
Azure Synapse无分隔SQL池-查询执行失败
完成教程1之后,我将使用Microsoft团队的教程2来运行以下查询(如第三步所示)。但是,查询执行会给出如下错误:
问题:错误的原因可能是什么,我们如何解决它?
查询
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://contosolake.dfs.core.windows.net/users/NYCTripSmall.parquet',
FORMAT='PARQUET'
) AS [result]误差
警告:没有找到与表达式“https://contosolake.dfs.core.windows.net/users/NYCTripSmall.parquet'”匹配的数据集。无法确定架构,因为没有找到匹配名称模式'https://contosolake.dfs.core.windows.net/users/NYCTripSmall.parquet'的文件。请在OPENROWSET函数中使用WITH子句来定义架构。
注意事项:容器中文件的路径是正确的,实际上,我通过右键单击容器中的文件并生成脚本生成了以下查询:

备注
- Azure数据湖存储Gen2帐户名称:
contosolake - 容器名称:
users - Azure数据湖帐户上使用的防火墙设置:
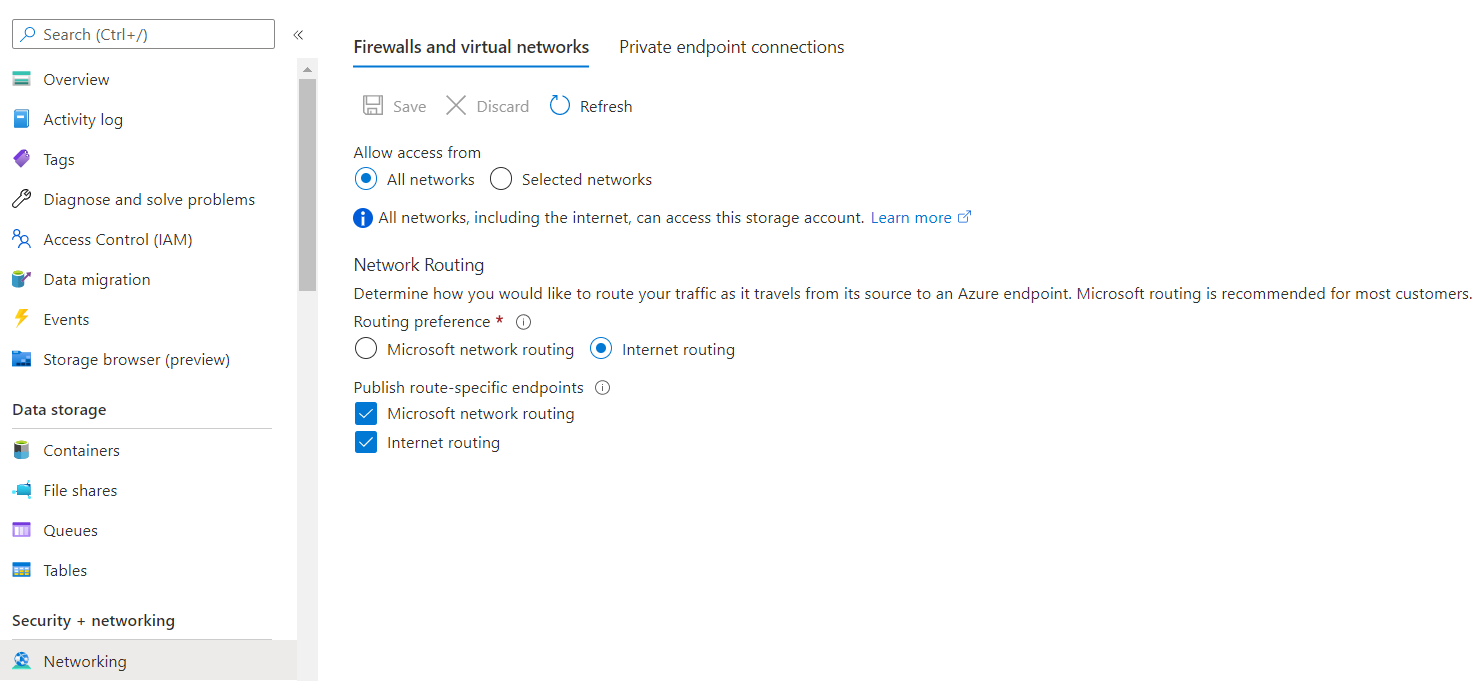
- Azure数据湖存储Gen2帐户允许公众访问(参考):
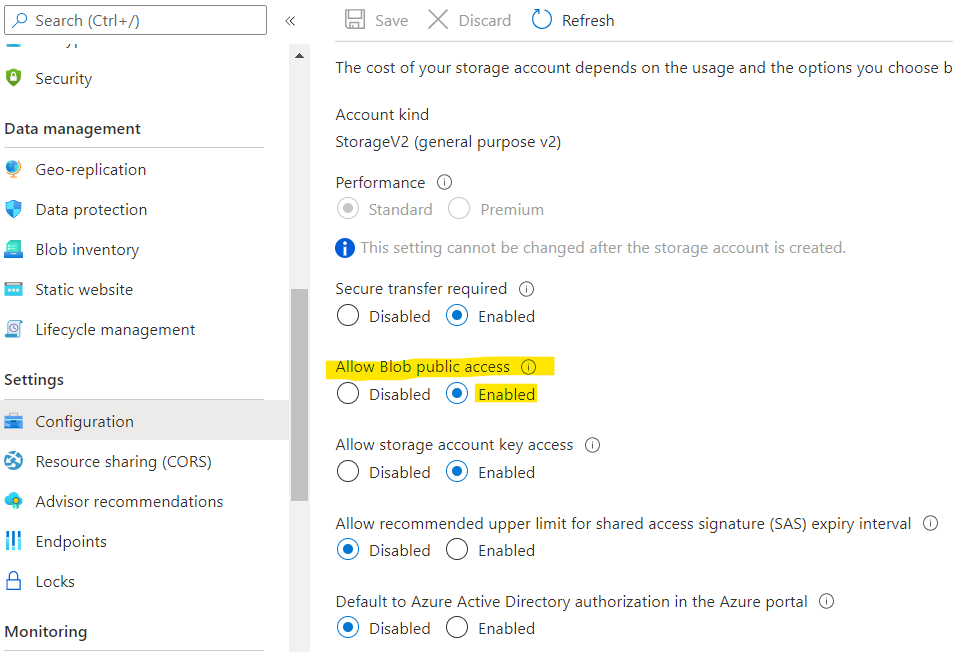
- 容器具有必需的访问级别(参考)
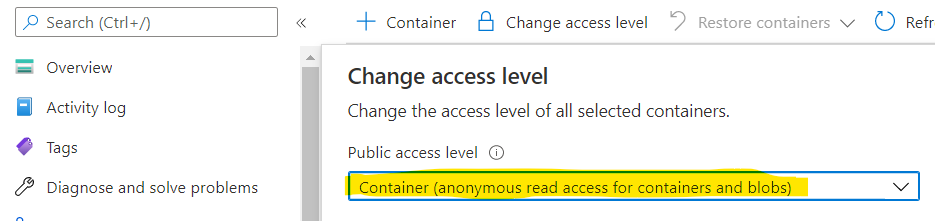
更新
订阅的所有者是其他人,我没有得到在Basics选项卡>教程1的workspace details部分第3项中描述的“在described Gen2帐户上为自己分配存储Blob数据贡献者角色”的选项。我也没有添加角色的权限--尽管我是synapse工作区的所有者。因此,我正在使用Azure团队在配置容器和blobs的匿名公共读取访问中描述的解决方案。
回答 1
Stack Overflow用户
发布于 2021-11-08 10:03:12
--解决的方法
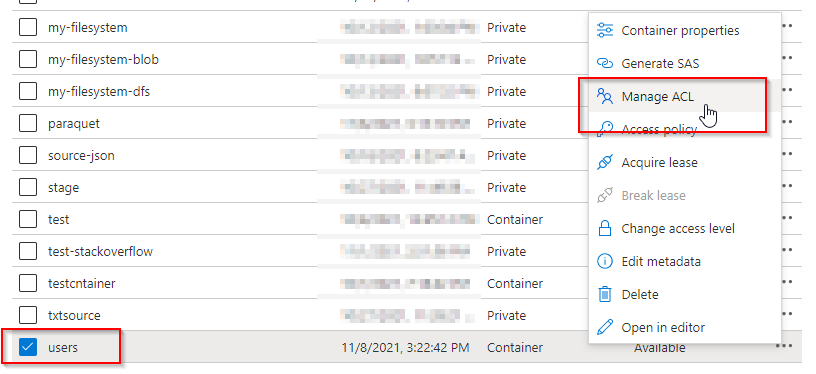
如果无法授予Storage数据贡献者,请使用ACL授予权限。
所有需要访问此容器中某些数据的用户也需要对所有父文件夹具有执行权限,直到根(容器)。了解有关如何在Azure数据湖存储Gen2中设置ACL的更多信息。
注:
容器级别上的执行权限需要在Azure数据湖Gen2中设置。文件夹的权限可以在Azure Synapse中设置。
转到容器容纳NYCTripSmall.parquet.
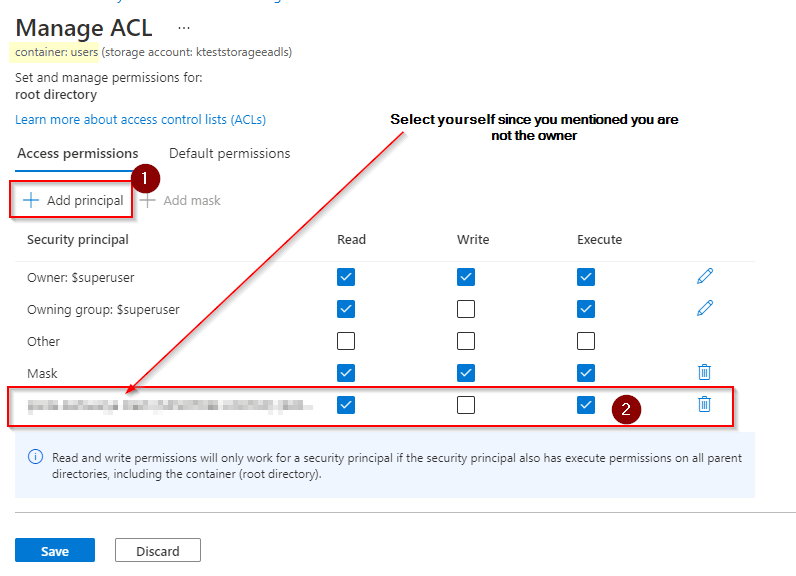
--更新
根据您在评论中的更新,您似乎不得不这样做。
与存储帐户的所有者联系,并要求他们执行以下任务:
- 将工作区MSI分配给存储帐户上的角色
- 将您分配给存储帐户上的Storage数据贡献者角色
--
我能够按照您提到的针对同一数据集的教程文档获得查询结果。
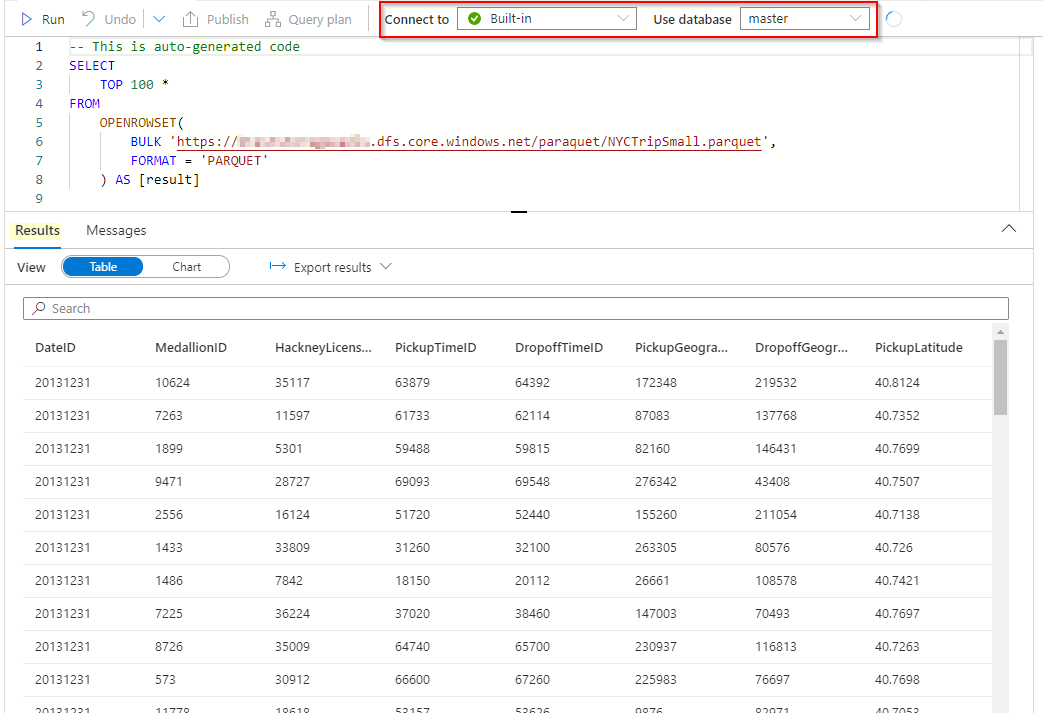
由于您确认文件存在并位于正确的路径上,所以在运行之前刷新链接的ADLS源并发布查询,以防出现临时问题。
我怀疑有两件事
- 尝试在ADLS帐户中的
Microsoft network routing设置中设置Network Routing。
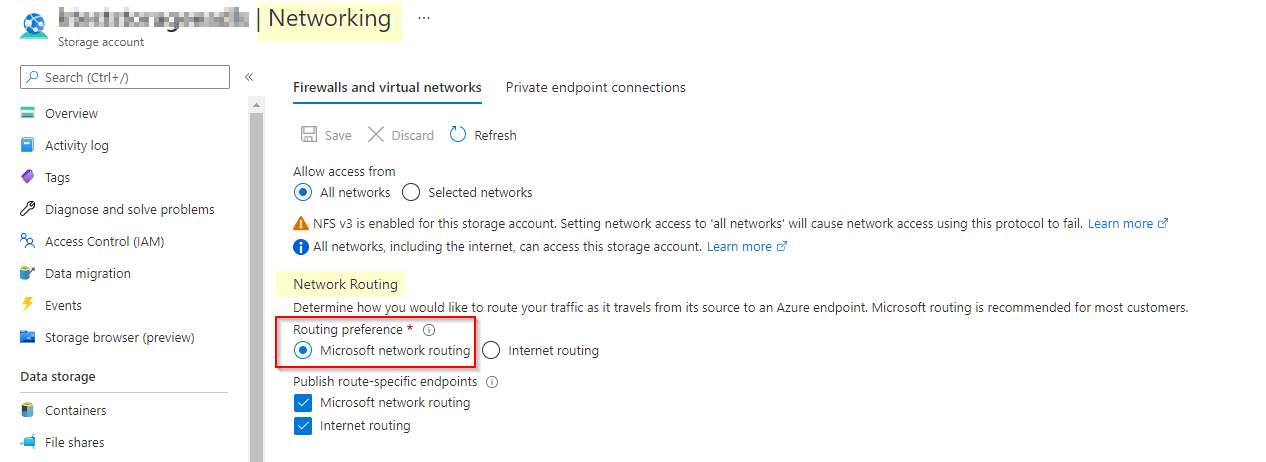
- 检查内置池是否联机,并且至少在Synapse工作区和存储帐户上都有贡献者角色。(如果用于运行查询的当前凭据尚未创建资源)
https://stackoverflow.com/questions/69874957
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号