101.192.239', '151.101.64.239']
nymag.com ['151.101.130.133', '151.101.194.133', '151.101.2.133', '151.101.66.133']
nytimes.com ['151.101.1.164', '151.101.129.164', '151.101.193.164', '151.101.65.164']
seriouseats.com ['151.101.130.137', '151.101.194.137', '151.101.2.137', '151.101.66.137']
stackoverflow.com ['151.101.1.69', '151.101.129.69', '151.101.193.69', '151.101.65.69']
tcm.com ['104.127.162.10']
theatlantic.com ['151.101.130.133', '151.101.194.133', '151.101.2.133', '151.101.66.133']
wahingtonpost.com ['198.72.14.16']
wqxr.org ['44.194.174.151', '54.144.182.133']
yahoo.com ['74.6.143.25', '74.6.143.26', '74.6.231.20', '74.6.231.21', '98.137.11.163', '98.137.11.164']
async_test
3.437023878097534
bonappetit.com ['151.101.0.239', '151.101.128.239', '151.101.192.239', '151.101.64.239']
cnn.com ['151.101.1.67', '151.101.129.67', '151.101.193.67', '151.101.65.67']
food52.com ['104.18.166.45', '104.18.174.13']
foodtv.com ['67.199.248.12', '67.199.248.13']
ibm.com ['184.29.179.199', '23.218.185.219']
newyorker.com ['151.101.0.239', '151.101.128.239', '151.101.192.239', '151.101.64.239']
nymag.com ['151.101.130.133', '151.101.194.133', '151.101.2.133', '151.101.66.133']
nytimes.com ['151.101.1.164', '151.101.129.164', '151.101.193.164', '151.101.65.164']
seriouseats.com ['151.101.130.137', '151.101.194.137', '151.101.2.137', '151.101.66.137']
stackoverflow.com ['151.101.1.69', '151.101.129.69', '151.101.193.69', '151.101.65.69']
tcm.com ['104.127.162.10', '23.79.32.175']
theatlantic.com ['151.101.130.133', '151.101.194.133', '151.101.2.133', '151.101.66.133']
wahingtonpost.com ['198.72.14.16']
wqxr.org ['44.194.174.151', '54.144.182.133']
yahoo.com ['74.6.143.25', '74.6.143.26', '74.6.231.20', '74.6.231.21', '98.137.11.163', '98.137.11.164']https://stackoverflow.com/questions/70224740
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号