
将相似的元素组合在一起
将相似的元素组合在一起
提问于 2021-08-27 03:55:13
我试图将相似的实体组合在一起,但找不到一种简单的方法。
例如,这里有一个表:
Names Initial_Group Final_Group
1 James,Gordon 6 A
2 James,Gordon 6 A
3 James,Gordon 6 A
4 James,Gordon 6 A
5 James,Gordon 6 A
6 James,Gordon 6 A
7 Amanda 1 A
8 Amanda 1 A
9 Amanda 1 A
10 Gordon,Amanda 5 A
11 Gordon,Amanda 5 A
12 Gordon,Amanda 5 A
13 Gordon,Amanda 5 A
14 Gordon,Amanda 5 A
15 Gordon,Amanda 5 A
16 Gordon,Amanda 5 A
17 Gordon,Amanda 5 A
18 Edward,Gordon,Amanda 4 A
19 Edward,Gordon,Amanda 4 A
20 Edward,Gordon,Amanda 4 A
21 Anna 2 B
22 Anna 2 B
23 Anna 2 B
24 Anna,Leonard 3 B
25 Anna,Leonard 3 B
26 Anna,Leonard 3 B我不知道如何在上表中得到'Final_Group‘字段。
为此,我需要分配与另一个元素有任何连接的任何元素,并将它们分组:
例如,
- 需要将第1行到第20行分组,因为它们都由至少一个或多个元素连接。
因此,对于第1行到第6行,出现了'James,Gordon‘,而且由于"Gordon“位于第10:20行,所以必须对它们进行分组。同样,由于‘阿曼达’出现在第7:9行,所以必须将其分组为"James,Gordon","Gordon,Amanda“和"Edward,Gordon,Amanda”。
下面是生成初始数据的代码:
# Manually generating data
Names <- c(rep('James,Gordon',6)
,rep('Amanda',3)
,rep('Gordon,Amanda',8)
,rep('Edward,Gordon,Amanda',3)
,rep('Anna',3)
,rep('Anna,Leonard',3))
Initial_Group <- rep(1:6,c(6,3,8,3,3,3))
Final_Group <- rep(c('A','B'),c(20,6))
data <- data.frame(Names,Initial_Group,Final_Group)
# Grouping
data %>%
select(Names) %>%
mutate(Initial_Group=group_indices(.,Names))有没有人知道在R区做这件事?
回答 2
Stack Overflow用户
回答已采纳
发布于 2021-08-27 05:04:19
这是一个很长的过程,但你可以做到:
library(tidyverse)
library(igraph)
df %>%
select(Names)%>%
distinct() %>%
separate(Names, c('first', 'second'), extra = 'merge', fill = 'right')%>%
separate_rows(second) %>%
mutate(second = coalesce(second, as.character(cumsum(is.na(second)))))%>%
graph_from_data_frame()%>%
components()%>%
getElement('membership')%>%
imap(~str_detect(df$Names, .y)*.x) %>%
invoke(pmax, .)%>%
cbind(df, value = LETTERS[.], value1 = .)
Names Initial_Group Final_Group value value1
1 James,Gordon 6 A A 1
2 James,Gordon 6 A A 1
3 James,Gordon 6 A A 1
4 James,Gordon 6 A A 1
5 James,Gordon 6 A A 1
6 James,Gordon 6 A A 1
7 Amanda 1 A A 1
8 Amanda 1 A A 1
9 Amanda 1 A A 1
10 Gordon,Amanda 5 A A 1
11 Gordon,Amanda 5 A A 1
12 Gordon,Amanda 5 A A 1
13 Gordon,Amanda 5 A A 1
14 Gordon,Amanda 5 A A 1
15 Gordon,Amanda 5 A A 1
16 Gordon,Amanda 5 A A 1
17 Gordon,Amanda 5 A A 1
18 Edward,Gordon,Amanda 4 A A 1
19 Edward,Gordon,Amanda 4 A A 1
20 Edward,Gordon,Amanda 4 A A 1
21 Anna 2 B B 2
22 Anna 2 B B 2
23 Anna 2 B B 2
24 Anna,Leonard 3 B B 2
25 Anna,Leonard 3 B B 2
26 Anna,Leonard 3 B B 2检查名为value的列
Stack Overflow用户
发布于 2021-08-27 04:37:50
我错了,我误解了你对Final_Group的关注。如果没有,请告诉我,我的方法是基于样本之间的距离。
data <- data %>%
mutate(Names = sapply(Names, function(x) as.vector(str_split(x, ","))))
for (i in c(1:26)){
data$James[i] = ("James" %in% data$Names[[i]])
data$Gordon[i] = ("Gordon" %in% data$Names[[i]])
data$Amanda[i] = ("Amanda" %in% data$Names[[i]])
data$Edward[i] = ("Edward" %in% data$Names[[i]])
data$Anna[i] = ("Anna" %in% data$Names[[i]])
dummy$Leonard[i] = ("Leonard" %in% dummy$Names[[i]])
}
hc <- data%>% select(-Names,) %>%
select(-Final_Group, -Initial_Group ) %>%
dist() %>% hclust(.,method = "complete")
cutree(hc)
[1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2
plot(hc)
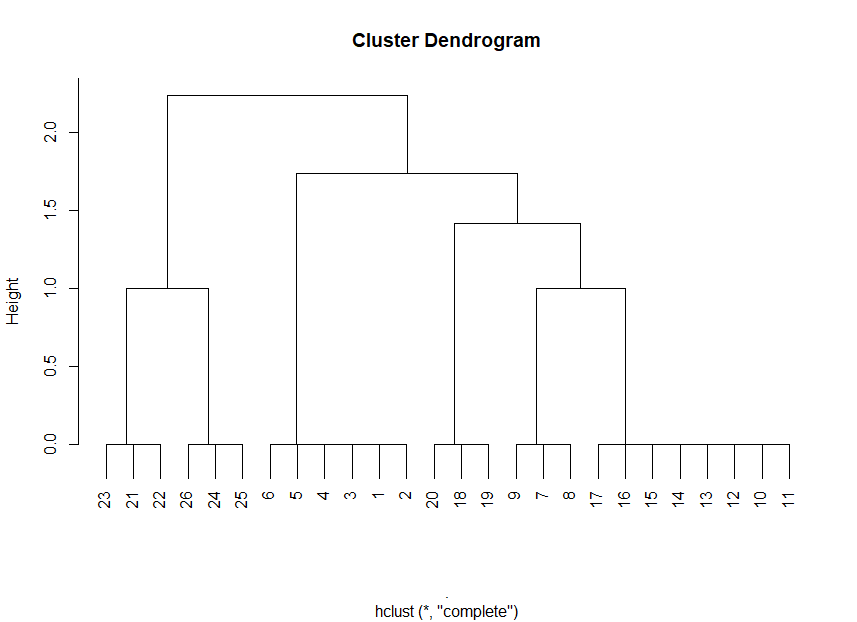
这和Final_Group很相似
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68947862
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号