
使用parsel选择器从动态web表中刮取数据
使用parsel选择器从动态web表中刮取数据
提问于 2021-10-26 06:59:48
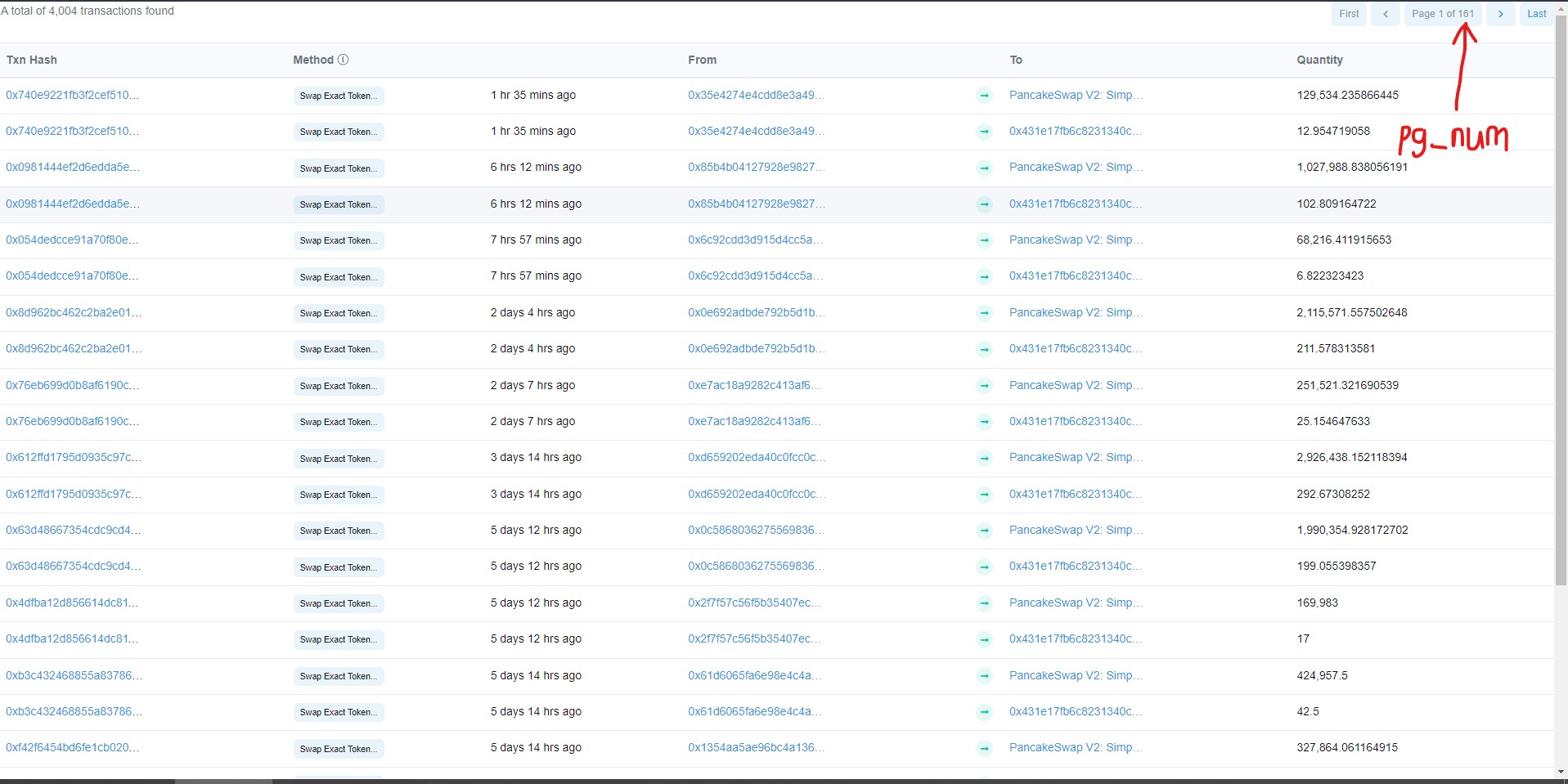
我正试图在“From”列中为任何令牌获取第一个事务的地址。由于经常会出现新的事务,因此使表变得动态,所以我希望能够在任何时候使用parsel选择器获取此信息。下面是我尝试的方法:
第一步:获取总页数
第二步:将该编号插入URL以获得最早的页码。
第三步:循环遍历“From”列并提取第一个地址。
它返回一个空列表。我找不出问题的根源。如有任何建议,将不胜感激。
from parsel import Selector
contract_address = "0x431e17fb6c8231340ce4c91d623e5f6d38282936"
pg_num_url = f"https://bscscan.com/token/generic-tokentxns2?contractAddress={contract_address}&mode=&sid=066c697ef6a537ed95ccec0084a464ec&m=normal&p=1"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"}
response = requests.get(pg_num_url, headers=headers)
sel = Selector(response.text)
pg_num = sel.xpath('//nav/ul/li[3]/span/strong[2]').get() # Attempting to extract page number
url = f"https://bscscan.com/token/generic-tokentxns2?contractAddress={contract_address}&mode=&sid=066c697ef6a537ed95ccec0084a464ec&m=normal&p={pg_num}" # page number inserted
response = requests.get(url, headers=headers)
sel = Selector(response.text)
addresses = []
for row in sel.css('tr'):
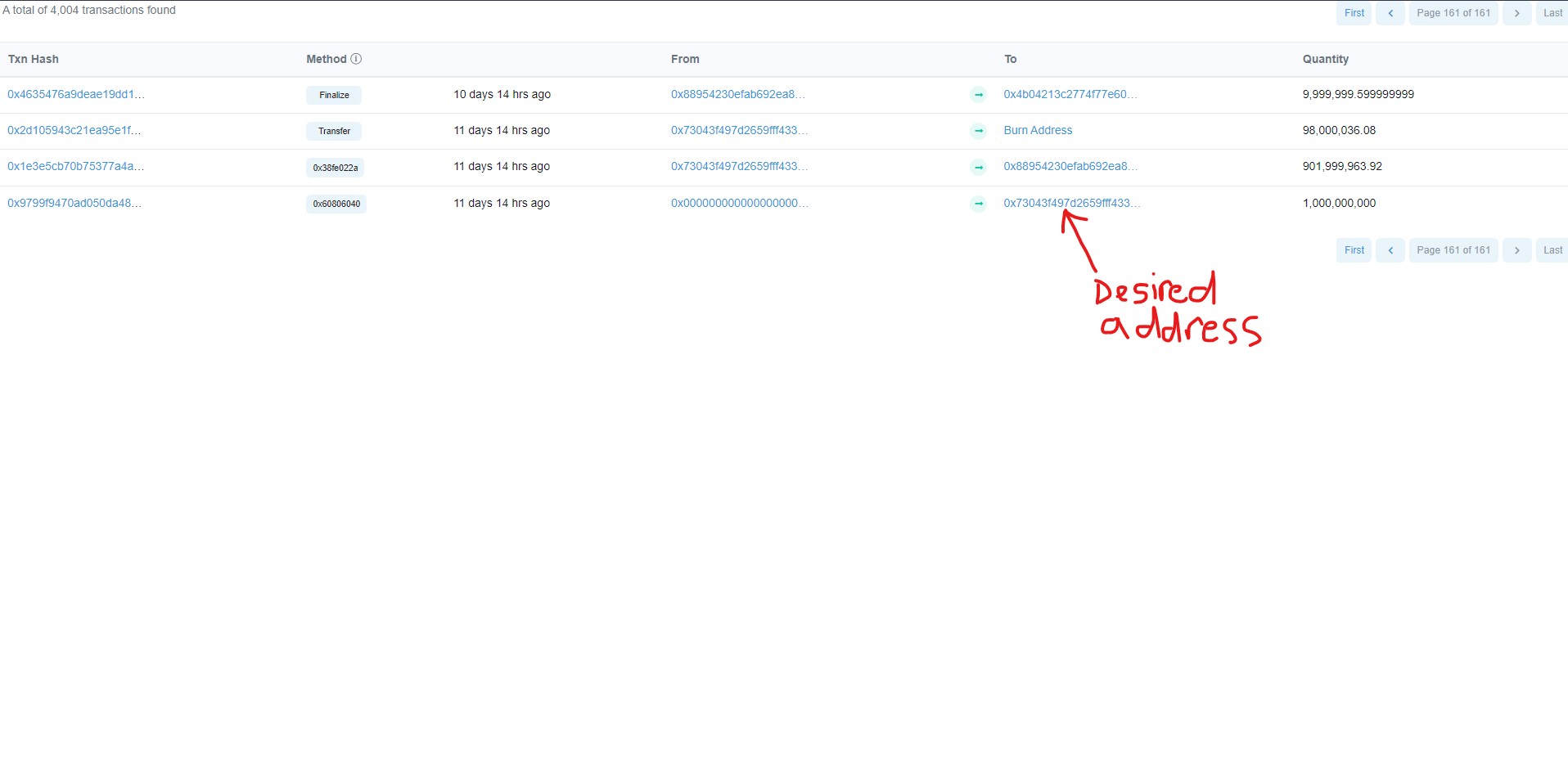
addr = row.xpath('td[5]//a/@href').re('/token/([^#?]+)')[0][45:]
addresses.append(addr)
print(addresses[-1]) # Desired address
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-10-26 11:47:14
似乎该网站正在使用服务器端会话跟踪和安全令牌,使抓取变得更加困难。
我们可以通过复制他们的行为来绕过这一切!
如果您查看web检查器,您可以看到,一旦我们第一次连接到该网站,就会向我们发送一些cookie:

此外,当我们在其中一个表上单击下一页时,会看到这些cookie被发送回服务器:

最后,表页的url包含名为sid的内容,它通常表示类似于security id的内容,可以在第1页的正文中找到。如果您检查页面源,您会发现它隐藏在javascript中:

现在我们需要把所有这些放在一起:
- 启动一个跟踪cookies
- 的请求
Session,转到令牌主页并接收cookies - ,在令牌主页
H 114中找到sid >使用cookies和sid令牌来刮表页H 216G 217
我修改了您的代码,结果如下所示:
import re
import requests
from parsel import Selector
contract_address = "0x431e17fb6c8231340ce4c91d623e5f6d38282936"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"
}
# we need to start a session to keep track of cookies
session = requests.session()
# first we make a request to homepage to pickup server-side session cookies
resp_homepage = session.get(
f"https://bscscan.com/token/{contract_address}", headers=headers
)
# in the homepage we also need to find security token that is hidden in html body
# we can do this with simple regex pattern:
security_id = re.findall("sid = '(.+?)'", resp_homepage.text)[0]
# once we have cookies and security token we can build the pagination url
pg_num_url = (
f"https://bscscan.com/token/generic-tokentxns2?"
f"contractAddress={contract_address}&mode=&sid={security_id}&m=normal&p=2"
)
# finally get the page response and scrape the data:
resp_pagination = session.get(pg_num_url, headers=headers)
addresses = []
for row in Selector(resp_pagination.text).css("tr"):
addr = row.xpath("td[5]//a/@href").get()
if addr:
addresses.append(addr)
print(addresses) # Desired address页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69718690
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号