
构建星火项目方法论
我现在在我的第一份工作,涉及火花。代码是用Java编写的。
我目前的任务是继续执行以前的开发工具所遗留下来的内容。
任务本身并不是很困难,但它的背景是:
- 有来自不同来源(文件、公司端点、表等)的10+数据集--
- --这些数据集必须在最后加入到唯一的数据集中。
- 在这些数据集上有数百条“规则”。
- 这些规则中的一些规则只能通过来自DsA + DsB的特定连接来应用。
之前的Dev编写了规则,只有一个特定的类(这些类变得非常大,比如上千行)中的联接也有一个巨大的主类。
我可以很容易地遵循同样的过程,并使这些课程更大,但我发现这是极其恼人的阅读和维护的未来。
就目前而言,我对项目进行了如下包的重组:
- read
- preprocess
- calculations
- write
但我也怀疑我自己的方法,我在公司里没有高级职位可依赖。
- My类只是有许多实用程序类(但有组织吗?)包含规则的静态方法,我从helper类调用这些方法来链接所有进程。我觉得这是一种“肮脏”的代码,但我无法想出任何其他的解决方案
- ,我确实有几个类,在这些类中,我将数据集作为参数注入,以便该数据集在类内的所有方法中充当引用。但是所有的方法实际上都是“特定的”,例如:
公共类CurrencyService {私有最终数据集currencyReference;//构造函数公共数据集applyCurrencyConversion(Dataset targetDataset){ //目标联接引用并应用转换}私有列转换(列targetColumn){ //转换规则} }
- 我该如何处理连接键?每个数据集的ID都有不同的名称。我正在考虑在预处理步骤中从每个ID的常量中强制一个键字符串。否则,我必须手动加入每个数据集,每次都知道它们的列名。使用预处理的连接键,我可能会执行类似于
dsA.join(dsB, Sequence of (joinKeys)).
的操作
最后,我觉得我在更多地使用代码,而以前的“单类”样式更容易理解,但不容易维护.
我有“公安条例”的背景,所以这个项目太面向对象了吗?
回答 1
Stack Overflow用户
发布于 2021-10-28 14:18:37
这是一个非常广泛和令人印象深刻的问题:) --我希望开发人员在启动项目时具备这样的成熟度。
管道
您正在构建管道,我建议您遵循以下命令:
- Ingest (read) data
- 应用数据质量规则(确保数据正常)
- 转换数据(将其形状按您需要的方式)
- 执行连接
<代码>H19将数据保存为检查点/最终结果<代码>H 210<代码>G 211
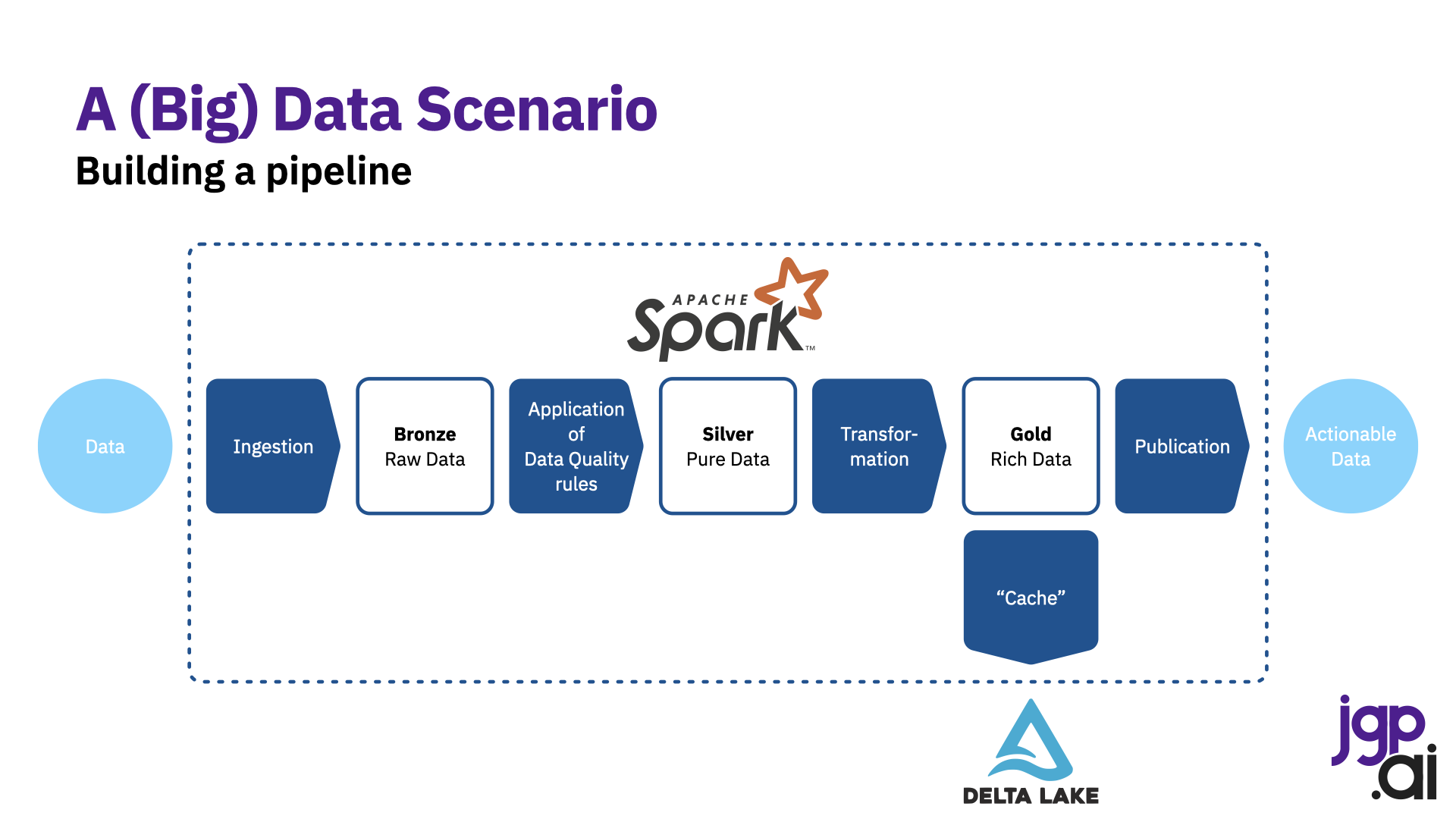
如果遵循此关系图,则不应在“黄金区域”之后应用规则,除非您处理特定的子项目。
转换
对于组织转换,静态函数是非常好的,特别是在继承现有的(工作?)项目。对于未来的规则或项目,我会有一些不同的想法(例如,您可以构建一个小规则引擎,其中将规则添加到列表中并立即执行)。
接合
对于连接,如果您有复杂的连接,您可以想象隔离它们,但是隔离id列的想法是好的:它更多地是元数据驱动的。在一些项目中,我创建了一个"SuperDataframe“对象,在该对象中,我可以向dataframe添加一些丢失的智能信息。您还可以向任何列添加自定义元数据,并让您的规则使用:签出https://github.com/jgperrin/net.jgp.labs.spark/blob/master/src/main/java/net/jgp/labs/spark/l090_metadata/l000_add_metadata/AddMetadataApp.java。看上去:
Metadata metadata = new MetadataBuilder()
.putString("x-source", filename)
.putString("x-format", format)
.putLong("x-order", i++)
.build();
df = df.withColumn(colName, col, metadata);一般意见
- 避免UDF:它们在催化剂(优化器)上花费很高,将它们视为黑匣子,因此无法优化它们。坚持星火的功能和possible.
- Stick一样多到dataframes (
Dataset<Row>),而不是用于性能optimization.
的数据集/RDD
你的轨道很好!
https://stackoverflow.com/questions/69752458
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号